






本文纯属复现和鲸社区大佬Phoenix的分析过程,及大部分代码,此处贴上地址:
原链接地址
RFM电商数据分析(4)
分析过程:

一 准备
分类导入必要包
数据来源公开社区,564169条/15行/94MB 某电子产品2020/01/05-2020/11/25销售数据
二 数据处理
1. 导入数据,将字段名改为中文名称
2. 为了后期分析用户数据,创建新的字段:日期 / 月份 / 小时 / 周 /
3. 字段解释
4. 处理缺失数据
5. 处理重复数据
6. 处理异常值
三 计算指标。(金额/销量/用户/地区/时间 等多个维度计算各项指标)
1.销售额
GMV
GMV环比增长/增长率
销售额/订单增长曲线 (月)
2.销量
每月销量
计算销售额前10商品 订单/销售额/占比
计算销售额前10类别 订单/销售额/占比
计算销售额前10品牌 订单/销售额/占比
计算销量第一的品牌人群特征
3.用户
计算用户年龄分布 基数/占比
计算用户性别分布 基数/占比
计算用户地区分布 基数/占比 / 各省用户的占比
销售额贡献曲线(找出头部客户重点维护,二八定律-找出累计贡献销售额80%的那批用户)
客户消费金额的分位数
客户总消费金额的分布
单笔订单消费金额的分布
新客老客的销售额与销量对比
4.用户行为
用户年龄分布中 销量/销售额/
用户性别分布中 销量/销售额/
用户地区分布中 销量/销售额/
5. 时间
客户消费周期分布情况
按周销量/销售额分布
按小时分析
每月新客/老客人数分析
每月新用户/老用户 销售额环比
四 RFM模型
五 用户画像
第一步,导入所有包
import numpy as np
import pandas as pd
from pyecharts.charts import Bar,Line,Pie,Funnel,Grid
from pyecharts.globals import ThemeType
from pyecharts.faker import Faker
from pyecharts.components import Table
from pyecharts.options import ComponentTitleOpts
from pyecharts import options as opts
from datetime import datetime
导入数据
df=pd.read_csv('./电子产品销售分析.csv', index_col=0)
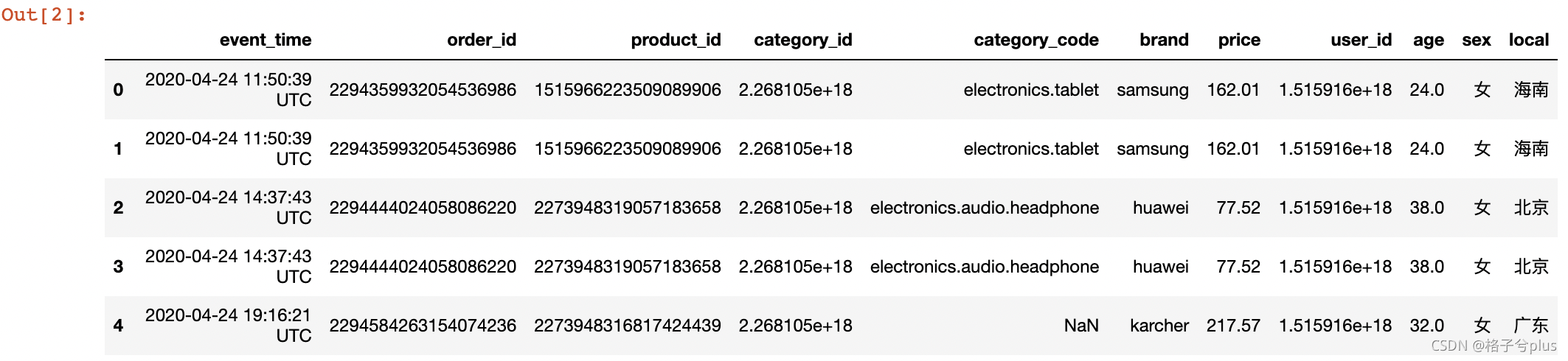
df.head()
增加时间字段
df['date'] = df['event_time'].apply(lambda x: x.split(' ')[0])
# 转化日期格式
df['event_time'] = pd.to_datetime(df['event_time'])
df['event_time']
# 添加月/周/小时,便于后续分析
df['month']=df.event_time.dt.strftime('%m')
df['hour']=df.event_time.dt.strftime('%H')
df['week']=df.event_time.dt.strftime('%w')
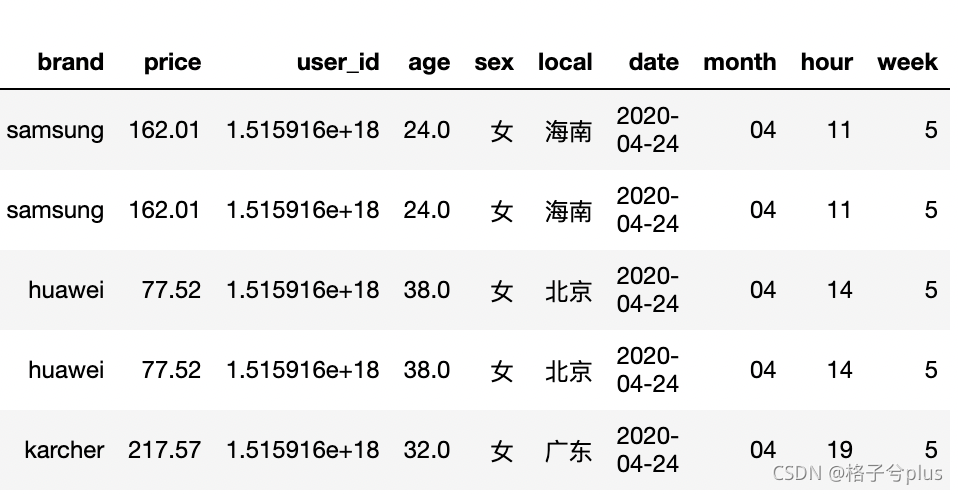
df.head()
查看数据是否非空
np.sum(df.isnull())
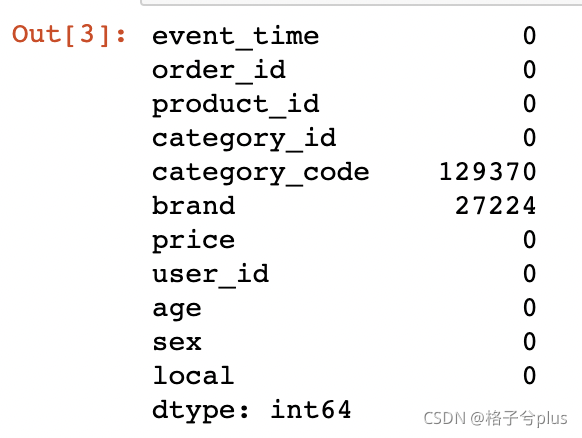
只有两列有空值(brand和category_code) brand的空值填充为R,category_code空值填充为’无类别’
# 填充缺失值,
df['brand'] = df['brand'].fillna(value='R')
df['category_code'] = df['category_code'].fillna(value='无类别')
# 再次查看缺失值
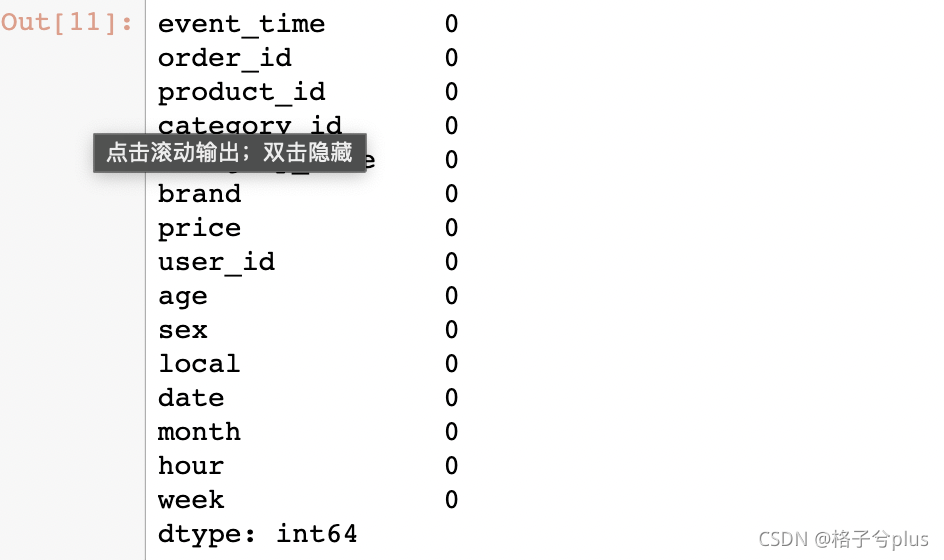
np.sum(df.isnull())
计算每笔订单的购买数量,金额
有重复的订单id和重复的产品id,代表数量 根据订单id和产品id,count(user_id)计算一个订单中用户购买改产品的数量和总价值
data_1 = df.groupby(['order_id', 'product_id']).agg(buy_count=('user_id', 'count'))
df = pd.merge(df, data_1, how='inner', on=['order_id', 'product_id'])
# 新建字段buy_count和amount
df['amount'] = df['price'] * df['buy_count']
df = df.drop_duplicates().reset_index(drop=True)
df.info()
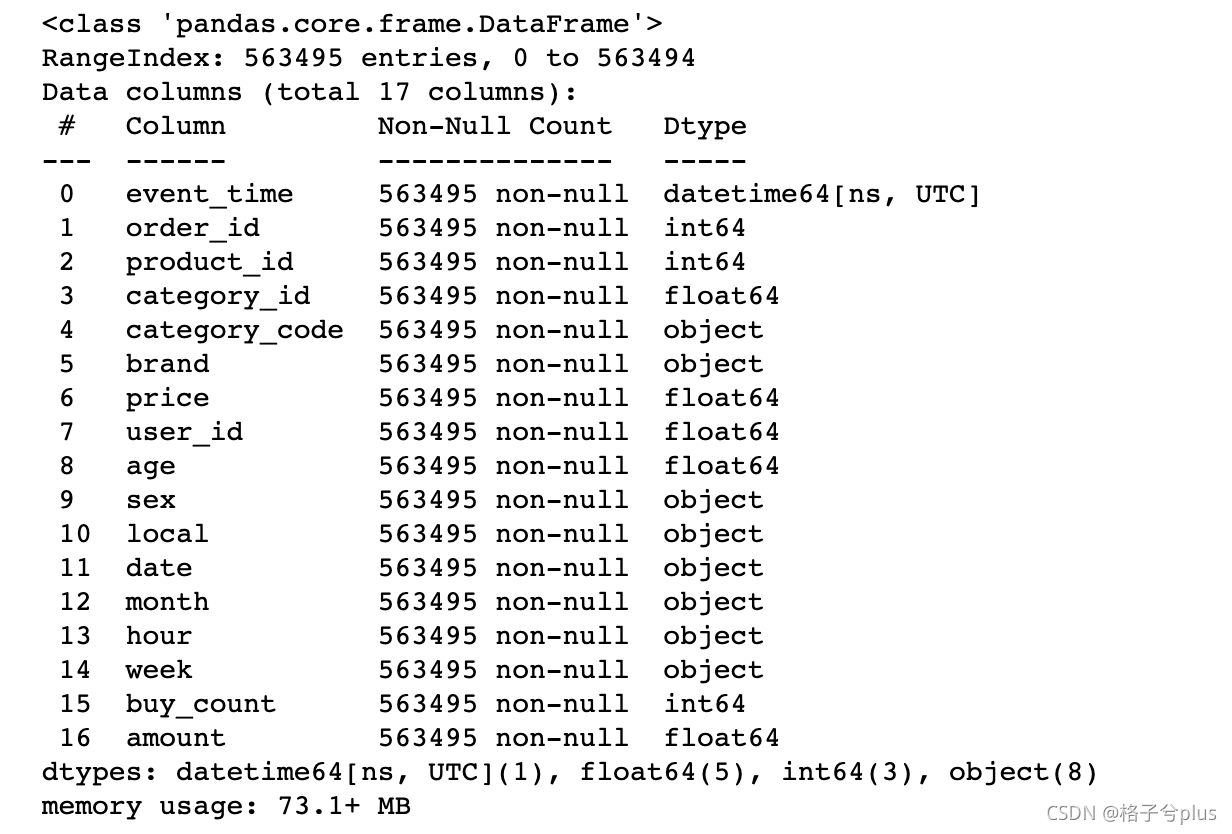
将id类型都转化为object类型
df['order_id'] = df['order_id'].astype('object')
df['product_id'] = df['product_id'].astype('object')
df['category_id'] = df['category_id'].astype('object')
df['user_id'] = df['user_id'].astype('object')
对几个基础字段做描述分析
df[['price', 'age', 'buy_count', 'amount']].describe().T
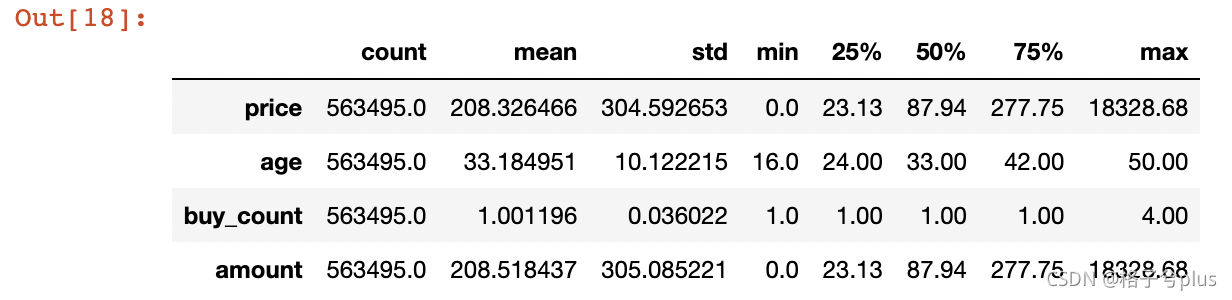
结论:产品平均价格为208元,最大值为18328.68元,最低价格为0 购物人群的最大年龄为50岁,最小年龄为16岁,中位数为33岁,平均为33岁
# 删除2000年之前的订单
df.event_time[df.event_time <= '2000-01-01 00:33:40+00:00']
df.drop(df[df.event_time <= '2000-01-01 00:33:40+00:00'].index, axis=0, inplace=True)
# 保存清洗完的数据,之后以此作为原数据
df.to_csv('ok_data.csv', index=False)

















 1894
1894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









