




 本文详细介绍了Zookeeper,一个分布式系统的协调服务。它解决了分布式系统中的一致性、容灾和顺序问题,并提供了配置管理、集群管理和锁服务等功能。Zookeeper基于Paxos协议,采用类似文件系统的数据模型,支持权限控制。文中还涵盖了Zookeeper的应用场景,如配置管理、集群选主和锁服务,并给出了基础实践,包括安装和使用Zookeeper的步骤。
本文详细介绍了Zookeeper,一个分布式系统的协调服务。它解决了分布式系统中的一致性、容灾和顺序问题,并提供了配置管理、集群管理和锁服务等功能。Zookeeper基于Paxos协议,采用类似文件系统的数据模型,支持权限控制。文中还涵盖了Zookeeper的应用场景,如配置管理、集群选主和锁服务,并给出了基础实践,包括安装和使用Zookeeper的步骤。
一、Zookeeper概述
1.分布式系统的问题
zookeeper提供分布式的锁服务,对于一个集群的稳定起到非常关键的作用,因为它可以协调不同节点之间的工作(核心是分布式的锁服务)。
I.分布式系统的问题
- 与单机系统不同:单机开发涉及到锁的地方是进程的多线程的开发,可能会搞一些内存锁、互斥锁、读写锁等。为什么通过锁可以控制有效地运转,是因为锁可以作为一个全局唯一的一个标准 。
- 内存地址一致 :存在竞争公共资源
- 单机出问题概率低
- 分布式系统
- 一致性问题 :HDFS的一致性,分为强一致和弱一致(还没有达到三副本平衡,在只有一个副本可以对外提供服务,之后慢慢拷贝得到三副本)。
- 容灾容错 :如一台机器挂了
- 执行顺序问题 :锁服务
- 事务性问题

单机多线程情况时锁的经典例子:
如下图:蓝色的方块是公共变量,黄色的方块是线程。在线程1还没来得及去写时线程2也要执行。
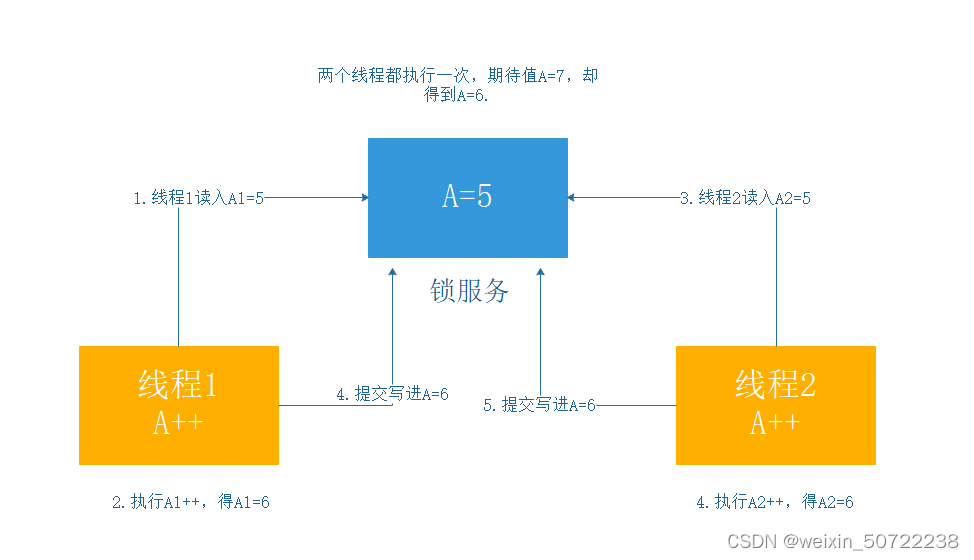
II.核心问题
- 没有一个全局的主控,协调或控制中心:导致没有一个正确的顺序。
- 需要一个松散耦合(对硬件依赖性不强,不需要高配置机器,如内存、硬盘特别大,cpu核数多么的多)的分布式系统中粗粒度锁(进程间多线程是细粒度的)以及可靠性存储(低容量,这个系统可以存储一些数据)的系统(例如zookeeper就是这样一个系统)。

2.zookeeper概述
I.简介
- Hadoop系统:zookeeper属于hadoop生态里的重要成员
- 开源高效可靠
- 名字服务器(zookeeper系统可以给各个机器取名字,要求每台机器名字不一致),分布式同步(如用5台机器搭建zookeeper集群,用其中任意一台机器得到的信息都是一致的),组服务
- Google内部实现叫Chubby:没有开源,雅虎模拟这么个服务搞出了zookeeper且开源捐给了Apache。
- 基于Paxos协议:保证集群里访问任意一台机器得到的结果是一样的。

- zookeeper以类似目录树的方式来管理节点
- 数据模型类似于linux环境下的文件系统,比如目录里面有文件和目录,文件和目录中有层级关系,zookeeper中不能用相对路径。

zookeeper的形象图如下:很像文件目录树,图中的绿色方块都是节点。
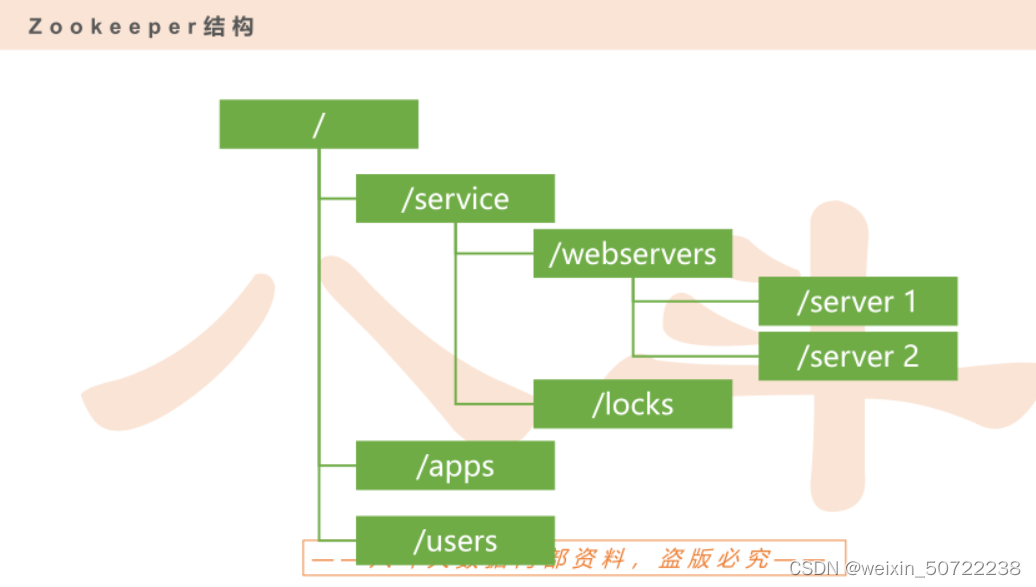
4种类型节点:PERSISTENT、EPHEMERAL、PERSISTENT_SEQUENTIAL、EPHEMERAL_SEQUENTIAL。
- 数据模型类似于linux环境下的文件系统,比如目录里面有文件和目录,文件和目录中有层级关系,zookeeper中不能用相对路径。
- Persistent Nodes:永久存在
- Ephemeral Nodes:随着client连接取消而删除此节点,再次连接仍然没有这个节点,需要的话要重新创建。创建后这个临时节点与创建它的机器发生心跳,当机器发生故障(重启、关机(命令可以是init 0)可以,退出客户端 ./zkCli.sh不可以)这个节点自动消失。
- Sequence Nodes:不能单独存在,需绑定Persistent Nodes或Ephemeral Nodes。

II.监控功能(心跳使得可以支持监控)
- 监控机制(watch):监控某一台机器是否生效。假设说主机器挂了,如果还有备份的主的话可以启动备份主,前提是可以监控到主挂了的事件。数据节点监控到某机器挂了后告诉客户端client。监控有三类情况:数据修改getData、子节点变化getChildren、节点退出exists(节点被删除会报警)。
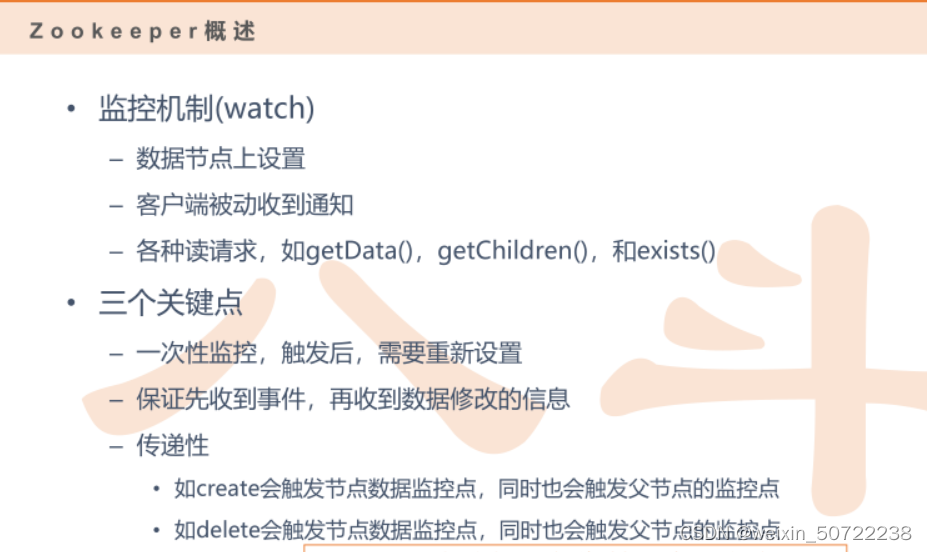

III.权限
(1)数据访问
权限直接设置在zookeeper节点上,三元组定义客户端访问权限(scheme代表机制:expression代表用户,perms代表权限)。

(2)perms权限

(3)scheme机制
- World:zookeeper中对所有人有权限的结点就是属于world:anyone的
- Auth和Digest区别:Auth除了用户名:密码方式,还可以通过其他方式Kerberos。Digest用的比较多。
- Host和IP类似,可以用IP地址识别,也可以通过hostname识别。

访问控制链:一个节点控制多个访问控制。
如下图把acl1和acl2添加至访问控制链acls。new ZooKeeper(“host1:2181,host2:2181,host3:2181”, 2000, null);的参数2000是超出时间。zk.addAuthInfo增加权限。zk(zookeeper)创建节点参数有路径、数据、权限、节点类型。
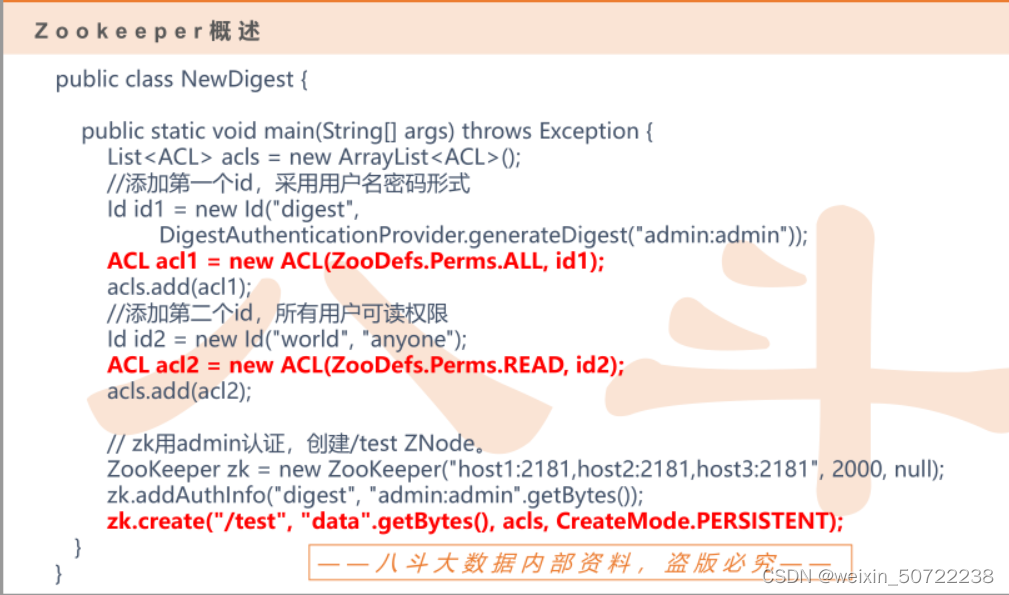






二、Zookeeper应用场景
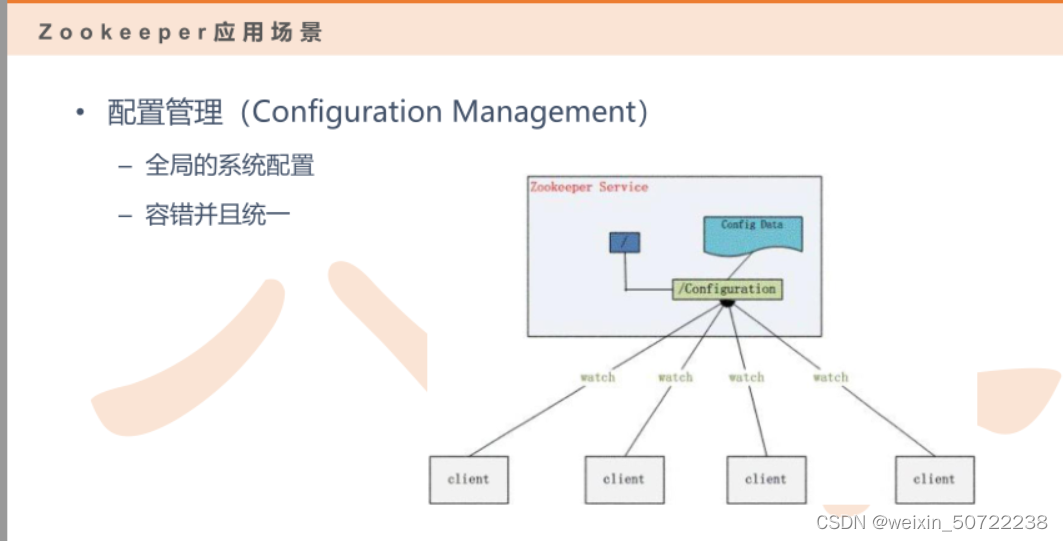
1.Zookeeper配置管理
配置节点在zk集群上,可以分担压力。
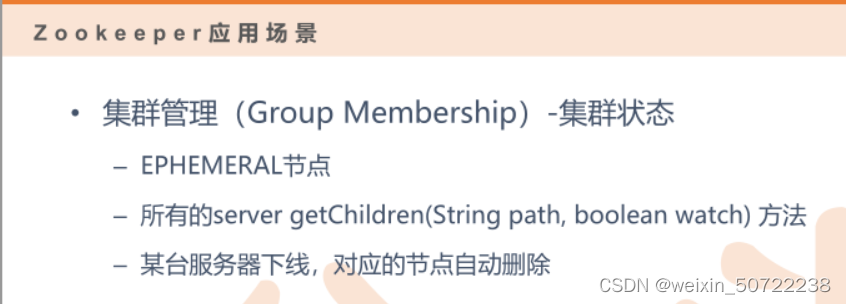
2.集群管理
I.集群管理
- zk建立一个节点,然后让这个节点和服务器建立心跳关系去监控,如果出现事件变化,可以通过worker去通知。
- 选主

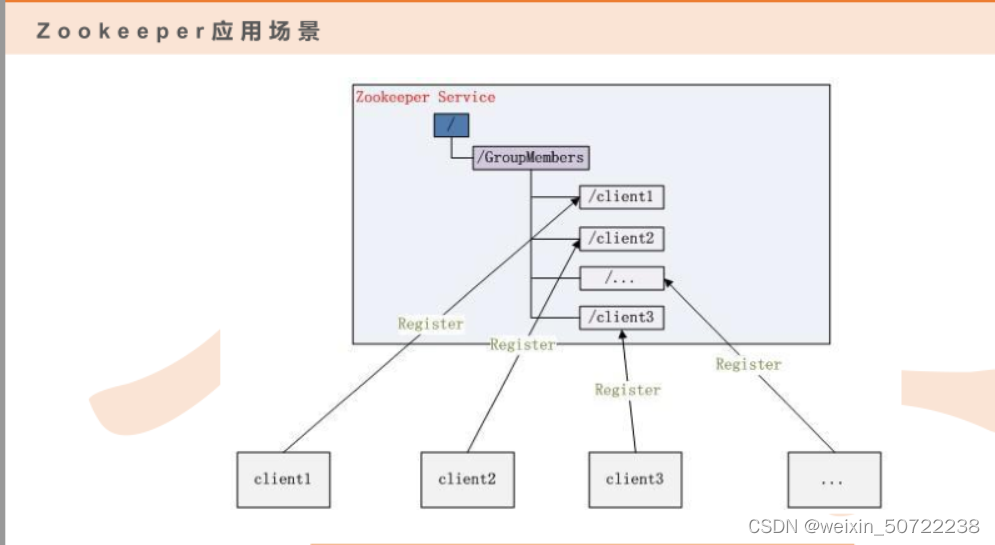
II.集群管理-zk集群状态
client某台服务器下线,zk对应的节点自动删除。
如下图:
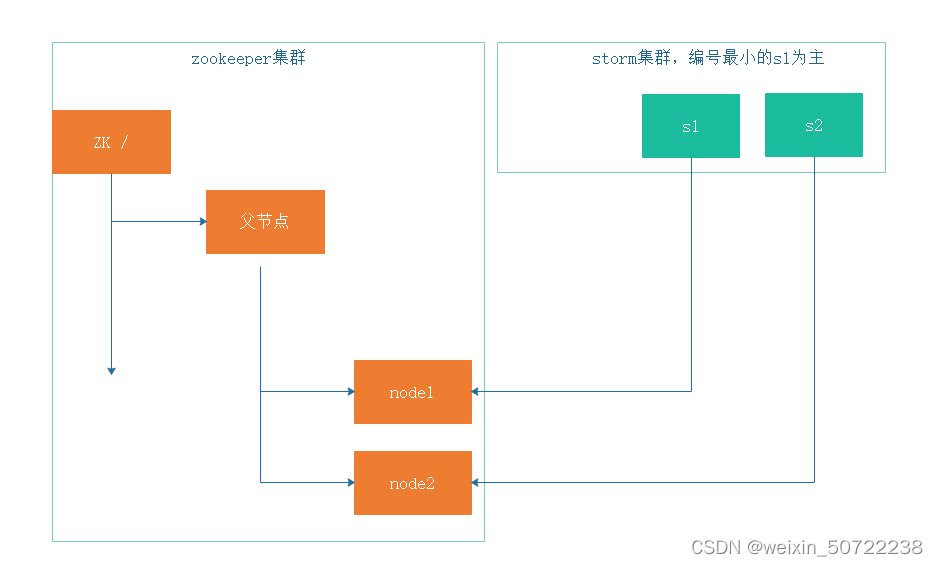
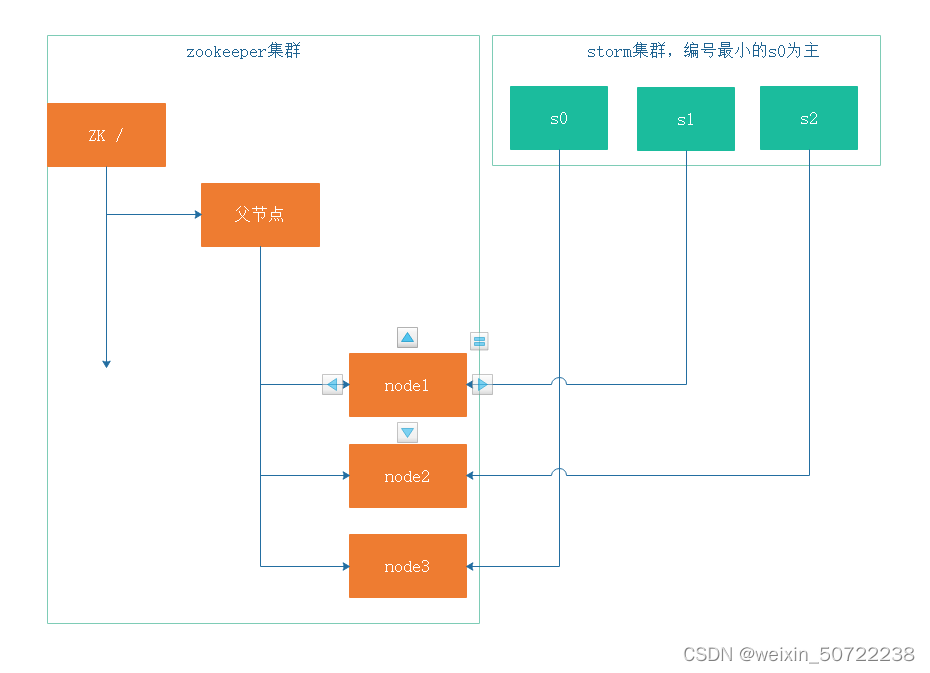
III.集群管理-选主:

编号最小的s0为主
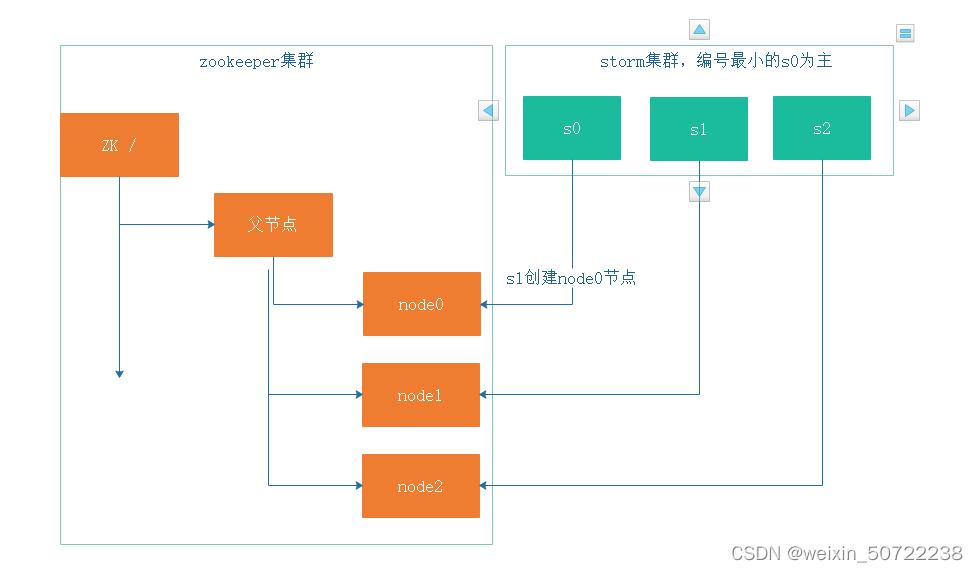
s0挂了,node0节点消失,zk父节点告诉别人选新的主s1。
机器s0修好了,则重新创建节点
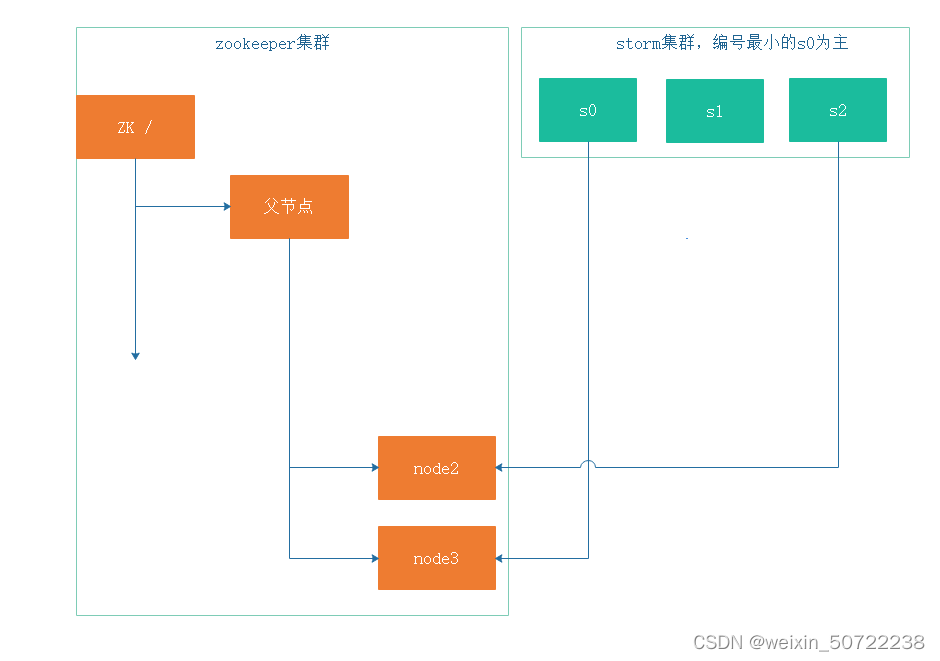
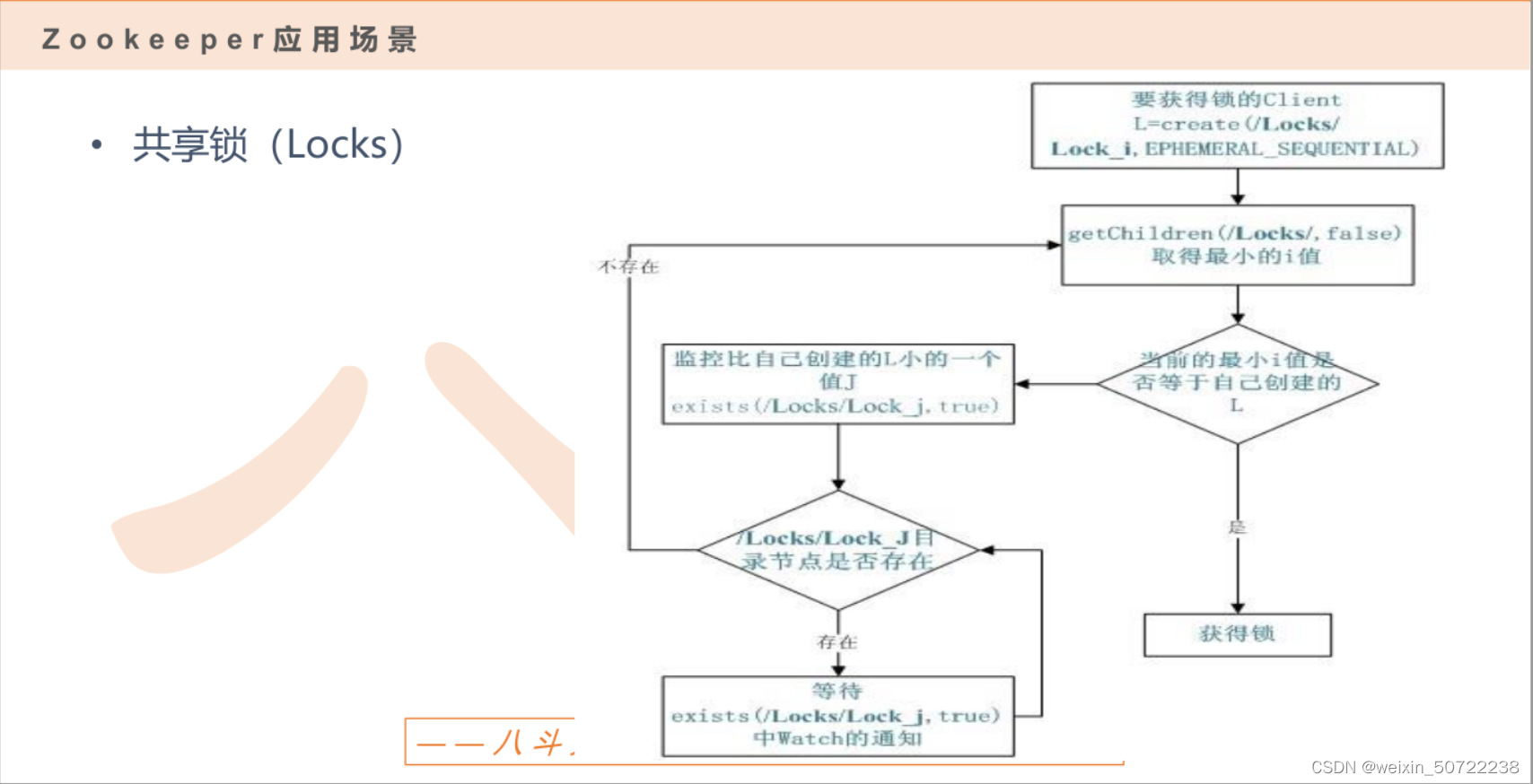
3.zookeeper锁服务
如下图例子:s0、s1、s2都是进程,那么谁先执行谁后执行?首先找编号最小的节点node1,即先处理s1。
当s1处理完成之后退出
再处理node2对应进程s2,最后处理node3对应进程s0。
4.zookeeper队列管理
- 同步队列
- 所有成员都聚齐才开始去做
- 先入先出队列。

同步队列流程图:
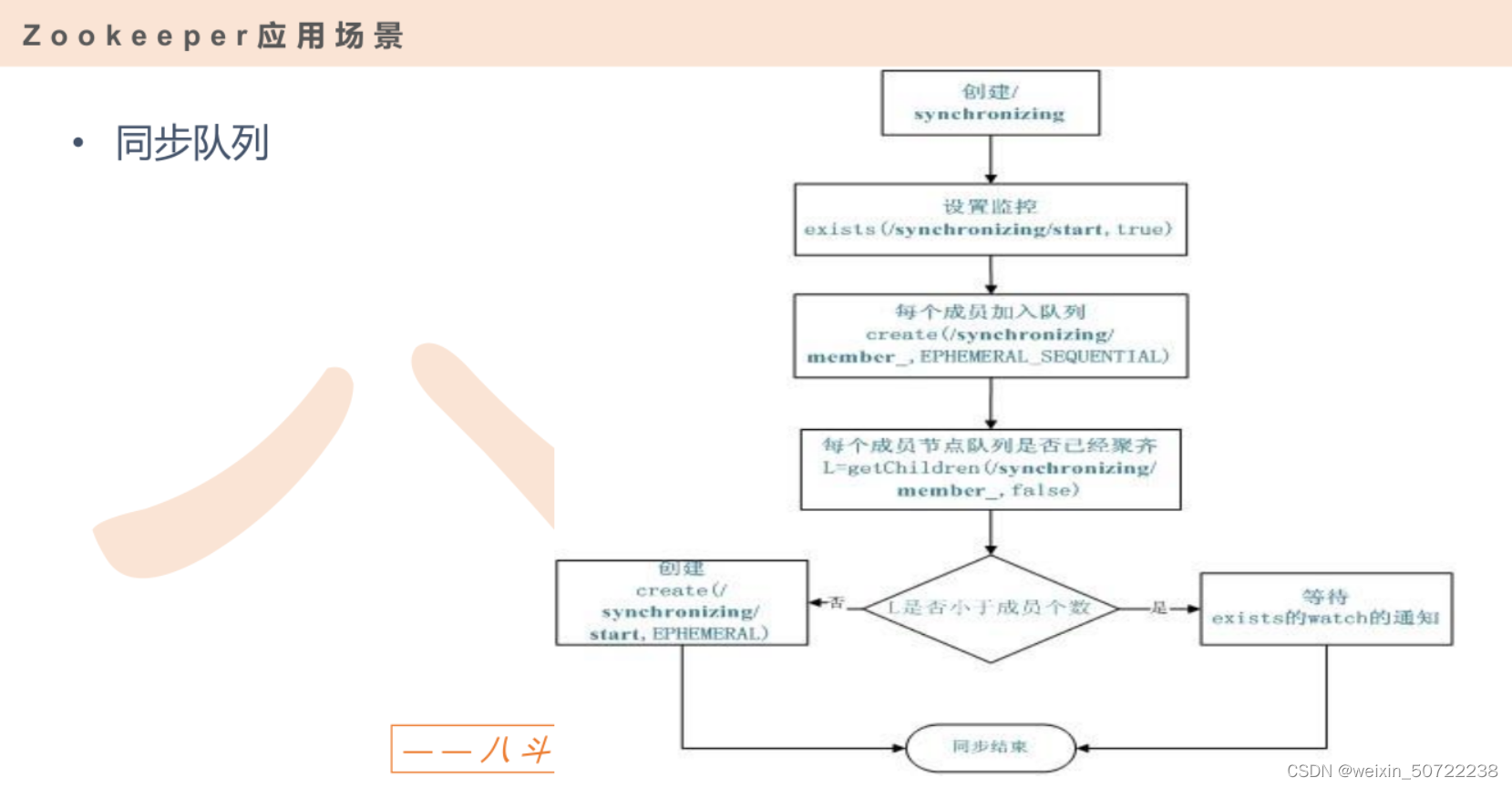
先入先出队列(FIFO队列):

三、【基础实践】Zookeeper编程
1.Zookeeper3.4.11安装
先解压tar zxvf zookeeper-3.4.10.tar.gz。只需要改两个配置文件zoo.cfg和myid,再配置环境变量。
I.修改配置文件zoo.cfg
#修改配置
cd conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
#zoo.cfg文件末尾添加
dataDir=/usr/local/src/zookeeper-3.4.10/data
dataLogDir=/usr/local/src/zookeeper-3.4.10/log
server.0=master:2888:3888
server.1=slave1:2888:3888
server.2=slave2:2888:3888
#Master
cd zookeeper-3.4.10
#创建日志文件夹及数据文件夹
mkdir data
mkdir log
II.配置环境变量
#Master、Slave1、Slave2
vim ~/.bashrc
文件名:~/.bashrc
#修改内容如下
#set Zookeeper environment
export ZOOKEEPER_HOME=/usr/local/src/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
#刷新环境变量
source ~/.bashrc
III. 拷贝安装包
#Master
scp -r /usr/local/src/zookeeper-3.4.10 root@slave1:/usr/local/src/
scp -r /usr/local/src/zookeeper-3.4.10 root@slave2:/usr/local/src/
IV.分别添加ID。
#创建文件/usr/local/src/zookeeper-3.4.10/data/myid ,myid代表了当前机器的编号或名称,是全局唯一的。
#Master
echo "0" > /usr/local/src/zookeeper-3.4.10/data/myid
#Slave1
echo "1" > /usr/local/src/zookeeper-3.4.10/data/myid
#Slave2
echo "2" > /usr/local/src/zookeeper-3.4.10/data/myid
2.Zookeeper使用
执行./zkServer.sh可以提示有哪些命令,如start-foreground、restart、upgrade、print-cmd。
-
zkServer.sh start
-
zkServer.sh status
-
zkServer.sh stop
-
zkCli.sh -server zookeeper:2181
-
执行客户端 ./zkCli.sh
- ls / :查看当前目录
- create /text “123” :创建节点,默认永久节点,冒号也算一个字符串的一部分。
- create -e /text “test” :创建临时节点
- create -s /text “test” :创建序列节点
- get /text 查看节点
- set /text 123:修改数据
- rmr /text:删除节点,如果节点不空也可以删除,也就是说可以删除路径。
- delete /text:删除节点,如果节点不空则不能删除。

3.注意
- 检查是否启动:使用jps查看是否有QuorumPeer进程,如果是HQuorumPeer说明启动了hbase。启动hbase时可以帮你把zookeeper启动起来。
- 检查是否生效:使用zkServer.sh status查看是否有Leader和follower。
- 执行客户端 bin/zkCli.sh
使用create -s /mytest/seqnode "111"创建序列节点后,使用ls /mytest查看得到 [ seqnode0000000000 ]。
使用create -s /mytest/seqnode "111"再创建一个顺序节点,使用ls /mytest查看得到 [ seqnode0000000000, seqnode0000000001 ] 。
使用rmr /mytest/seqnode00000000001删除节点后,使用create -s /mytest/seqnode "111"再创建一个得到seqnode0000000003,即使文件删除后这个序号也不会重新分配给创建的下一个文件而是跳过此序号。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









