







 本文详细介绍了Hadoop Streaming的原理、优缺点,并重点讲解了其开发要点,包括输入输出、mapper和reducer的设置、文件分发、配置参数等,以及如何处理数据压缩和输入为压缩文件的情况。
本文详细介绍了Hadoop Streaming的原理、优缺点,并重点讲解了其开发要点,包括输入输出、mapper和reducer的设置、文件分发、配置参数等,以及如何处理数据压缩和输入为压缩文件的情况。
一、Hadoop Streaming
1.streaming简介

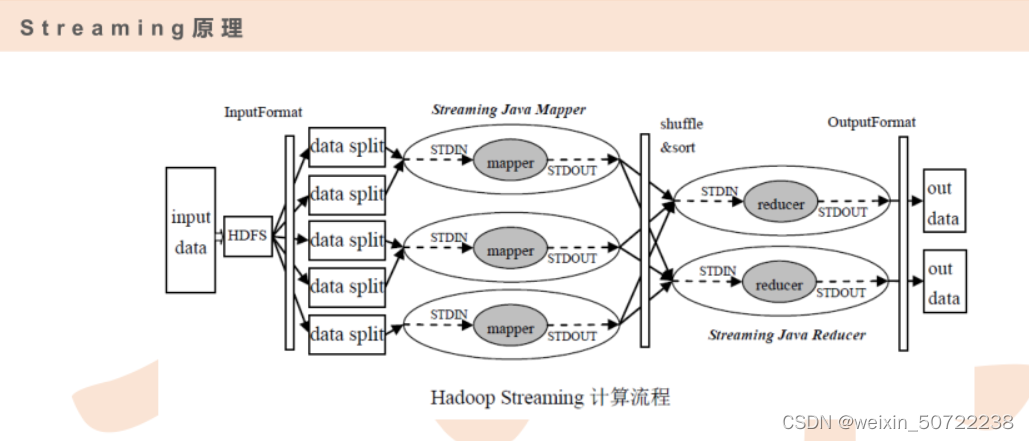
2.streaming原 理
streaming从输入stdin到输出stdout做了包装,允许mapper和reducer编程使用任何语言。
3.streaming优 点
1)单机调试的sort模拟了shuffle过程
2)有些语言如C/C++编写的程序可能比用Java编写的程序效率更高一些,对运行效率有极高要求时很多人会用C/C++,因为C/C++编译出的bin的更接近底层。
3)streaming提供好了很多现成的参数配置,可以通过灵活配置方便资源利用

4.streaming局 限

两次数据拷贝和解析(分割),带来一定的开销:java开发不需要标准输入与输出,从split到java开发的mapper只需要一次转化,即把原始数据key和value只需解析一次;streaming开发从原始数据解析出key和value后还需要转换成标准输入和标准输出,所以streaming多涉及到了一倍的拷贝。故steaming开发效率没有java开发效率高。mapreduce的开发对于这种拷贝和解析的时效性可以忽略。
二、Hadoop Streaming开发要点
1.输入、输出

- input支持指定多个文件或目录
- 如果input文件特别多,可以用通配符
2.mapper、reducer
(1)如果是shell语言:-mapper “bash mapper.sh”
(2)mapper是必须的,reduce不是必须的,如只需要做一些过滤。
(3)如果用python开发,格式:(python mapper或reducer执行文件 函数 函数参数)。比如 -mapper “python map_new.py mapper_func IPLIB”

3.-file,-cacheFile, -cacheArchive:
(1)参数是要上传到HDFS的文件
(2)-file作用:代码在本地提交,集群的多个节点是没有代码的。通过配置【-file 文件】把本地代码分发到各个执行MapReduce的节点上。只适合小的文件分发并且文件在本地。
(3)-cacheFile, -cacheArchive:如果文件比较大,建议用-cacheFile, -cacheArchive,这两个参数共同特点是要分发的数据已经在hdfs上。他们区别是-cacheFile指具体文件, -cacheArchive相当是文件体系,可能是一个目录,一个目录可能还有一个目录,是-cacheFile更高级用法。

4.低版本-jobconf,高版本-D。
(1)为当前mapreduce起名字:-jobconf mapred.job.name=”xxx"。
(2)也可以通过配置控制reduce个数,map个数,指定分隔符,指定key区域。
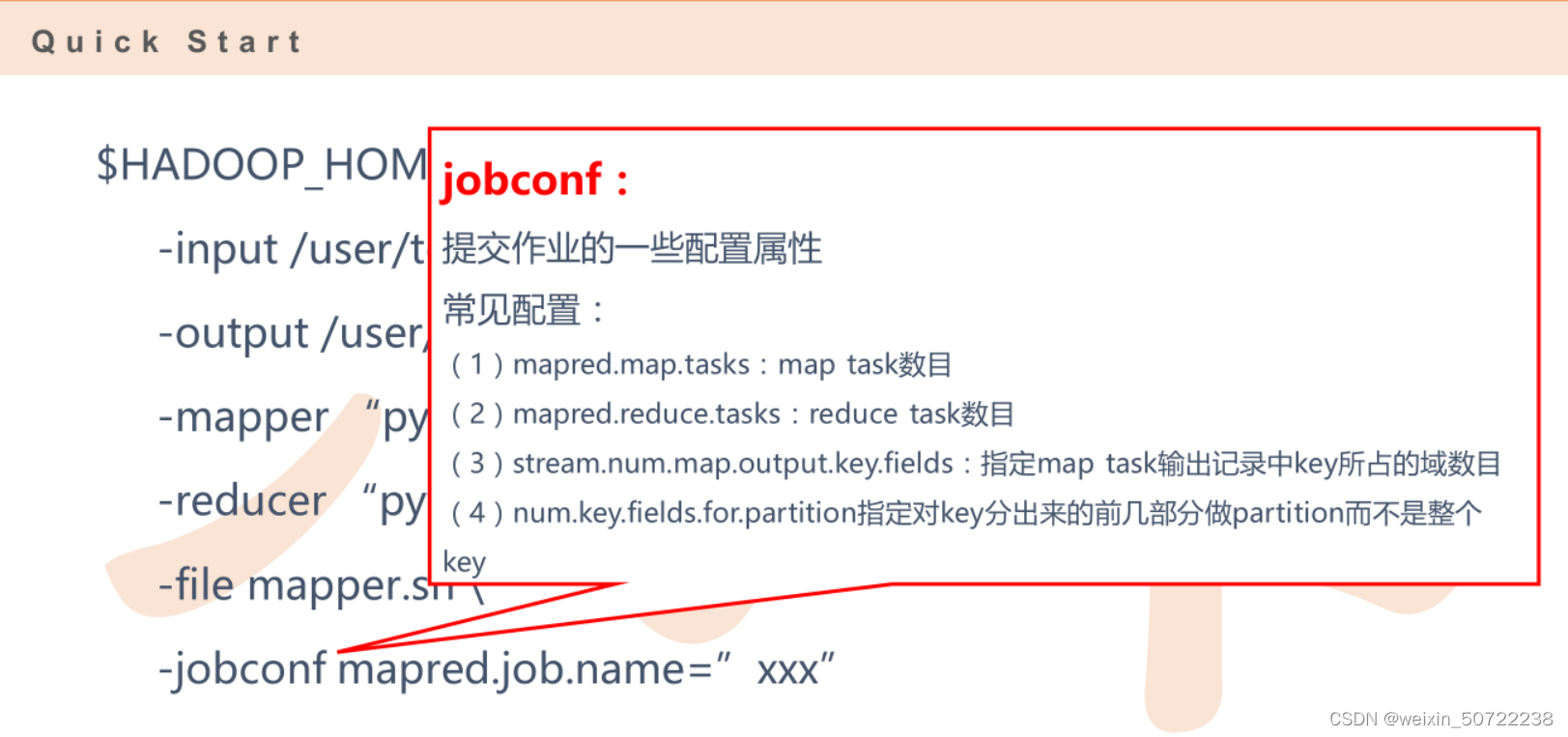
5.-jobconf,-D常见配置参数
(1)解释

(2)例如:
- -jobconf “mapred.job.name=cachefile_demo” \
- 作业名
- -jobconf “mapred.compress.map.output=true” \
- map的输出是否压缩
- -jobconf “mapred.map.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec” \
- map的输出压缩方式
- -jobconf “mapred.output.compress=true” \
- reduce的输出是否压缩
- -jobconf “mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec” \
- reduce的输出压缩方式
- -jobconf “mapreduce.reduce.memory.mb=5000” \
- -jobconf mapred.reduce.tasks=2 \
- reduce个数
- -jobconf mapred.text.key.partitioner.options=-k2,3 \
- -jobconf stream.num.map.output.key.fields=2 \
- -jobconf stream.map.output.field.separator=. \
- -jobconf num.key.fields.for.partition=1 \
- -partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner
(3)指定压缩
(i)指定map和reduce输出为压缩
-
map输出和reduce输出为压缩
- 输出数据量较大时,可以使用Hadoop提供的压缩机制对数据进行压缩,减少网络传输带宽和存储的消耗。
- 可以指定对map的输出也就是中间结果进行压缩
- 可以指定对reduce的输出也就是最终输出进行压缩
- 可以指定是否压缩以及采用哪种压缩方式。
- 对map输出进行压缩主要是为了减少shuffle过程中网络传输数据量
- 对reduce输出进行压缩主要是减少输出结果占用的HDFS存储。
-
实践
- 加上这几个参数
- -jobconf “mapred.compress.map.output=true” \
- map的输出是否压缩,,默认是false,想要开启要把参数加上配置。
- -jobconf “mapred.map.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec” \
- map的输出压缩方式
- -jobconf “mapred.output.compress=true” \
- reduce的输出是否压缩
- -jobconf “mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec” \
- reduce的输出压缩方式
- -jobconf “mapred.compress.map.output=true” \
- 代码:
-jobconf "mapred.compress.map.output=true" \ -jobconf "mapred.map.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec" \ -jobconf "mapred.output.compress=true" \ -jobconf "mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec" \- 举例
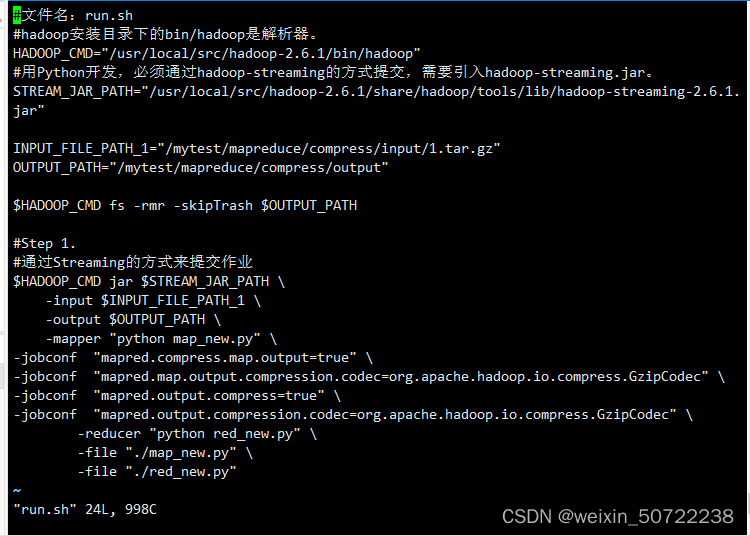
最后使用hadoop fs -ls看到reduce输出文件带gz后缀。

- 加上这几个参数
(ii)输入文件可以为压缩文件
输入数据是压缩文件的话,在HDFS会自动解压。有几个压缩文件就有几个map,这种使用压缩的方式可以很好地控制map个数。

(iii)指定分区字段和key字段
- 顺序
- mapreduce会把相同分区的数据放在一起,并且针对每一个桶的数据进行对key排序。
- 比如一行数据aaa bbb ccc,如果key=(aaa bbb),value=ccc,但是按照aaa做partition。这个时候partition和key是不相同的,partition会把第一列的数据放在一块;sort是对key操作的,做sort时会对key(即第一、二列)进一步进行排序,相当于做了二次排序的概念。
- key!=partition
- key!=partition,有可能key=(aaa bbb),value=ccc,但是按照aaa做partition。
- 默认情况下partition=key。
- 对于key value值,默认按key做partition,但是实际会很复杂。
- 指定分区字段
-jobconf mapred.text.key.partitioner.options=-k2,3 \
# 指定第二列和第三列做partition。比如一行数据a b c d,partition=b c。
-jobconf num.key.fields.for.partition=1 \
# 指定哪一个做partition。比如一行数据aaa bbb ccc,partition=aaa。还可以指定bbb或ccc做partition。
- 指定key字段
-jobconf stream.num.map.output.key.fields=3 \
# 指定前3个字段做key。比如一行数据a b c d,key=a b c,value=d。

















 9478
9478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









