







文章简介
- 本文主要设计了一种基于Mamba的计算高效的网络架构,将状态空间语言模型 Mamba 移植到 VMamba 中
- 主要由中国科学院、华为、鹏城实验室的研究员提出
问题引入
- 视觉特征学习是计算机视觉的基础研究领域,目前主要使用两种骨干网络,卷积神经网络(CNN)和基于Transformer架构的的ViT;
- ViT的表征能力虽然强,但是计算复杂度是二次的。想寻找一种方法降低ViT的计算复杂度;
- 作者想借鉴从自然语言处理(NLP)领域引入的Mamba方法,但是视觉数据具有非因果性质,直接将Mamba中的选择性扫描机制应用于图像会导致感受野受限。
设计思路
- 在VSS块的基础上开发一系列VMamba架构,这种网络具有线性的时间复杂度;
- 引入二维选择性扫描(SS2D),以弥补一维阵列扫描和二维平面遍历之间的差距,促进选择性 SSM 在处理视觉数据方面的扩展;
- 提出通过新引入的交叉扫描模块(Cross-Scan Module,CSM)来解决方向敏感问题。CSM 不是以单向模式(列向或行向)遍历图像特征映射的空间域,而是采用四向扫描策略,即从特征映射的四个角到相对位置。这种策略确保特征映射中的每个元素从不同方向的所有其他位置集成信息,从而产生全局感受野,而不增加线性计算复杂性。
方法
Vmamba网络架构
我们在三个规模上开发了 VMamba:VMamba-Tiny、VMamba-Small 和 VMamba-Base(分别称为 VMamba-T、VMamba-S 和 VMamba-B)。图 3 (a) 显示了 VMamba-T 架构的概览,输入图像 I ∈ R H × W × 3 I ∈ R^{H×W ×3} I∈RH×W×3 首先由主干模块分割成块,得到空间维度为 H / 4 × W / 4 H/4 × W/4 H/4×W/4 的 2D 特征图。随后,采用多个网络阶段创建分辨率为 H / 8 × W / 8 、 H / 16 × W / 16 H/8 × W/8、H/16 × W/16 H/8×W/8、H/16×W/16 和 H / 32 × W / 32 H/32 × W/32 H/32×W/32 的分层表示。每个阶段都包含一个下采样层(第一阶段除外),后面是一堆视觉状态空间 (VSS) 块。
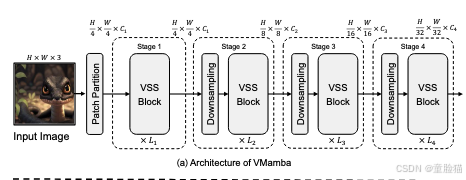
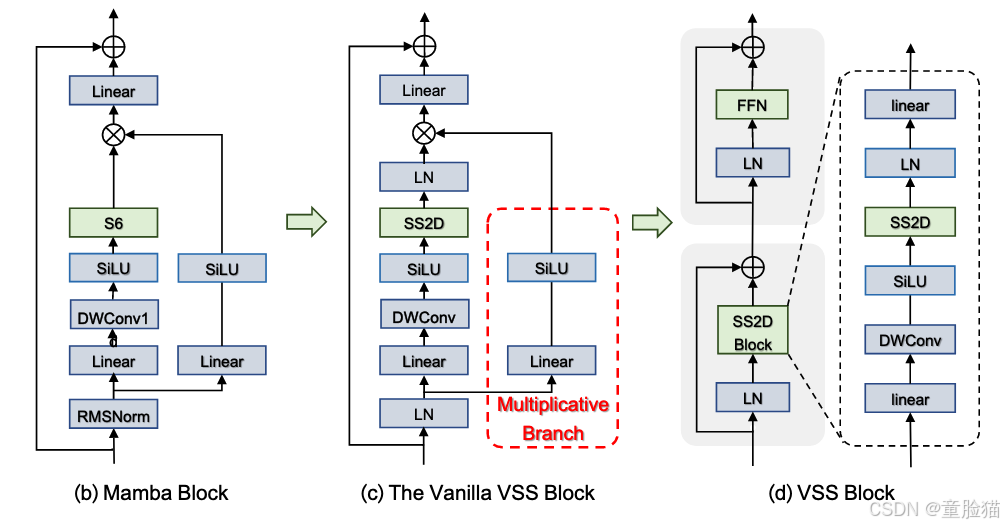
VSS 块是 Mamba 块(图 3(b))的视觉对应物,用于表征学习。VSS 块的初始架构(图 3(c)中称为“原始 VSS 块”)由 S6 模块(Mamba 的核心,可同时实现全局感受野、动态权重(即选择性)和线性复杂度)替换为新提出的 2D 选择性扫描 (SS2D) 模块(将在下一小节中介绍)。为了进一步提高计算效率,我们消除了整个乘法分支(图 3(c)中红框圈出的部分),因为门控机制的效果已通过 SS2D 的选择性实现。因此,最终的 VSS 块(如图 3(d)所示)由一个带有两个残差模块的网络分支组成,模仿原始 Transformer 块的架构 [60]。在本文中,所有结果都是使用此架构中 VSS 块构建的 VMamba 模型获得的。
2D选择性扫描机制(SS2D)
VMamba将选择性扫描机制(S6)作为核心 SSM 运算符,但它以因果方式处理输入数据,因此只能捕获数据的扫描部分内的信息。这使 S6 在应用到非因果数据(例如图像、图形、集合等)时面临重大挑战。解决这个问题的一种直接方法是沿两个不同方向(即前向和后向)扫描数据,允许它们互相补偿而不增加计算复杂性。
尽管图像具有非因果性质,但还有一个与文本的不同之处在于它们包含 2D 空间信息(例如局部纹理和全局结构)。
虽然 S6 中扫描操作的顺序性与涉及时间数据的 NLP 任务非常吻合,但它在应用于视觉数据时带来了重大挑战,因为视觉数据本质上是非顺序的,并且包含空间信息(例如局部纹理和全局结构)。为了解决这个问题,作者使用选择性扫描方法进行输入处理,并提出 2D 选择性扫描 (SS2D) 模块,使 S6 适应视觉数据,而不会损害其优势。
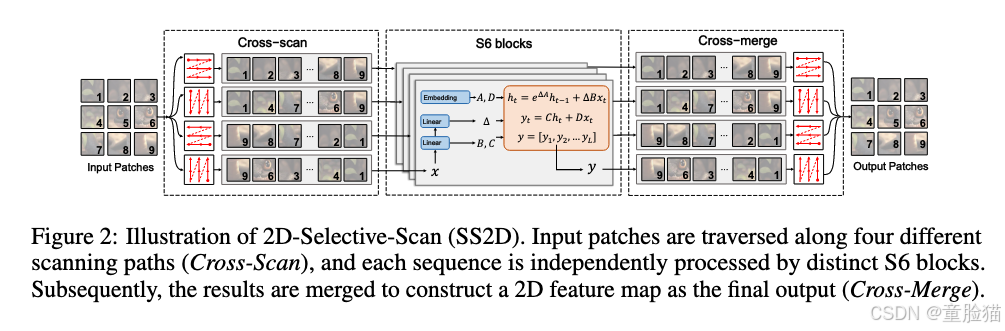
如图 2 所示,SS2D 中的数据转发涉及三个步骤:交叉扫描、使用 S6 块进行选择性扫描和交叉合并。对于输入数据,SS2D 首先将输入的 patch 沿着四条不同的遍历路径展开为序列(即 Cross-Scan),然后使用单独的 S6 block 并行处理每个 patch 序列,随后对得到的序列进行 reshape 和合并以形成输出图(即 Cross-Merge)。通过采用互补的一维遍历路径,SS2D 使图像中的每个像素能够有效地整合来自不同方向的所有其他像素的信息,从而促进在二维空间中建立全局感受野。
加速 VMamba
如图 3 (e) 所示,带有 vanilla VSS 块的 VMamba-T 模型(称为“Vanilla VMamba”)实现了 426 张图像/秒的吞吐量,包含 22.9M 个参数和 5.6G FLOP。尽管分类准确率达到了最先进的 82.2%(在微小级别上,比 Swin-T高出 0.9%),但低吞吐量和高内存开销对 VMamba 的实际部署构成了重大挑战。在本小节中,我们概述了为提高其推理速度所做的努力,主要侧重于实现细节和架构设计的改进。我们通过 ImageNet-1K 上的图像分类来评估模型。每个渐进式改进的影响总结如下,其中 (%, img/s) 分别表示 ImageNet-1K 上的 top-1 准确率和推理吞吐量的增益。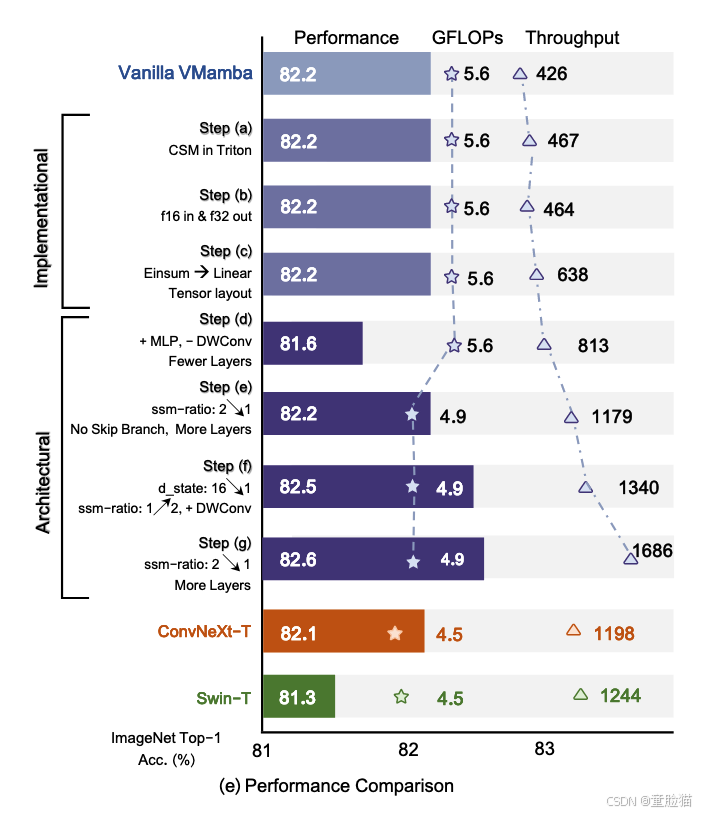
步骤 (a) (+0.0%,+41 图片/秒) 通过在 Triton 中重新实现 Cross-Scan 和 Cross-Merge。
步骤 (b) (+0.0%,-3 图片/秒) 通过调整选择性扫描的 CUDA 实现以适应 float16 输入和 float32 输出。尽管测试时速度略有波动,但这显著提高了训练效率(吞吐量从 165 到 184)。
步骤 © (+0.0%,+174 图片/秒) 通过用线性变换(即 torch.nn. functional.linear)替换选择性扫描中相对较慢的 einsum。我们还采用了 (B, C, H, W) 的张量布局来消除不必要的数据排列。
步骤 (d) (-0.6%,+175 图片/秒) 通过将 MLP 引入 VMamba 来实现,因为它的计算效率更高。我们还丢弃了 DWConv(深度卷积 [24])层,并将层配置从 [2,2,9,2] 更改为 [2,2,2,2],以降低 FLOP。
步骤 (e)(+0.6%,+366 图片/秒)通过丢弃整个乘法分支,采用图 3 (d) 中所示的 VSS 块,并将参数 ssm-ratio(特征扩展因子)从 2.0 降低到 1.0。这使我们能够将层数提高到 [2,2,5,2],同时降低 FLOP。
步骤 (f)(+0.3%,+161 图片/秒)通过将参数 d_state(SSM 状态维度)从 16.0 降低到 1.0。这使我们能够将 ssm-ratio 提高回 2.0 并引入 DWConv 层而不增加 FLOP。
步骤 (g) (+0.1%,+346 张图片/秒),将 ssm 比率降低到 1.0,同时将层配置从 [2,2,5,2] 更改为 [2,2,8,2]。
实验
在本节中,我们进行了一系列实验来评估 VMamba 的性能,并将其与各种视觉任务中的流行基准模型进行比较。我们还通过将所提出的 2D 特征图遍历方法与其他方法进行比较来验证其有效性。此外,我们通过可视化其有效感受野 (ERF) 和激活图来分析 VMamba 的特性,并检查其在越来越长的输入序列下的可扩展性。我们主要遵循 Swin 的超参数设置和实验配置。
所有实验均在具有 8 × NVIDIA Tesla-A100 GPU 的服务器
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









