







 本文详细介绍了如何使用YOLOv5训练自己的目标检测模型,包括安装环境、数据集标注、目录准备、数据集划分、模型训练、权重调整以及推理过程。重点讲解了使用Labelimg进行数据标注,以及训练过程中yaml配置文件的修改和预训练权重的使用。
本文详细介绍了如何使用YOLOv5训练自己的目标检测模型,包括安装环境、数据集标注、目录准备、数据集划分、模型训练、权重调整以及推理过程。重点讲解了使用Labelimg进行数据标注,以及训练过程中yaml配置文件的修改和预训练权重的使用。
Install
把代码拉下来
GitHub - ultralytics/yolov5 at v5.0
然后
pip install -r requirements.txt安装完了,运行一下detect.py即可
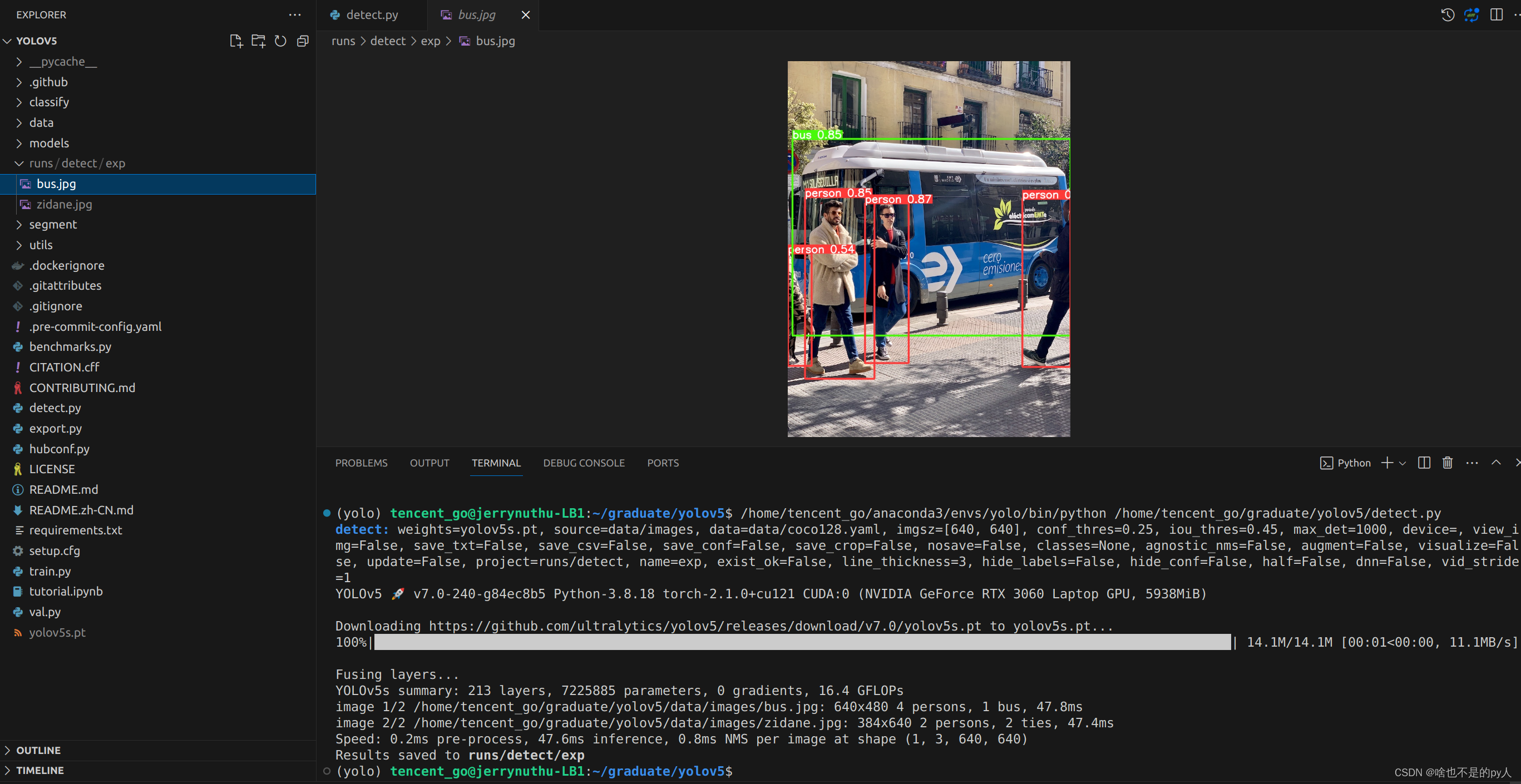
结果会保存在对应的目录下
Intro
├── data:主要是存放一些超参数的配置文件(这些文件(yaml文件)是用来配置训练集和测试集还有验证集的路径的,其中还包括目标检测的种类数和种类的名称);还有一些官方提供测试的图片。如果是训练自己的数据集的话,那么就需要修改其中的yaml文件。但是自己的数据集不建议放在这个路径下面,而是建议把数据集放到yolov5项目的同级目录下面。
├── models:里面主要是一些网络构建的配置文件和函数,其中包含了该项目的四个不同的版本,分别为是s、m、l、x。从名字就可以看出,这几个版本的大小。他们的检测测度分别都是从快到慢,但是精确度分别是从低到高。这就是所谓的鱼和熊掌不可兼得。如果训练自己的数据集的话,就需要修改这里面相对应的yaml文件来训练自己模型。
├── utils:存放的是工具类的函数,里面有loss函数,metrics函数,plots函数等等。
├── weights:放置训练好的权重参数。
├── detect.py:利用训练好的权重参数进行目标检测,可以进行图像、视频和摄像头的检测。
├── train.py:训练自己的数据集的函数。
├── test.py:测试训练的结果的函数。
├──requirements.txt:这是一个文本文件,里面写着使用yolov5项目的环境依赖包的一些版本,可以利用该文本导入相应版本的包。
数据集准备
数据集标注
Labelimg是一款开源的数据标注工具,可以标注三种格式。
1 VOC标签格式,保存为xml文件。
2 yolo标签格式,保存为txt文件。
3 createML标签格式,保存为json格式。
安装工具
sudo apt-get install pyqt5-dev-tools
pip install lxml
git clone https://github.com/tzutalin/labelImg.git
cd labelImg
make all
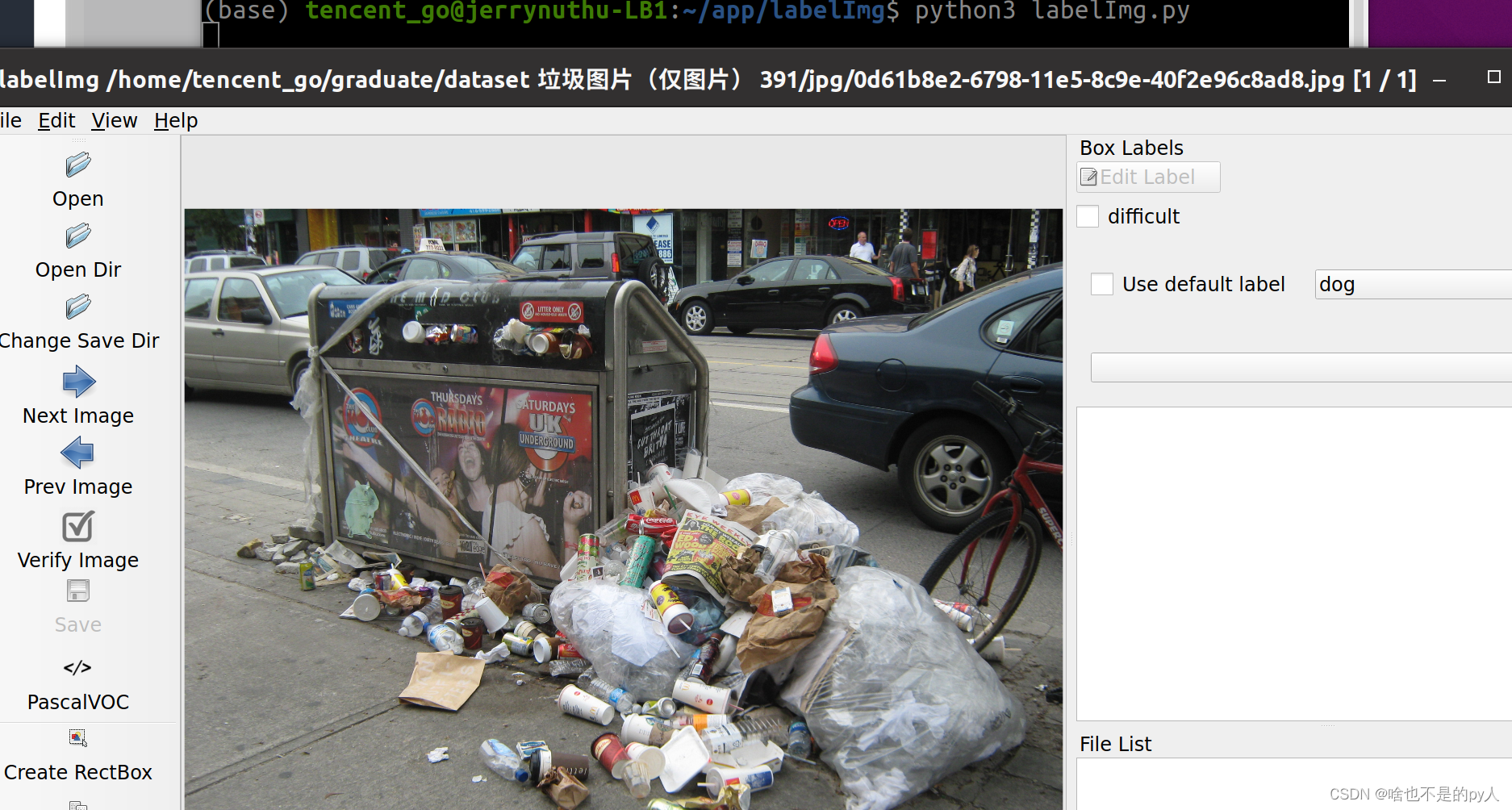
python3 labelImg.py #打开labelImg
python3 labelImg.py [IMAGE_PATH] [PRE-DEFINED CLASS FILE]运行:
目录准备
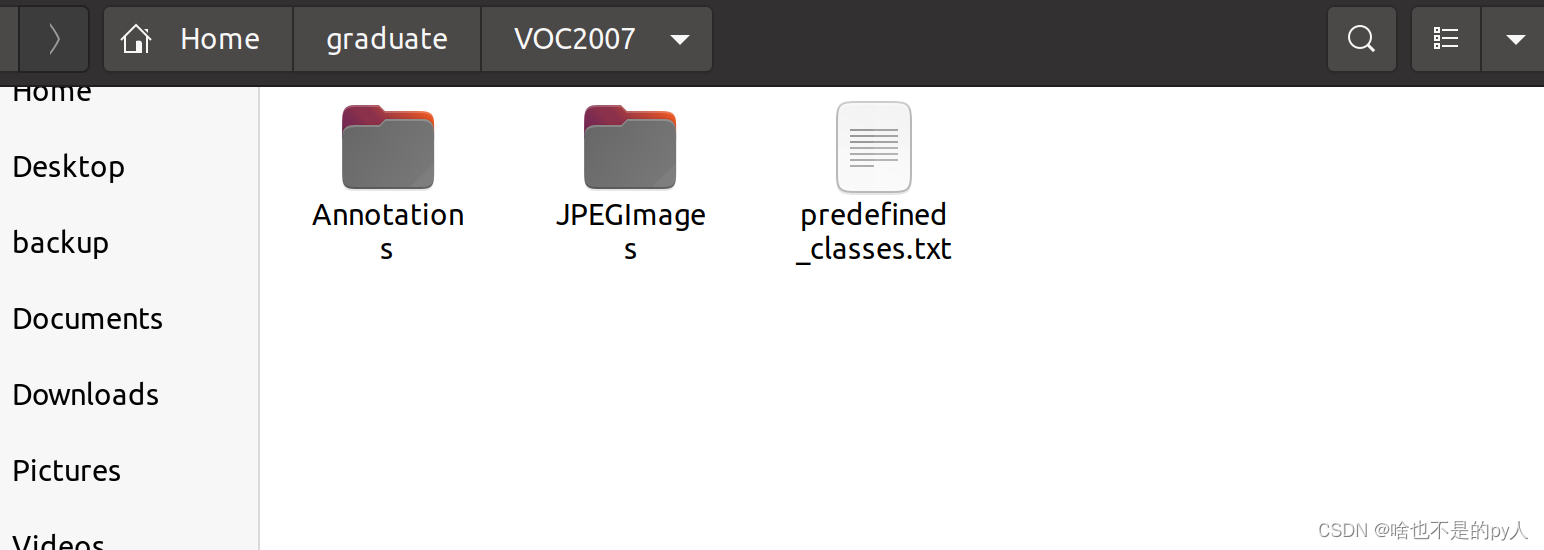
这里我建议新建一个名为VOC2007的文件夹(这个是约定俗成,不这么做也行),
里面创建一个名为JPEGImages的文件夹存放我们需要打标签的图片文件;
再创建一个名为Annotations存放标注的标签文件;
最后创建一个名为predefined_classes.txt 的txt文件来存放所要标注的类别名称。
VOC2007的目录结构为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









