







摘要、背景、贡献
摘要

背景
大背景:
使用GPU加速实现的ANN模型需要消耗大量的能量。主要是传统神经模型中采用的是MAC乘加操作。
小背景:
- CIM直接从内存中读取权重执行MAC操作。但是需要使用大量的数模转换器和模数转换器(ADC),这样降低性能。过程为:人工网络数字权重转化为模拟信号,控制存储单元的位线和字线与模拟信号产生响应,然后每个RBL使用模数转换器将模拟信号转换为数字结果。
- SNN本质上是模拟的,因此ACIM技术非常适合SNN的实现。ACIM技术可以在模拟域中直接处理SNN的信号,不需要数据转换器。SNN中,信号脉冲可以直接在SRAM中进行传输,大大的简化了复杂的连接,降低了传输信号的功耗和复杂性。SNN中的神经元只在接收到输入脉冲时才会激活。这种事件驱动的特性消除了对传统ANN中空输入(null inputs)的计算需求,从而节省了计算资源。
贡献
- 首次设计出一种SNN IC来处理TTFS信号
- 设计出一个低功耗的ACIM实现了SOLIF神经元模型用于处理TTFS信号
- 提出一种低功耗、紧凑的全数字尖峰转换器(DTS),将数字转换为相应的TTFS信号
- 提出一种紧凑的、低漏电8晶体管SRAM段元
- 首次成功使用TTFS信号演示了SNN IC的推理结果
TTFS信号是指神经元接收到输入刺激后,首次发放脉冲的时间。通过记录这个时间,可以量化输入刺激的强度或时间信息。时间越早,表示刺激越强或越紧急;时间越晚,表示刺激越弱或越不紧急。
SNN IC是一种SNN集成电路,旨在实现脉冲神经网络的功能。
SNN模型
如图一所示,本文模型由三个卷积层和三个全连接层组成。全连接层中的所有信号都采用TTFS编码。所有的神经元都是用相同的SNN神经元,相比于ANN,FC层中的神经元数量较少,这是由于本文重点是为了验证SNN IC处理TTFS编码的可行性,而不是追求模型性能。
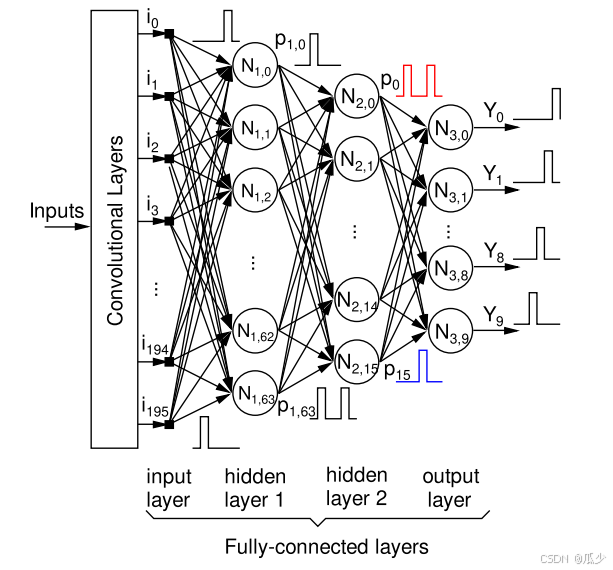
图1:SNN模型框架
尖峰信号编码方案
速率编码:如图二所示,使用一个周期内的尖峰数来表示信号的值。
优点:快捷的从传统的数字人工神经网络转化为SNN,很好的利用现在已有的技术。
缺点:
- 尖峰信号的分辨率取决于一个周期内TS的最大尖峰数量。更高的分辨率就需要更多的尖峰来表示信号,增加了功耗。
- 尖峰的触发时刻与信号无关。
神经元的物理延迟不能小于一个周期。
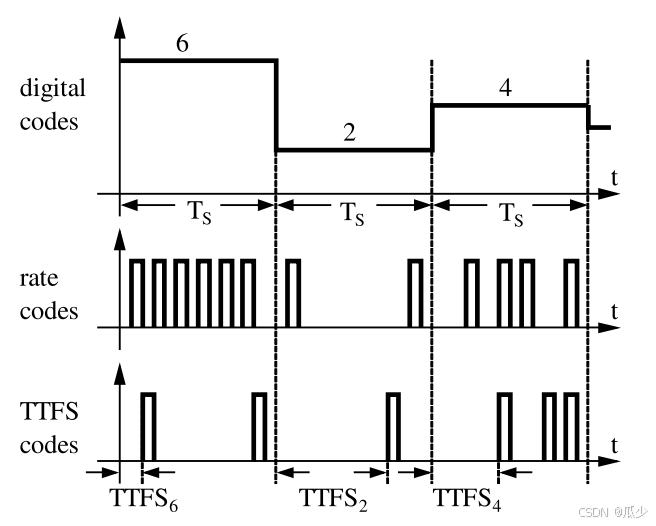
图2:举例说明模型信号不同编码方式
TTFS编码:使用一个周期中脉冲信号到达的时间来表示信号的值。第一个尖峰出现的时间越早,信号就越大。
与速率编码相比,TTFS优势:
- 理论上,TTFS所表示的信号分辨率是无限的。在设计中通常采用低分辨率的ADC来节省硬件成本,从而导致速率编码会带来显著的量化误差。
- 采用TTFS编码大大降低了尖峰数,有助于减少能量消耗
- 只有第一个尖峰信号携带信息,计算延迟低
因此,本文采用TTFS编码方式。
神经元模型
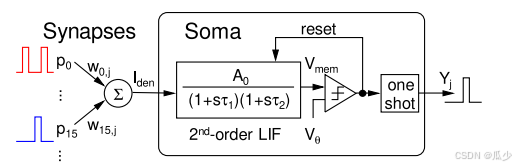
图3:SOLIF神经元行为模型
本文采用SOLIF神经元模型,如图三所示。SOLIF神经元将每个尖峰输入与相应的突触二值权重
相乘。然后将结果输入到Soma(二阶泄露积分器)中处理,传递函数为:
其中和
是两个实极频率,
表示直流增益(输入信号转化为输出信号的比例),
为拉普拉斯变换中的复数频率变量,衰减波的时间常数分别为
和
。神经元的脉冲相应可以用传递函数推导出,表现为两个指数衰减波的差值。
在控制系统中,直流增益反映了系统对恒定输入信号(即直流信号)的放大或衰减能力。
- 放大:如果
,系统会对直流信号产生放大效果。
- 衰减:如果
,系统会对直流信号产生衰减效果。
- 单位增益:如果
,系统的输出与输入信号的幅度相同,表示没有放大或衰减。
如图四所示,输入尖峰信号后使得SOLIF神经元Vmem逐渐增加到峰值,然后平稳下降到零,当输入几个连续的尖峰使Vmem高于阈值后释放脉冲并立即重置膜电位。
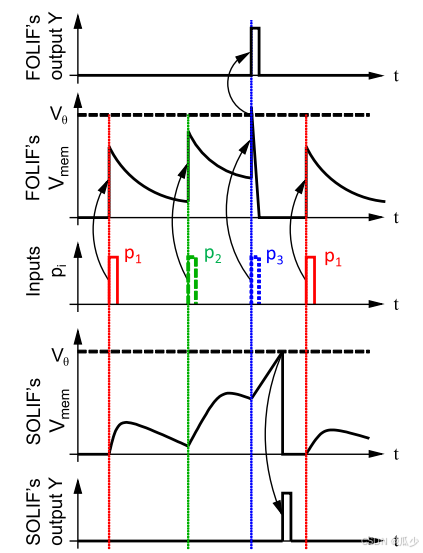
与FOLIF神经元相比,SOLIF神经元具有以下优势:
- 更出色的学习能力(根据以往实验以及论文验证得出的结果);
- 更好的信号分辨率,当输入尖峰来临时,FOLIF神经元的Vmem就会跳跃,使得输出的时间分辨率和输入的时间分辨率相同。而SOLIF神经元在是逐渐上升到峰值的,每一层输出时间的分辨率都高于输入时间的分辨率。增加时序分辨率有助于提高SNN的性能。
电路实现
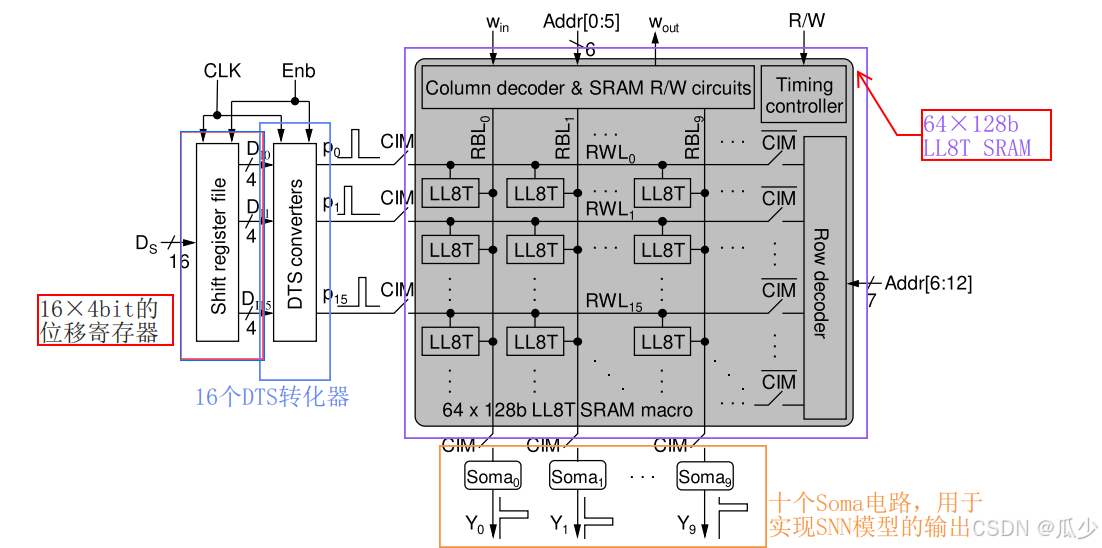
图5:ACIM SNN框架图
上图为本文所提出的ACIM SNN框架图,采用器件及相关功能如下:
- 16 × 4 bit 移位寄存器文件:通常用于存储和处理数据,在脉冲神经网络中,这些寄存器可用于临时存储和处理输入或中间计算结果。
- 16个DTS转换器:DTS转换器负责将数字信号转换为脉冲信号,将输入的数字数据转换为适合SNN处理的脉冲序列。
- 64 × 128 b LL8T SRAM:用于存储权重、网络的中间状态。
- 10个神经元电路:实现SNN的输出层。
该设计支持两种模式,CIM模式和SRAM模式。
本文利用MNSIT数据集对SNN模型进行训练,获得最后一个隐藏层和输出层之间的二进制权重和TTFS尖峰信号。采用训练后量化(PQT)方法将突触权重化为二值。控制CIM=0,使用SRAM模式来将二进制权重写入LL8T存储器。最后一个隐藏层输出处的模拟尖峰信号被截断为4为的数字数据。并将控制信号Enb设置为1串行加载到位移寄存器文件中。
然后将CIM切换为1,Enb切换为0,在CIM模式下进行推理。DTS会将16个4位数据转化为16个TTFS尖峰信号
,作为LL8T SRAM的16个指定输入RWLs(行字线的输入),其余RWLs接地。当脉冲信号出现在RWL上时,存储权重
为1的同一行的每一个LL8T单元都会在与该LL8T单元相连的RBL上产生电流脉冲。然后再RBL上进行汇总相加,将相加后的信号
输入到神经元细胞Soma里,并产生他们的模拟输出。
数字脉冲转换器
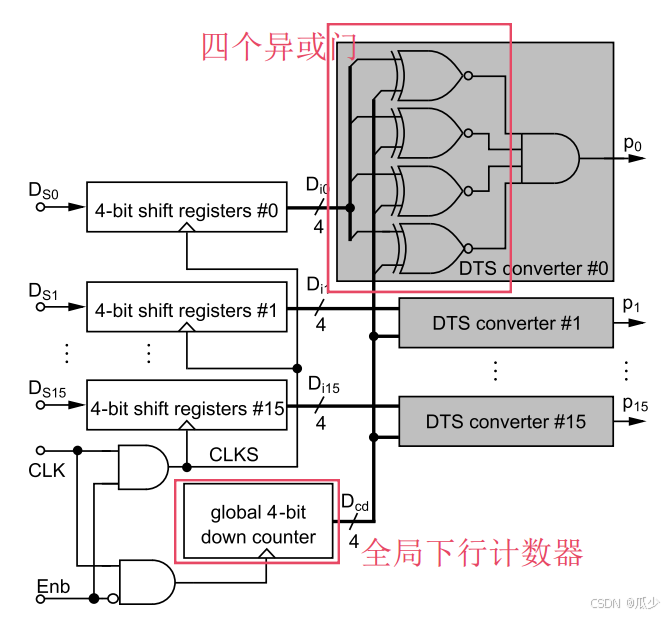
图6:本文所提出的DTS全数字转换器
TTFS信号在片内产生,避免信号走线产生的时序倾斜。本文提出一种数字DTS转换器,将输入信号转化为TTFS尖峰信号。如图六所示,每个转化器由四个异或门和一个与门组成。16个DTS转化器共享一个全局下行计数器,并在16个RWLs上生成TTFS信号。首先Enb信号设置为1,所有16个四位串行输入数据DSi被串行加载到16个4为寄存器中。然后,Enb信号切换为0,同时全局下行计数器会从15倒计时为0,将16个数据与全局4位下行计数器的输出Dcd进行比较。如果
=
,则会产生一个尖峰信号
,作为LL8T SRAM的第i个输入。若尖峰信号
为0,则禁止使用相应的RWL。
DTS转换器具有紧凑、低功耗以及具有很好的鲁棒性。它只有两个门的延迟,确保输出尖峰pi的高精度。尽管DTS转换器的输入是4位,但细胞体的输出脉冲由于SOLIF神经元模型和TTFS信号传递方式而有更高的时序分辨率。硬件成本仅与输入DIi的位数成正比。此外,DTS转换器仅在多层SNN的初始输入时需要。
利用ACIM技术实现神经元
图七所描绘的是SNN神经元的完整电路图,由一个二阶泄露积分器、一个延迟缓冲器、一个比较器和一个复位开关组成。
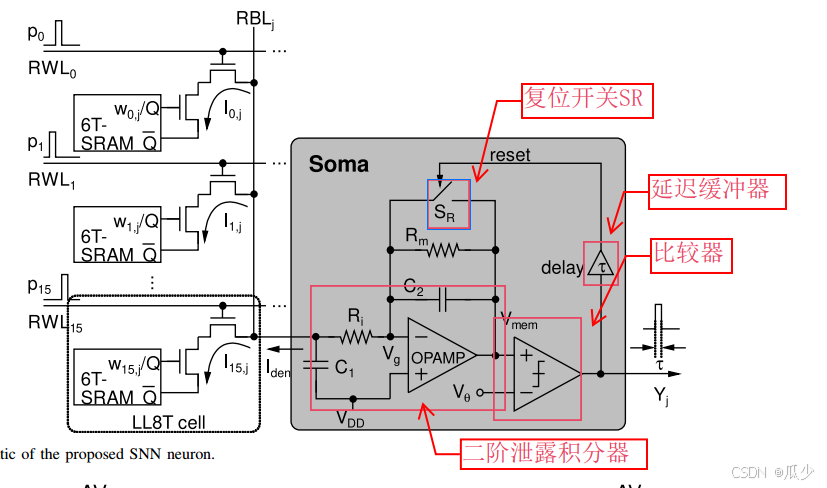
图7:SNN神经元的电路原理图
细胞体需要使用(1)式中的传递函数来推导得到膜电位,实际上,(1)式是二阶滤波器的传递函数。传统的双二阶滤波器(例如:Tow-Thomas和Kerwin-Huelsman)至少需要两个OPAMP(运算放大器)来实现二阶泄露积分器。本文只使用了一个运算放大器来实现二阶泄露积分器,还使用了两个电阻和两个电容。泄露积分器的传递函数为:
与(1)相比,,
,
。根据本文的SNN模型,
f分别设置为4.14和0.795 MHZ,两个电容为500 fF。电阻
和
分别为192kΩ和1MΩ。这两个电阻均通过图8中所示的体漏连接的浮动CMOS电阻方案实现,以节省面积。
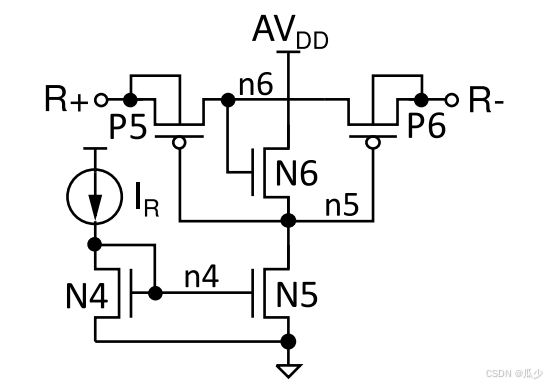
图8:本体漏极连接的浮动CMOS电阻原理图
A. Tajalli, Y. Leblebici, and E. J. Brauer, “Implementing ultra-highvalue floating tunable CMOS resistors,” Electron. Lett., vol. 44, no. 5,pp. 349–351, 2008.
OPAMP
本文所采用的是一个传统的两级差分到单端的放大器(two-stage differential-to-single-ended amplifier),如图所示,输入的是一对pMOS对,来减少相关噪声。适当调整P1和P2的尺寸来降低功耗,使得他们的反演条件接近为1,即在饱和区域的亚阈值区域工作。晶体管NR在三极管区工作,其余的晶体管偏置在强反演区工作,以提高PVT(电源电压、工艺和温度)的敏感性。仿真结果显示,运算放大器通常实现了54 dB的开环增益,65 MHz的单位增益带宽,以及在额定负载下的65度的相位裕度。
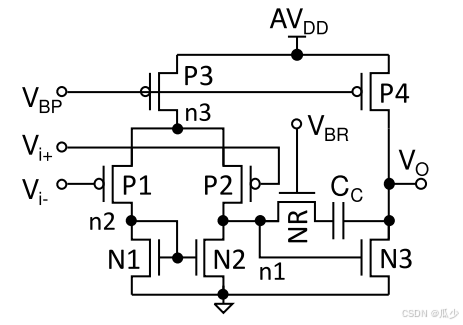
图9:OPAMP原理图
晶体管的栅极电压与阈值电压之间的关系:
- 强反演区:当栅极电压远低于阈值电压(V_tp)时,PMOS管完全导通,电流最大。
- 弱反演区:当栅极电压略高于阈值电压时,PMOS管开始导通,但电流非常小。
- 中等反演区:当栅极电压接近阈值电压时,PMOS管处于电流和电压的中间状态。
- 亚阈值区:此时晶体管开始导通,但电流非常小。
MOSFET的三个主要工作区域:
- 截止区(Cut-off Region):当栅极电压低于阈值电压时,晶体管不导通,输出电流几乎为零。
- 三极管区(Triode Region):当栅极电压高于阈值电压,并且源极与漏极之间的电压较低时,晶体管表现为一个可变电阻。此时,电流随着源漏电压的变化而线性变化。
- 饱和区(Saturation Region):当栅极电压高于阈值电压,并且源极与漏极之间的电压超过一定值时,晶体管的输出电流基本上不再随源漏电压的变化而变化,而是主要取决于栅极电压。
图10中所示的连续时间比较器是一个简单的两级放大器,没有频率响应补偿。其输入差分对是nMOS对,以加快比较速度。
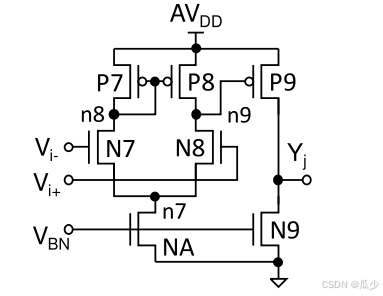
图10:比较器电路图
低漏8-T SRAM单元(Low-Leakage 8-T SRAM Cell)
传统的SRAM的读写操作都是通过BL\BLB进行的,具有较小的读取静态噪声余量(RSNM)。但是较小的RSNM容易受到读取干扰,尤其实在CIM模式下,同一个BL上可能同时读取多个SRAM单元的信号。本文所提出的SRAM可以有效解决这一问题,如图10(a)所示,在传统的SRAM基础上添加一个级联编码NMOS端口和一个专门用于读取数据的RBL。同时保留BL\BLB仅用于写操作。这一操作使得读取过程不在影响存储在SRAM中的数据,并且实现了更大的RSNM。
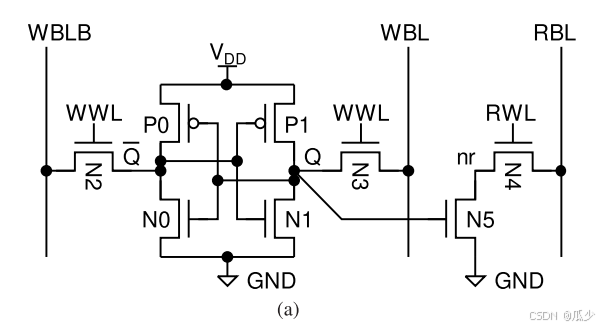
图10(a):RD8T SRAM cell
当输入的尖峰激活RWL,Q=1时,该SRAM模块会为RBL贡献电流。当Q=0时,此时也会引入一些泄露电流。这些泄露电流会导致膜电位的最终结果出现误差。
补充:当Q=0时,N5理论上是处于断开状态,但是由于物理技术的限制,才会导致泄露电流的存在。
NMOS在亚阈值泄露电流可以表示为:
其中,,
和
分别为
和
时的亚阈值斜率、热电压和泄露电流。RD8T单元有着较大的输出摆幅,但是当Q=0且RWL=1时,因为晶体管 N5 的
为0,
,可能在先进的工艺中导致较大的读漏电流
。为了简化下面的讨论,让我们忽略体效应,假设所有晶体管都具有相同的尺寸。
本文提出一种紧凑的LL8T SRAM单元,可以有效缓解读漏电流的问题。两者都使用一个级联编码的NMOS读取端口,实现无读取干扰。RD8T和LL8T单元之间的唯一区别是RD8T单元将读端集体管N5的源端连接到地,而LL8D单元将其连接到Q'。如图11(e)所示:
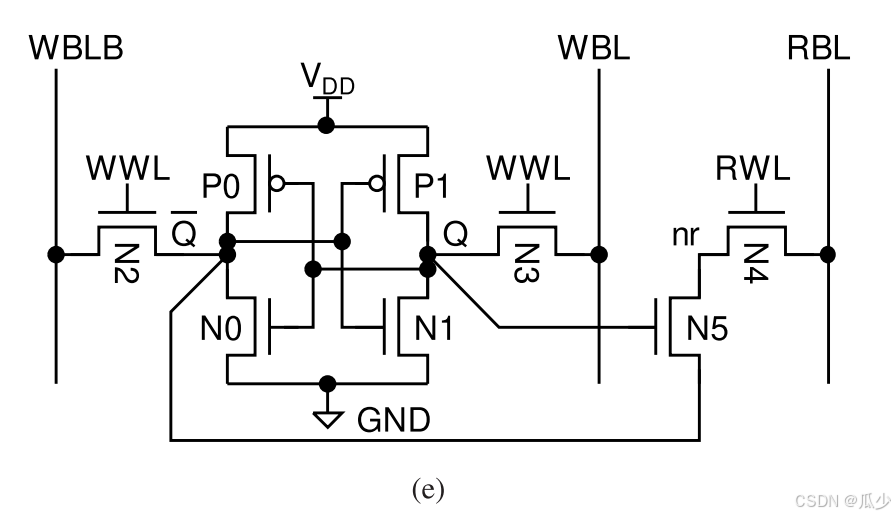
图11(e):LL8T SRAM cell
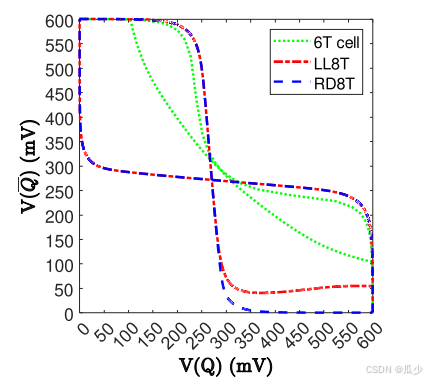
图13:模拟VDD = 0.6 V时6T、LL8T和RD8T细胞的RSNMs
- SRAM工作模式下:图13比较了6T、RD8T和LL8T电池在VDD为0.6 V时SRAM模式下的蝴蝶曲线。LL8T电池的RSNM为194 mV,接近RD8T电池的226 mV RSNM,远优于传统6T电池的72.2 mV RSNM。这个大的RSNM允许LL8T单元在低VDD下工作。模拟假设每个RWL有64个单元,每个RBL有128个单元。在适用于实现CIM突触的四种SRAM单元中,所提出的LL8T单元的漏电流最小。LL8T电池功耗最低,接入时间较长。表1总结并比较了RD8T、10T、两个9T和所提出的LL8T SRAM单元在VDD为0.6 V时的预布局仿真结果。当Q = 1和RWL = 1时,由于RBL的输出摆幅有限,CIM操作更倾向于选择工作电流较小的单元。所提出的LL8T电池以最少的晶体管提供最小的工作电流。
- CIM工作模式下:当Q=1,RWL=1时,电流源工作在饱和区,神经元中的OPAMP将RBL的电压初始化为VDD。由于晶体管N4工作在饱和区,源极电压
与漏极电压
无关,只需要V(RBL)>
,N4就可以稳定在饱和区工作。其中
是N4的阈值电压。同时,晶体管N5和N0作为N4的串联源极退化电阻以及电阻分压器,工作在三极管区,这使得节点Q的电压V(Q)不超过V(nr)的一半。LL8T单元的Q只有在V(Q)高于由N1和P1构成的反相器的阈值电压(271 mV)时才会翻转。在这种情况下,V(Q)不足以翻转Q,因为V(Q) < V(nr)/2,而V(nr) = VDD − VGSN4,其值较低。
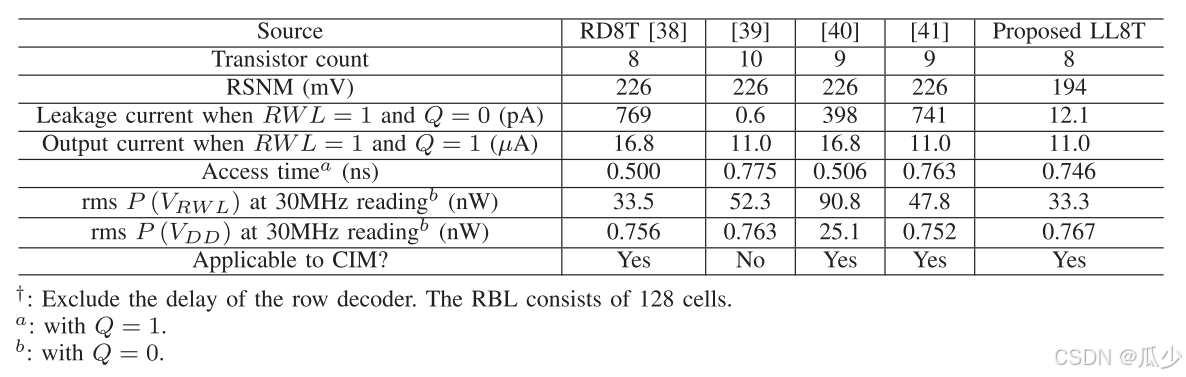
表1:在VDD = 0.6 v时,SRAM单元在读取操作期间的性能总结


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









