







背景知识
词的表示方法
① One-hot Representation 独热表示
优点:表示简单
缺点:词越多,维数越高(词表示大小V)无法表示词与词之间的关系
②SVD
优点:可以一定程度上得到词与词之间的相似度。
缺点:矩阵太大,SVD矩阵分解效率低,学习得到的词向量可解释性差。
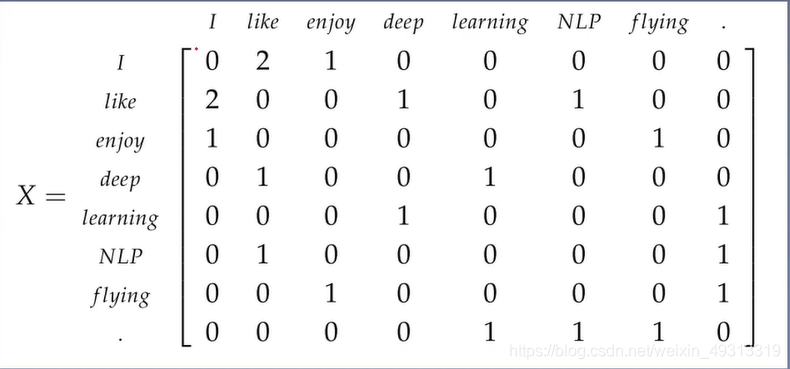
例如:
I enjoy flying
I like NLP
I like deep learning
矩阵如下:统计出来每个词和其他词共现的次数
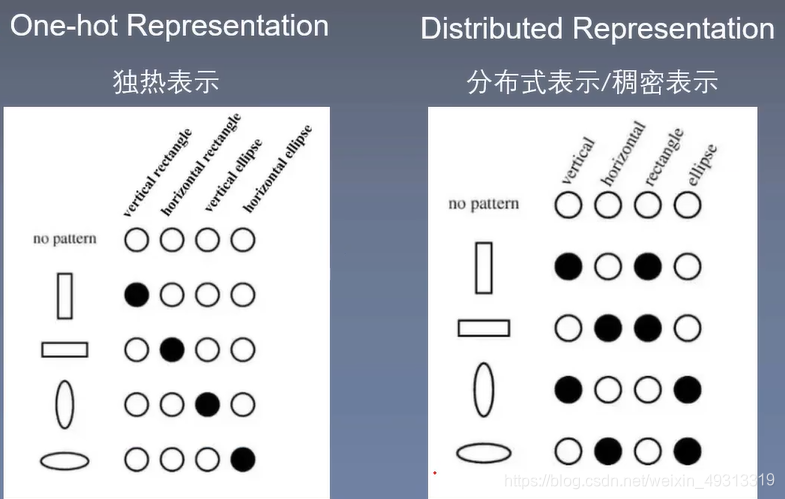
③Distributed Representation分布式表示/稠密表示:
可以用余弦相似度表示词与词之间的关系
One-hot Representation与Distributed Representation的区别

















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









