







 本文详细介绍了Java8的StreamAPI,包括Stream的基本概念、创建方式、中间操作、终止操作以及常见使用示例。StreamAPI使得在Java中进行函数式编程变得更加简单,能对集合数据进行高效处理,支持并行操作。文章通过实例展示了如何使用filter、map、reduce等方法进行数据筛选、转换和归约,以及如何通过collect方法进行数据收集。
本文详细介绍了Java8的StreamAPI,包括Stream的基本概念、创建方式、中间操作、终止操作以及常见使用示例。StreamAPI使得在Java中进行函数式编程变得更加简单,能对集合数据进行高效处理,支持并行操作。文章通过实例展示了如何使用filter、map、reduce等方法进行数据筛选、转换和归约,以及如何通过collect方法进行数据收集。
1. 概述
- Stream API把真正的函数式编程风格引入到Java中,使用Stream API可以极大提高效率,写出更加简洁、干净、高效的代码。Stream API时Java8中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。使用Stream API可以对集合数据进行操作,就类似于使用SQL执行的数据库查询。也可以使用Stream API来并行执行操作。简言之,Stream API提供了一种高效且易于使用的处理数据的方式
- Stream和Collection集合的区别:Collection是一种静态的内存数据结构,而Stream是有关计算的。前者是主要面向内存,存储在内存中,后者主要是面向CPU,通过CPU实现计算
2. 什么是Stream?
- 是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。”集合讲的是数据,Stream讲的是计算“
- 注意
- Stream自己不会存储元素
- Stream不会改变源对象。相反,他们会返回一个持有结果的新Stream
- Stream操作是延迟执行的。这意味着它们会等到需要结果的时候才执行
3. Stream操作的三个步骤?
- 创建Stream:一个数据源(如:集合、数组),获取一个流
- 中间操作:一个中间操作链,对数据源的数据进行处理
- 终止操作(终端操作):一旦执行终止操作,就执行中间操作链,并产生结果。之后,不会再被使用
4. 创建Stream的几种方式
- 方式一:通过集合
Java8中的Collection接口被扩展,提供了两个获取流的方法:
- default Stream<E> stream(): 返回一个顺序流
- default Stream<E> parallelStream(): 返回一个并行流
- 方式二:通过数组
Java8中的Arrays的静态方法stream()可以获取数组流:
- static<T> Stream<T> stream(T[] array): 返回一个流
重载形式,能够处理对应基本类型的数组
- public static IntStream stream(int[] array)
- public static LongStream stream(long[] array)
- public static DoubleStream stream(double[] array)
- 方式三:通过Stream的of()
可以调用Stream类静态方法of(),通过显示值创建一个流。它可以接受任意数量的参数。\
- public static <T> Stream<T> of(T...values):返回一个流
- 方式四:创建无限流(不常用)
5. 创建Stream代码示例
package Java8;
import org.junit.Test;
import java.util.Arrays;
import java.util.List;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class StreamAPITest1 {
// 创建Stream方式一: 通过集合
@Test
public void test1() {
List<Employee> employees = EmployeeData.getEmployees();
// 返回一个顺序流
Stream<Employee> stream = employees.stream();
// 返回一个并行流
Stream<Employee> parallelStream = employees.parallelStream();
}
// 创建Stream方式二: 通过数组
@Test
public void test2() {
int[] arr = {1, 2, 3, 4, 5, 6};
// 调用Arrays类的static <T> Stream<T> stream(T[] array)
IntStream stream = Arrays.stream(arr);
Employee e1 = new Employee(1001, "Tom");
Employee e2 = new Employee(1002, "Jerry");
Employee[] arr1 = {e1, e2};
Stream<Employee> stream1 = Arrays.stream(arr1);
}
// 创建Stream方式三: 通过Stream的of
@Test
public void test3() {
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);
}
// 床创建Stream方式四: 创建无限流(不常用 )
@Test
public void test4() {
// 迭代
// public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)
// 遍历前10个偶数
Stream.iterate(0, t -> t + 2).limit(10).forEach(System.out::println);
// 生成
// public static<T> Stream<T> generate(Supplier<T> s)
Stream.generate(Math::random).limit(10).forEach(System.out::println);
}
}
6. Stream的中间操作
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则
中间操作不会执行任何的处理。而在终止操作时一次性全部处理,称为”惰性求值“
- 筛选与切片
- 常用方法
| 方法 | 描述 |
|---|---|
| filter(Predicate p) | 接收lambda,从流中排除某些元素 |
| distinct() | 筛选,通过流所生成元素的hashCode()和equals()去除重复元素 |
| limit(long maxSize) | 截断流,使其元素不超过给定数量 |
| skip(long n) | 跳过元素,返回一个扔掉了前n个元素的流。若流中元素不足n个,则返回一个空流。与limit(n)互补 |
- 代码示例
package Java8;
import org.junit.Test;
import java.util.List;
/**
* 测试Stream中间操作
*/
public class StreamAPITest2 {
// 筛选与切片
@Test
public void test1() {
List<Employee> list = EmployeeData.getEmployees();
System.out.println("------filter------");
// 从EmployeeData中过滤出薪资大于7000的员工信息
list.stream().filter(employee -> employee.getSalary() > 7000).forEach(System.out::println);
System.out.println("------limit------");
// 取出前三个员工信息
list.stream().limit(3).forEach(System.out::println);
System.out.println("------skip------");
// 跳过前三个
list.stream().skip(3).forEach(System.out::println);
System.out.println("------distinct------");
// 添加重复数据
list.add(new Employee(1010, "刘强东", 40, 8000));
list.add(new Employee(1010, "刘强东", 40, 8000));
list.add(new Employee(1010, "刘强东", 40, 8000));
list.add(new Employee(1010, "刘强东", 40, 8000));
list.add(new Employee(1010, "刘强东", 41, 8000));
// 去除重复元素
list.stream().distinct().forEach(System.out::println);
}
}
运行结果
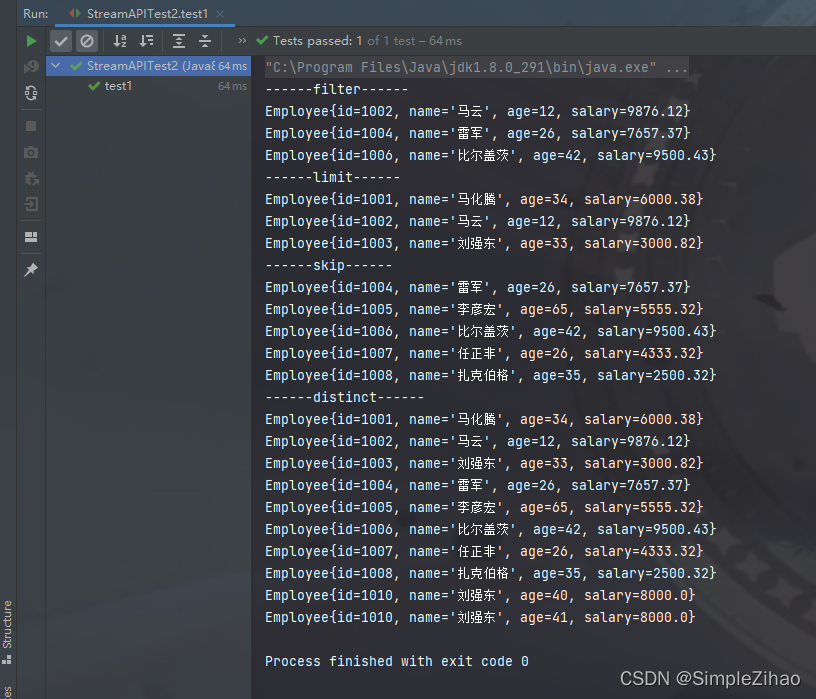
- 映射
- 常用方法
| 方法 | 描述 |
|---|---|
| map(Function f) | 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素 |
| map ToDouble(ToDoubleFunction f) | 接受一个函数作为参数,该函数会被应用到每个元素上,产生一个新的DoubleStream |
| map ToInt(ToIntFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的LongStream |
| flatMap(Function f) | 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流 |
- 代码示例
// 映射
@Test
public void test2() {
// map
List<String> list = Arrays.asList("aa", "bb", "cc", "dd");
list.stream().map(String::toUpperCase).forEach(System.out::println);
// 练习1.获取员工姓名长度大于3的员工姓名
List<Employee> employees = EmployeeData.getEmployees();
Stream<String> namesStream = employees.stream().map(Employee::getName);
namesStream.filter(name -> name.length() > 3).forEach(System.out::println);
// 练习2. 遍历list集合中每一个元素
System.out.println();
System.out.println("------普通map实现------");
Stream<Stream<Character>> streamStream = list.stream().map(StreamAPITest2::fromStringToStream);
streamStream.forEach(s -> {
s.forEach(System.out::println);
});
System.out.println("------flatMap实现------");
list.stream().flatMap(StreamAPITest2::fromStringToStream).forEach(System.out::println);
}
// 将字符串中的多个字符构成的集合转换为对应的Stream的实例
public static Stream<Character> fromStringToStream(String str) {
ArrayList<Character> list = new ArrayList<>();
for (Character c : str.toCharArray()) {
list.add(c);
}
return list.stream();
}
运行结果
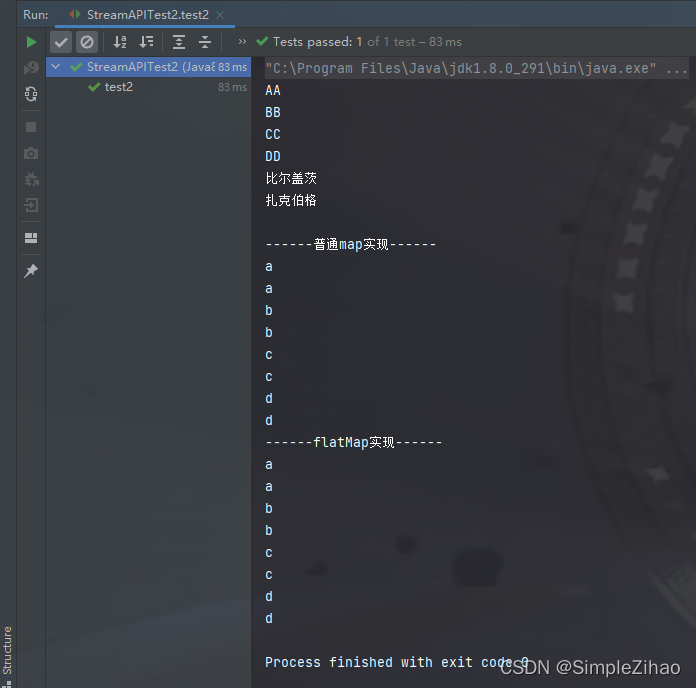
- 排序
- 常用方法
| 方法 | 描述 |
|---|---|
| sorted() | 产生一个新流,其中按自然顺序排序 |
| sorted(Comparator com) | 产生一个新流,其中按比较器顺序排序 |
- 代码示例
// 排序
@Test
public void test3() {
// sorted()---自然排序
List<Integer> list = Arrays.asList(12, 43, 65, 34, 87, 0, -98, 7);
list.stream().sorted().forEach(System.out::println);
// sorted(Comparator com)-- 定制排序
List<Employee> employees = EmployeeData.getEmployees();
employees.stream().sorted((e1, e2) -> {
int ageValue = Integer.compare(e1.getAge(), e2.getAge());
if (ageValue != 0) {
return ageValue;
} else {
return Double.compare(e1.getSalary(), e2.getSalary());
}
}).forEach(System.out::println);
}
运行结果
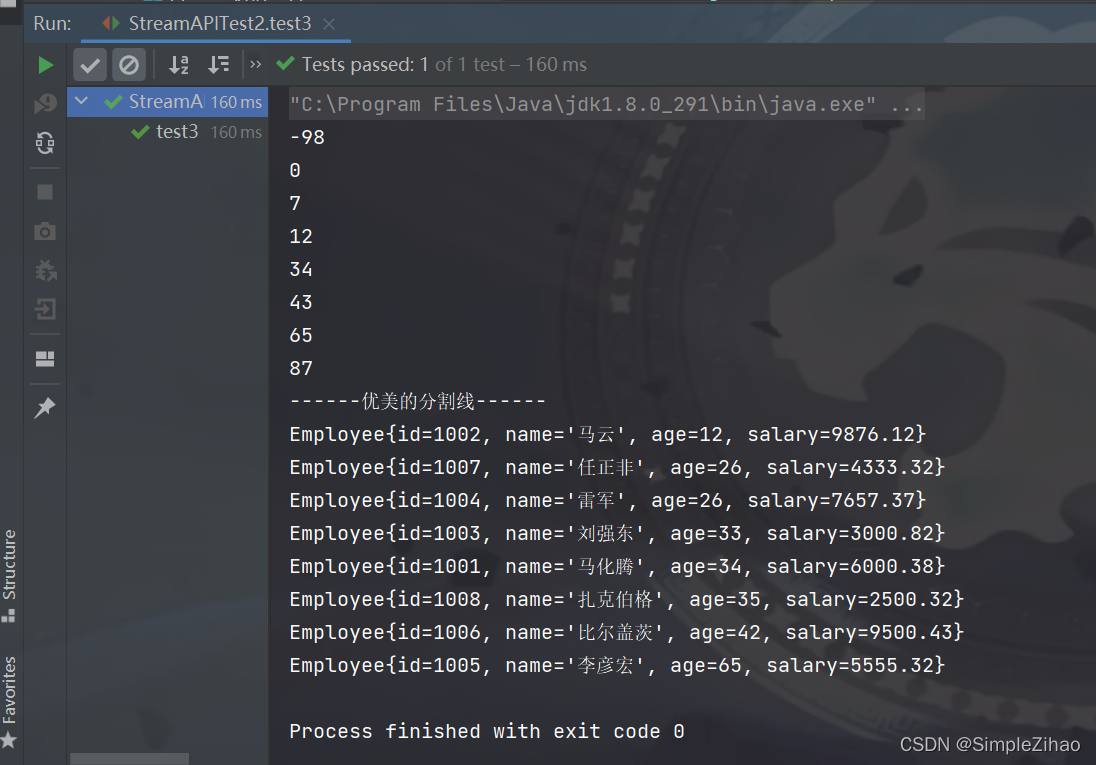
7. Stream的终止操作
- 终止操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是void
- 流进行了终止操作后,不能再次使用
- 匹配与查找
| 方法 | 描述 |
|---|---|
| addMatch(Predicate p) | 检查是否匹配所有元素 |
| anyMatch(Predicate p) | 检查是否至少匹配一个元素 |
| noneMatch(Predicate p) | 检查是否没有匹配所有元素 |
| findFirst() | 返回第一个元素 |
| findAny() | 返回当前流中的任意元素 |
| cout() | 返回流中元素总数 |
| max(Comparator c) | 返回流中最大值 |
| min(Comparator c) | 返回流中最小值 |
| forEach(Consumer c) | 内部迭代(使用Collection接口需要用户去做迭代,称为外部迭代。相反,Stream API使用内部迭代—它帮你把迭代做了) |
- 代码实现
package Java8;
import org.junit.Test;
import java.util.Optional;
import java.util.stream.Stream;
/**
* Stream 终止操作
*/
public class StreamAPITest3 {
// 匹配与查找
@Test
public void test1() {
System.out.println("------allMatch------");
// 是否所有员工年龄都大于18岁
boolean allMatch = EmployeeData.getEmployees().stream().allMatch(e -> e.getAge() > 18);
System.out.println(allMatch);
System.out.println("------anyMatch------");
// 是否存在员工工资大于10000
boolean anyMatch = EmployeeData.getEmployees().stream().anyMatch(e -> e.getSalary() > 10000);
System.out.println(anyMatch);
System.out.println("------noneMatch------");
// 是否存在员工姓”雷“
boolean noneMatch = EmployeeData.getEmployees().stream().noneMatch(e -> e.getName().startsWith("雷"));
System.out.println(noneMatch);
System.out.println("------findFirst------");
Optional<Employee> employee = EmployeeData.getEmployees().stream().findFirst();
System.out.println(employee);
System.out.println("------findAny------");
Optional<Employee> employee1 = EmployeeData.getEmployees().stream().findAny();
System.out.println(employee1);
System.out.println("------count------");
long count = EmployeeData.getEmployees().stream().filter(e -> e.getSalary() > 5000).count();
System.out.println(count);
System.out.println("------max------");
// 返回最高的工资
Stream<Double> salaryStream = EmployeeData.getEmployees().stream().map(Employee::getSalary);
Optional<Double> maxSalary = salaryStream.max(Double::compare);
System.out.println(maxSalary);
System.out.println("------min------");
// 返回工资最低的员工
Optional<Employee> employee2 = EmployeeData.getEmployees().stream().min((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary()));
System.out.println(employee2);
System.out.println("------forEach------");
EmployeeData.getEmployees().forEach(System.out::println);
}
}
运行结果
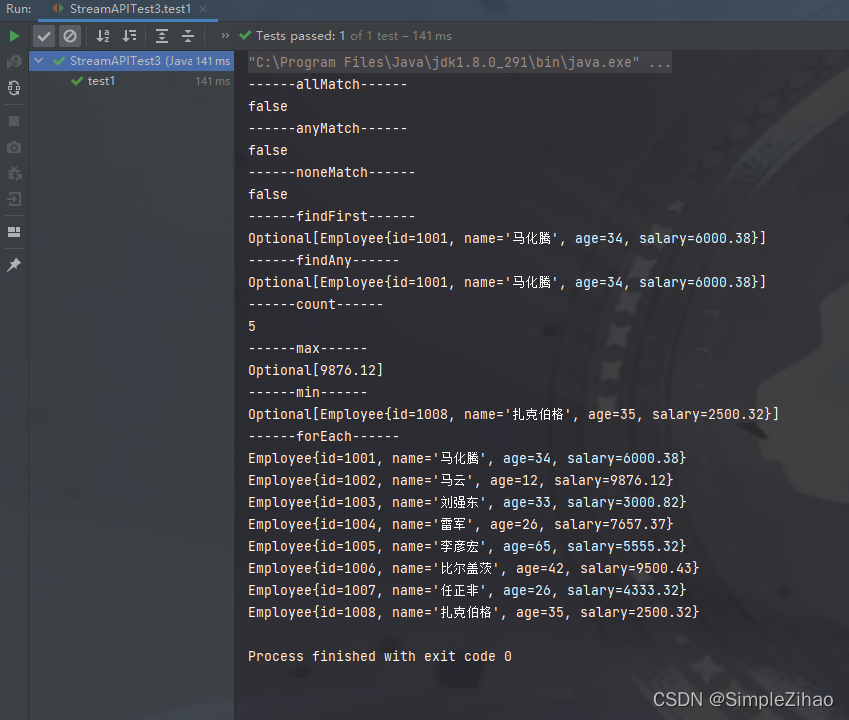
- 归约
- 常用方法
| 方法 | 描述 |
|---|---|
| reduce(T iden, BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回T |
| reduce(BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回Optional< T > |
-
map和reduce的连接通常称为map-reduce模式,因Google用它来进行网络搜索而出名
-
代码示例
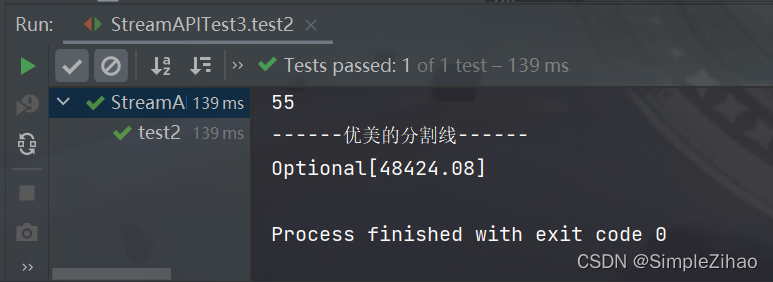
// 归约
@Test
public void test2(){
// 计算1-10的自然数的值
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer sum = list.stream().reduce(0, Integer::sum); // 第一个参数为初始值
System.out.println(sum);
System.out.println("------优美的分割线------");
List<Employee> employees = EmployeeData.getEmployees();
Stream<Double> salaryStream = employees.stream().map(Employee::getSalary);
Optional<Double> sumMoney = salaryStream.reduce(Double::sum);
System.out.println(sumMoney);
}
运行结果
- 收集
- 常用方法
| 方法 | 描述 |
|---|---|
| collect(Collector c) | 将流转换为其它形式。接收一个Collector接口的实现,用于给Stream中元素做汇总的方法 |
- Collector接口中方法的实现决定了如何对流执行收集的操作(如收集到List、Set、Map)
- 另外,Collectors实用类提供了很多静态方法,可以方便地创建常见收集器实例,具体如下表

- 代码示例
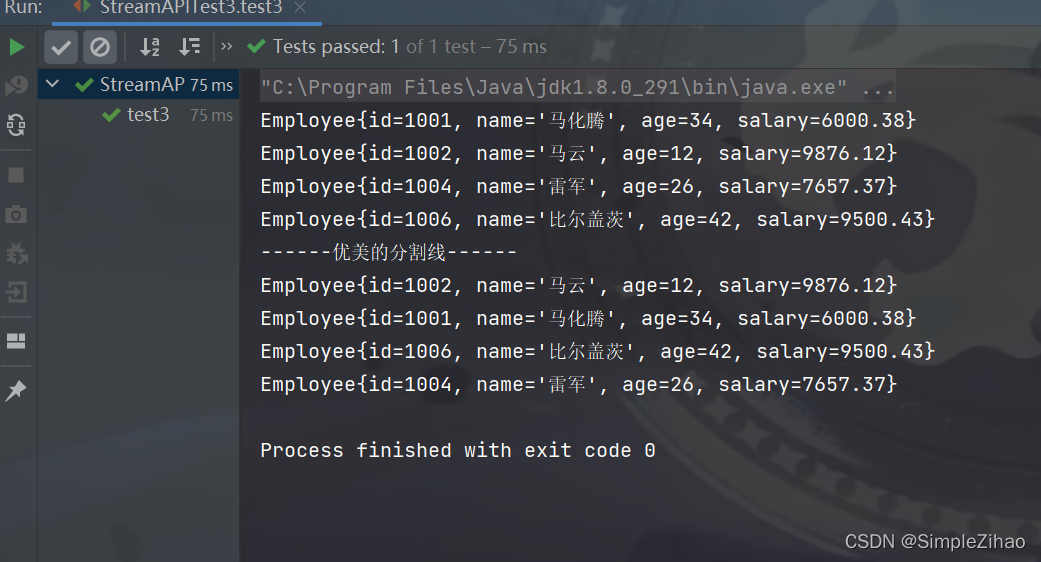
// 收集
@Test
public void test3() {
// 查找工资大于6000地员工
List<Employee> employees = EmployeeData.getEmployees();
List<Employee> employeeList = employees.stream().filter(employee -> employee.getSalary() > 6000)
.collect(Collectors.toList());
employeeList.forEach(System.out::println);
System.out.println("------优美的分割线------");
Set<Employee> employeeSet = employees.stream().filter(employee -> employee.getSalary() > 6000)
.collect(Collectors.toSet());
employeeSet.forEach(System.out::println);
}
运行结果


















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











