







 本文介绍了PyTorch的基本概念和安装步骤,包括其由Facebook开发的背景、简洁高效的特点。详细阐述了PyTorch的安装,特别是使用Anaconda创建虚拟环境的流程。此外,还提及了张量、自动求导等核心概念,以及优化器在深度学习中的作用。
本文介绍了PyTorch的基本概念和安装步骤,包括其由Facebook开发的背景、简洁高效的特点。详细阐述了PyTorch的安装,特别是使用Anaconda创建虚拟环境的流程。此外,还提及了张量、自动求导等核心概念,以及优化器在深度学习中的作用。
第一章包括了对于Pytorch的介绍与安装,我这里只简单记录一下自己学习时的笔记。
课程链接
https://gitee.com/datawhalechina/thorough-pytorch/blob/main/%E7%AC%AC%E4%B8%80%E7%AB%A0%20PyTorch%E7%AE%80%E4%BB%8B%E5%92%8C%E5%AE%89%E8%A3%85/1.2%20PyTorch%E7%9A%84%E5%AE%89%E8%A3%85.md
Pytorch的简介
PyTorch是由Facebook人工智能研究小组开发的一种基于Lua编写的Torch库的Python实现的深度学习库,目前被广泛应用于学术界和工业界。PyTorch自从提出就获得巨大的关注以及用户数量的剧增。
它的优势简单来说就是简洁优雅且高效。
Pytorch的安装
早在这门课开课之前,作为菜狗的我已经在网上寻找了一些教程自己动手安装了pytorch。但是这两天还是很认真看了学习的文档。
Step 1:登陆Anaconda | Individual Edition,选择相应系统DownLoad
Step 2:在开始页找到Anaconda Prompt
Step 3:创建虚拟环境
虚拟环境这里相对陌生,所以多花了一些时间。
- 什么是虚拟环境?
虚拟环境是一个虚拟化,从电脑独立开辟出来的环境。通俗的来讲,虚拟环境就是借助虚拟机docker来把一部分内容独立出来,这部分独立出来的东西称作“容器”,在这个容器中,我们可以只安装我们需要的依赖包,各个容器之间互相隔离,互不影响。
- 为什么要使用虚拟环境?
在实际项目开发中,很多项目使用的框架库不一样,或者使用框架的版本不一样,因此如果没有虚拟环境,在开发不同项目时就需要反复卸载重装。
- 虚拟环境的创建、激活、退出、删除
查看已经安装好的虚拟环境
conda env list
创建虚拟环境
conda create -n 虚拟环境名称 python=版本名称
删除虚拟环境命令
conda remove -n 名称 -all
激活环境命令
conda activate 名称
pip换源和conda换源部分没看
我没换源安装的,用conda确实很慢的,而且好几次都会出现一些莫名其妙的问题导致失败,后来换了pip还挺快的。
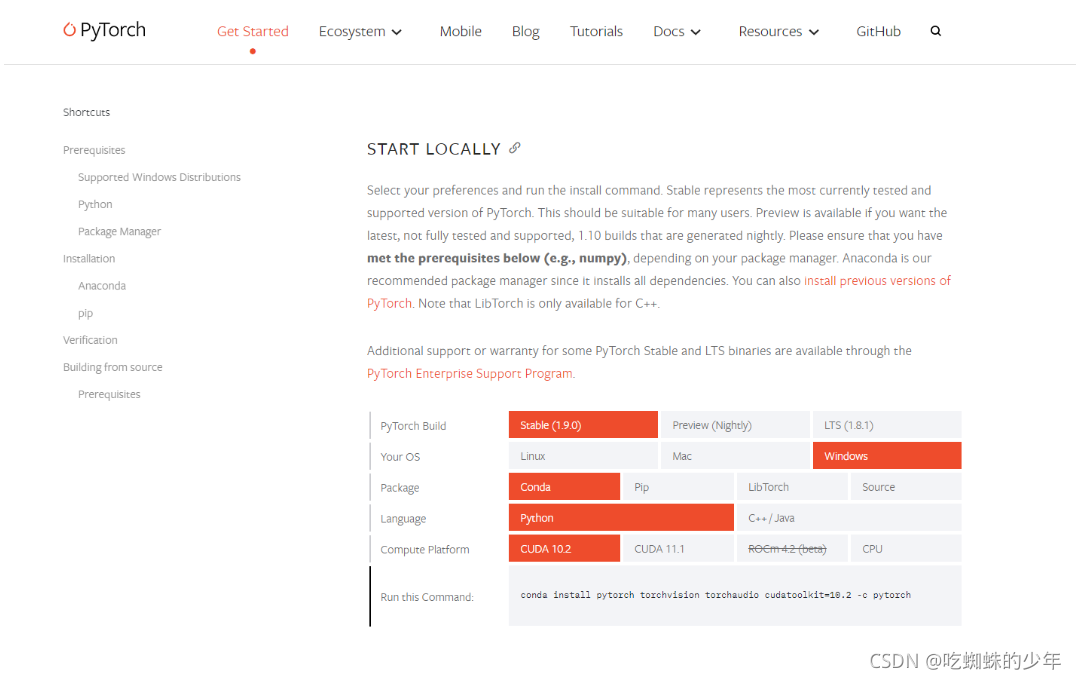
找到pytorch官网,出来这张图就基本上会了。
pip与conda的区别
pip是用来安装python包的,安装的是python wheel或者源代码的包。从源码安装的时候需要有编译器的支持。
conda是用来安装conda package,虽然大部分conda包是python的,但它支持了不少非python语言写的依赖项。
Pytorch基础知识
张量:张量是现代机器学习的基础。它的核心是一个数据容器,多数情况下,它包含数字,有时候它也包含字符串,但这种情况比较少。因此可以把它想象成一个数字的水桶。
创建tensor
from __future__ import print_function
import torch
x = torch.rand(4, 3)
print(x)
常见的构造Tensor的函数:
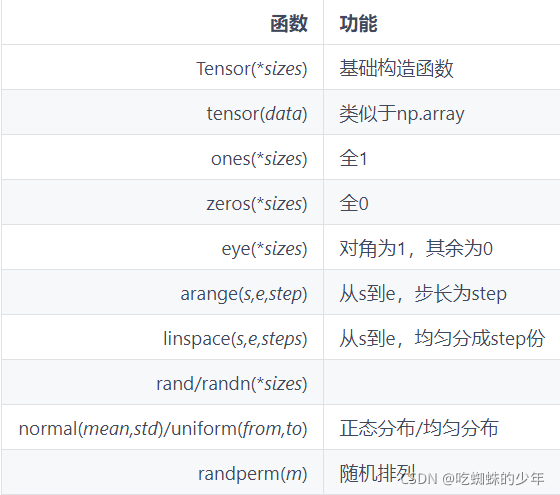
常见操作:
# 方式1
y = torch.rand(4, 3)
print(x + y)
# 方式2
print(torch.add(x, y))
# 方式3 提供一个输出 tensor 作为参数
result = torch.empty(5, 3)
torch.add(x, y, out=result)
print(result)
# 方式4 in-place
y.add_(x)
print(y)
索引:
print(x[:, 1])
y = x[0,:]
y += 1
print(y)
print(x[0, :]) # 源tensor也被改了
x = torch.randn(4, 4)
y = x.view(16)
z = x.view(-1, 8) # -1是指这一维的维数由其他维度决定
print(x.size(), y.size(), z.size())
torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
广播机制
当对两个形状不同的 Tensor 按元素运算时,可能会触发广播(broadcasting)机制:先适当复制元素使这两个 Tensor 形状相同后再按元素运算。
x = torch.arange(1, 3).view(1, 2)
print(x)
y = torch.arange(1, 4).view(3, 1)
print(y)
print(x + y)
自动求导
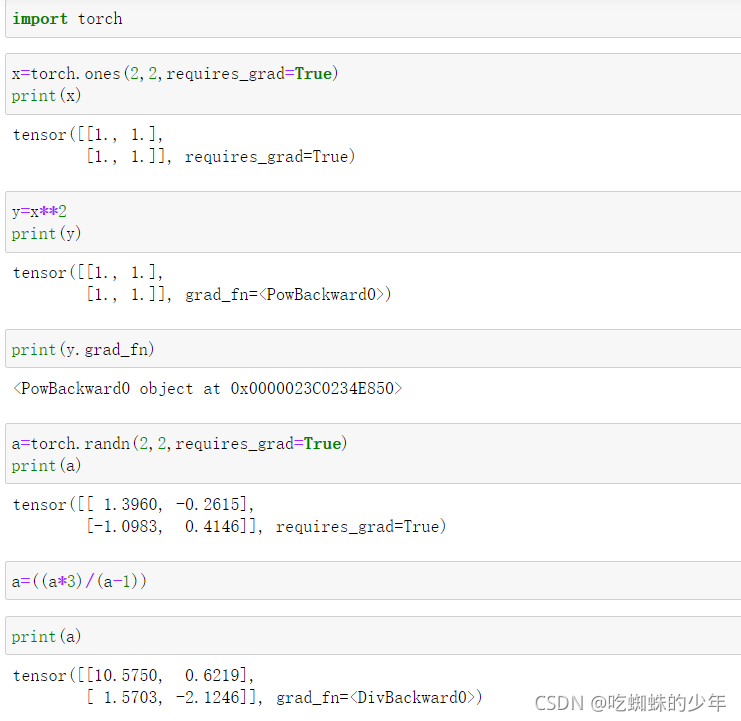
梯度
torch.autograd 这个包就是用来计算一些雅可比矩阵的乘积的。grad在反向传播过程中是累加的(accumulated),这意味着每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需把梯度清零。当y 不是标量,torch.autograd 不能直接计算完整的雅可比矩阵,但是求雅可比向量积,只需将这个向量作为参数传给 backward。如果想要修改 tensor 的数值,但是又不希望被 autograd 记录(即不会影响反向传播), 那么我么可以对 tensor.data 进行操作。
并行计算
并行的方法:
- 网络结构分布到不同的设备中(Network partitioning)
思路:将一个模型的各个部分拆分,然后将不同的部分放入到GPU来做不同任务的计算。 - 同一层的任务分布到不同数据中(Layer-wise partitioning)
思路:同一层的模型做一个拆分,让不同的GPU去训练同一层模型的部分任务。 - 不同的数据分布到不同的设备中,执行相同的任务(Data parallelism)
输入的数据拆分。所谓的拆分数据就是,同一个模型在不同GPU中训练一部分数据,然后再分别计算一部分数据之后,只需要将输出的数据做一个汇总,然后再反传。
ps:现在主流是数据并行的方式。
Pytorch主要组成模块
基本配置
导入需要用到的包
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torch.optim as optimizer
如下几个超参数可以统一设置
batch size
初始学习率(初始)
训练次数(max_epochs)
GPU配置
# 方案一:使用os.environ,这种情况如果使用GPU不需要设置
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
数据读入
PyTorch数据读入是通过Dataset+Dataloader的方式完成的,Dataset定义好数据的格式和数据变换形式,Dataloader用iterative的方式不断读入批次数据。
构建好Datadet后,就可以使用DataLoader来按批次读入数据。
模型构建
import torch
from torch import nn
class MLP(nn.Module):
# 声明带有模型参数的层,这里声明了两个全连接层
def __init__(self, **kwargs):
# 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例例时还可以指定其他函数
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Linear(784, 256)
self.act = nn.ReLU()
self.output = nn.Linear(256,10)
# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出
def forward(self, x):
o = self.act(self.hidden(x))
return self.output(o)
损失函数
二分类交叉熵损失函数
功能:计算二分类任务时的交叉熵(Cross Entropy)函数。在二分类中,label是{0,1}。对于进入交叉熵函数的input为概率分布的形式。一般来说,input为sigmoid激活层的输出,或者softmax的输出。
主要参数: weight:每个类别的loss设置权值
size_average:数据为bool,为True时,返回的loss为平均值;为False时,返回的各样本的loss之和。
reduce:数据类型为bool,为True时,loss的返回是标量。
交叉熵损失函数
功能:计算交叉熵函数
主要参数: weight:每个类别的loss设置权值。
size_average:数据为bool,为True时,返回的loss为平均值;为False时,返回的各样本的loss之和。
ignore_index:忽略某个类的损失函数。
reduce:数据类型为bool,为True时,loss的返回是标量。
L1损失函数
MSE损失函数
平滑L1 (Smooth L1)损失函数
目标泊松分布的负对数似然损失
KL散度
MarginRankingLoss
多标签边界损失函数
二分类损失函数
多分类的折页损失
三元组损失
HingEmbeddingLoss
余弦相似度
CTC损失函数
优化器
深度学习的目标是通过不断改变网络参数,使得参数能够对输入做各种非线性变换拟合输出,本质上就是一个函数去寻找最优解,只不过这个最优解使一个矩阵,而如何快速求得这个最优解是深度学习研究的一个重点,以经典的resnet-50为例,它大约有2000万个系数需要进行计算,那么我们如何计算出来这么多的系数,有以下两种方法:
第一种是最直接的暴力穷举一遍参数,这种方法的实施可能性基本为0,堪比愚公移山plus的难度。
为了使求解参数过程更加快,人们提出了第二种办法,即就是是BP+优化器逼近求解。
因此,优化器就是根据网络反向传播的梯度信息来更新网络的参数,以起到降低loss函数计算值,使得模型输出更加接近真实标签。。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









