







 文章介绍了如何使用Pandas库创建和读取Excel文件,包括设置DataFrame的索引,读取文件后查看行数和列名,以及处理行、列和单元格数据。还涉及数据区域的读取、数据类型转换、数据计算、排序、筛选、图表绘制和数据校验等核心功能。
文章介绍了如何使用Pandas库创建和读取Excel文件,包括设置DataFrame的索引,读取文件后查看行数和列名,以及处理行、列和单元格数据。还涉及数据区域的读取、数据类型转换、数据计算、排序、筛选、图表绘制和数据校验等核心功能。
Pandas创建
1、创建excel表格并输入数据
import pandas as pd
import openpyxl
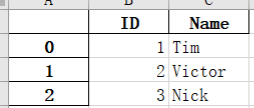
df = pd.DataFrame({'ID':[1,2,3],'Name':['Tim','Victor','Nick']}) //其实就是一个二维表
df.to_excel('output.xlsx') //创建xlsl文件
import pandas as pd
import openpyxl
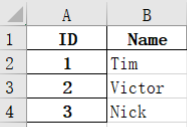
df = pd.DataFrame({'ID':[1,2,3],'Name':['Tim','Victor','Nick']})
df = df.set_index('ID') //将ID设为索引
df.to_excel('output.xlsx')
2、读取文件
people = pd.read_excel('output.xlsx') //读取文件
print(people.shape) //查看excel文件有多少行多少列
输出的结果 (3, 2)
people = pd.read_excel('output.xlsx')
print(people.shape) #输出多少行,多少列
print(people.columns) #输出列名
print(people.head(3)) #输出头三行
print(people.tail(3)) #输出尾三行
people = pd.read_excel('output.xlsx',header=1)
# header = 1 可以处理列向下移的情况
# header = None 不存在列名的情况
# 可以使用people.columns()为其添加列名
df = pd.read_excel()
df.to_excel()
结果可能是这样
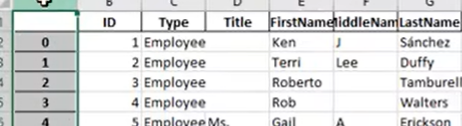
需要设置列的索引,这样就不会有左边的索引了(incex_col = “ID”)
df = pd.read_excel('C:....',index_col = 'ID')
3、行、列、单元格
d = {'x':100,'y':200,'z':300}
s1 = pd.Series(d)
print(s1)
x 100
y 200
z 300
dtype: int64
l1 = [100,200,300]
l2 = ['x','y','z']
s1 = pd.Series(l1,index=l2) #将l2设置为index
print(s1)
x 100
y 200
z 300
dtype: int64
l1 = [1,2,3]
l2 = [10,20,30]
l3 = [100,200,300]
s1 = pd.Series(l1,index=[1,2,3],name='A')
s2 = pd.Series(l2,index=[1,2,3],name='B')
s3 = pd.Series(l3,index=[1,2,3],name='C')
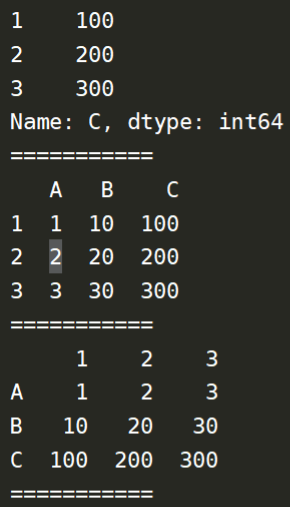
print(s3)
print("===========")
df = pd.DataFrame({s1.name:s1,s2.name:s2,s3.name:s3})
print(df)
print("===========")
df = pd.DataFrame([s1,s2,s3])
print(df)
print("===========")
4、数据区域读取 与 填充数据
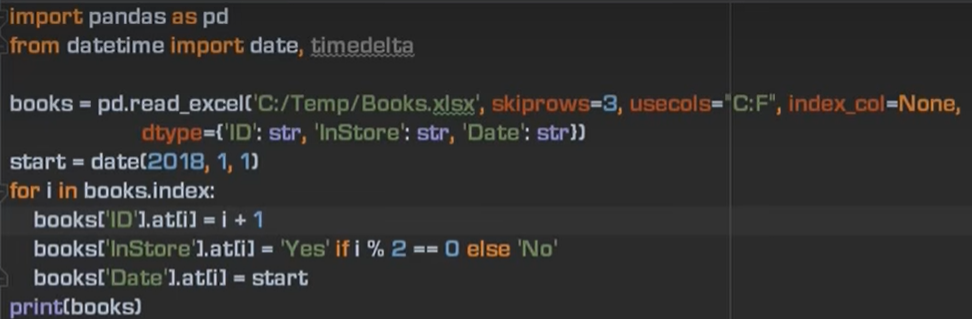
skiprows = 3 跳过前三行
usecols = “C:F” 读取C到F列
dtype={‘ID’:str,‘InStore’:str,‘Date’:str} 将他们的类型都设置为str类型
books[“ID”].at[1] = 100 将ID这个列的第一行设置为100
date的日期那里只是一个格式嘛。
操作日
start + i
操作年
date(start.year + i,start.month,start.day)
操作月

5、对行进行计算
books['ListPrice'] = book['ListPrice'] * 0.8
6、排序 与 多重排序
sort_values()

7、多重筛选
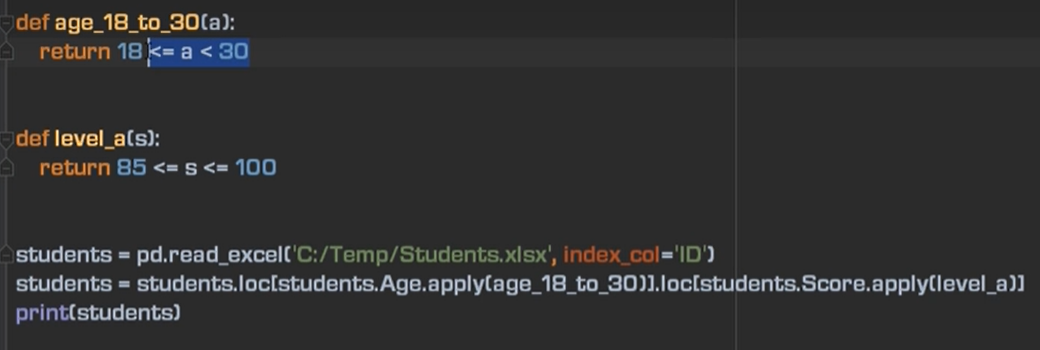
优化代码

8、画一个柱状图
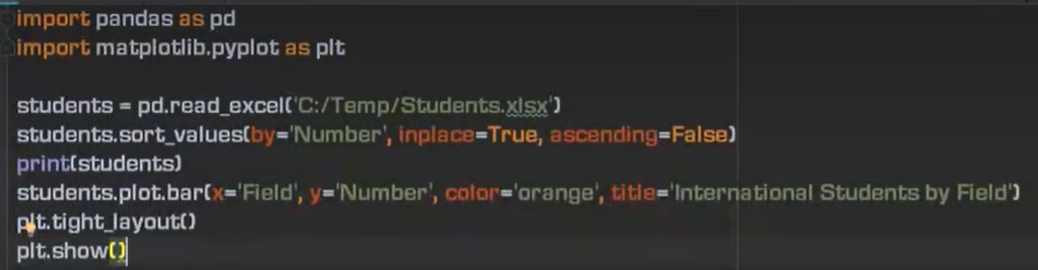
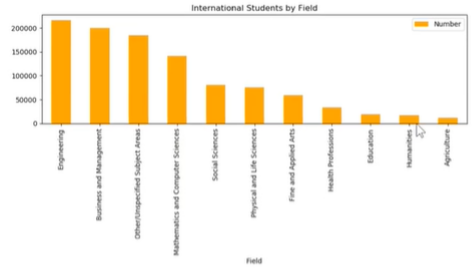
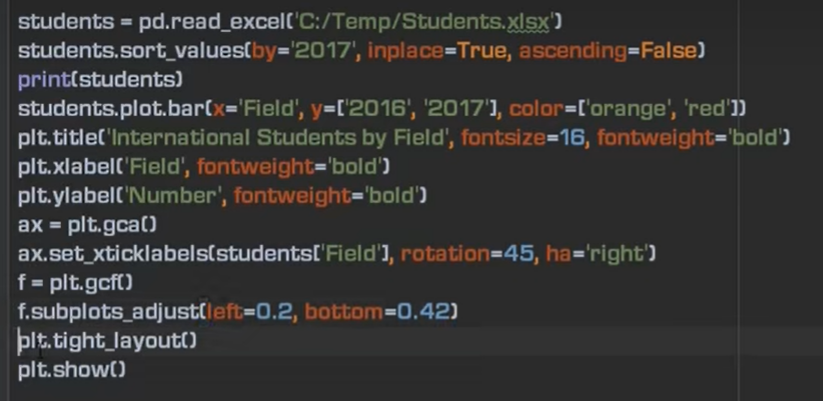
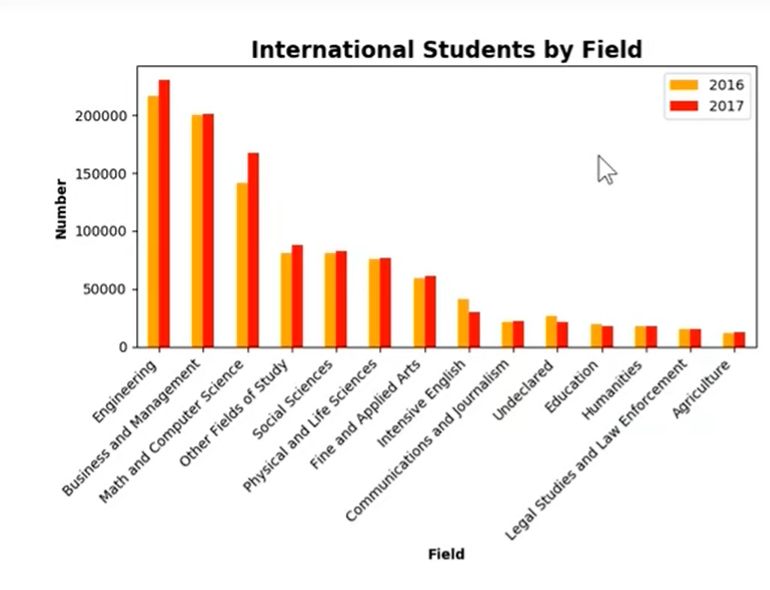
方法二
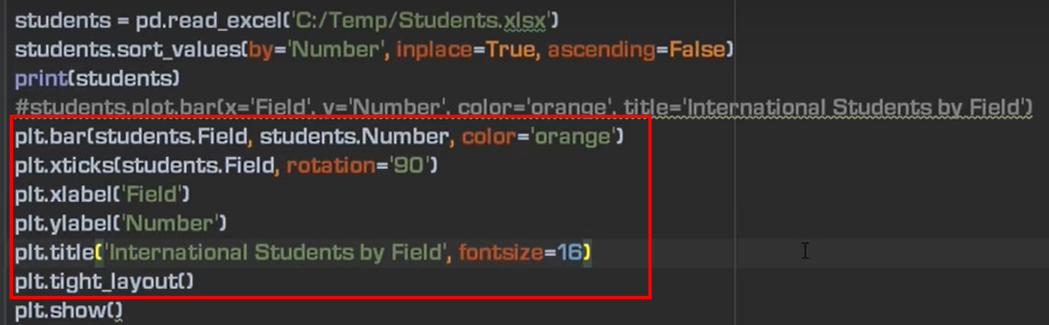
多条柱状图
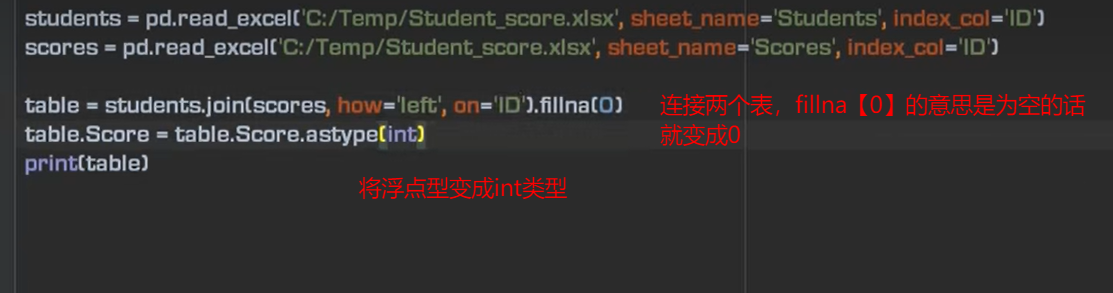
9、两张表进行join
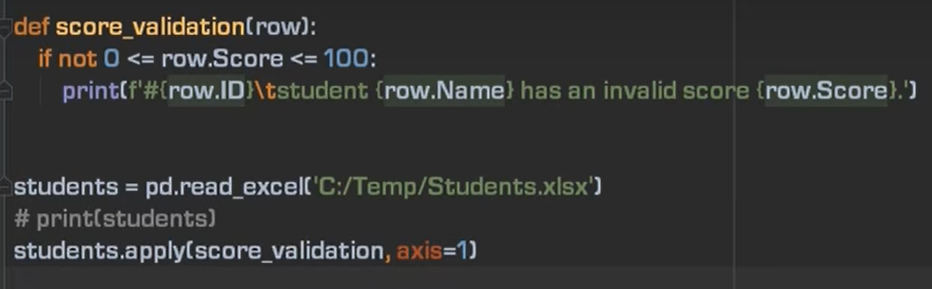
10、数据校验
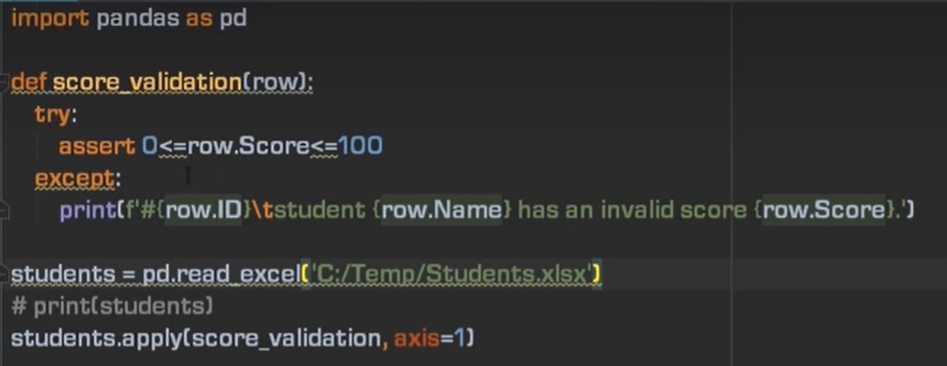
第二种方法
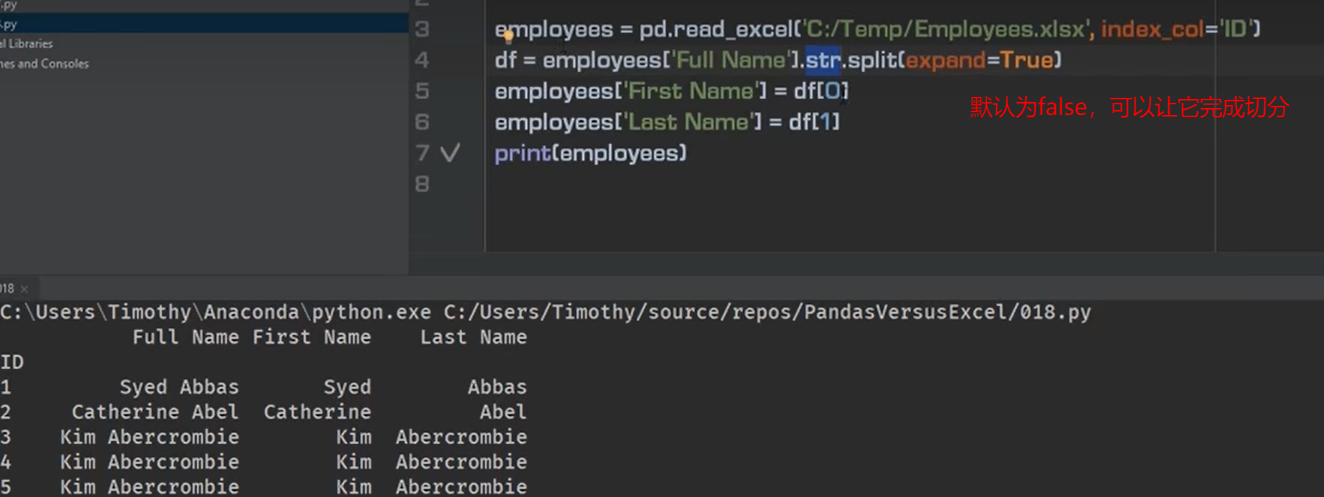
axis:为0的时候,从上到下,为1的时候,从左到右
切分
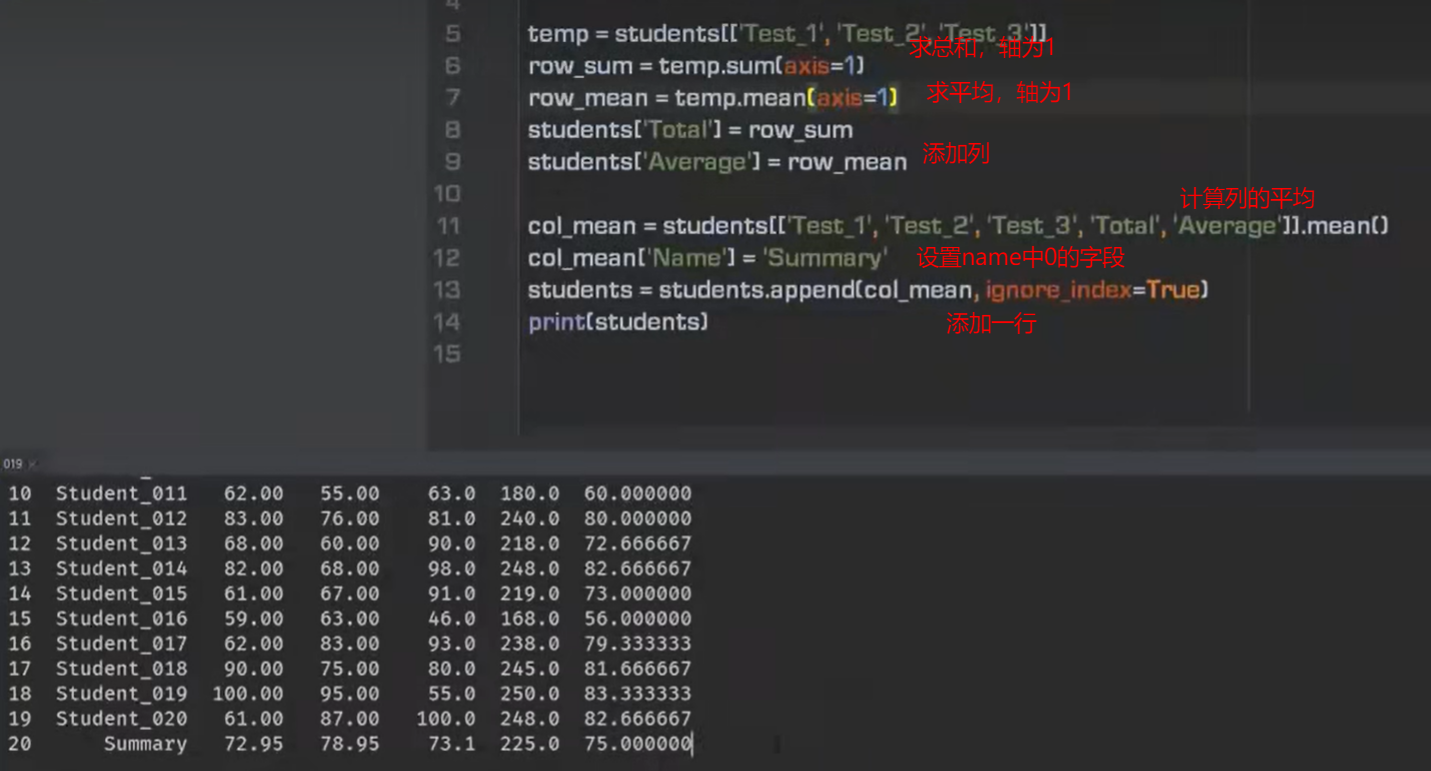
求和求平均
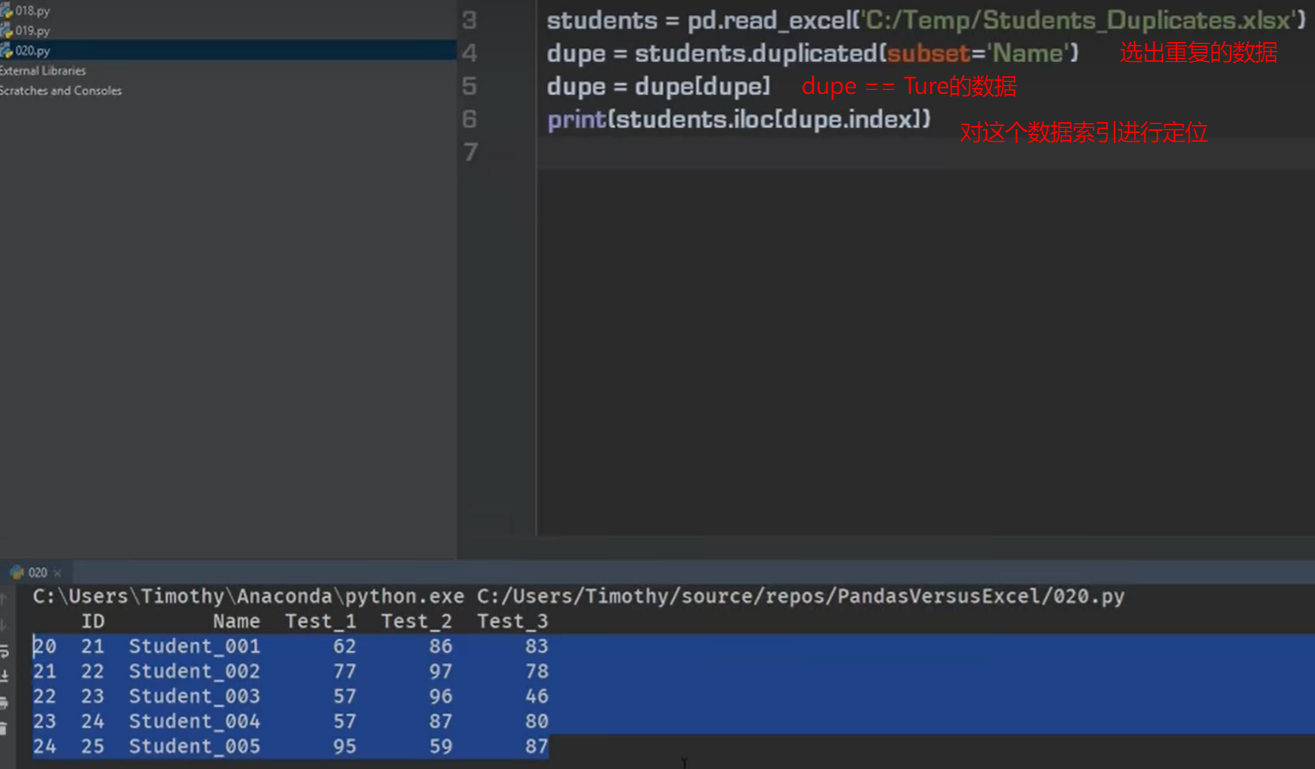
消除重复数据 、 保留重复数据
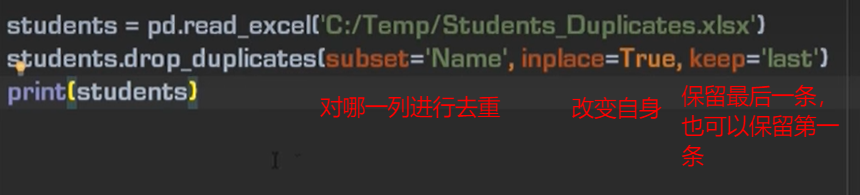
保留重复数据
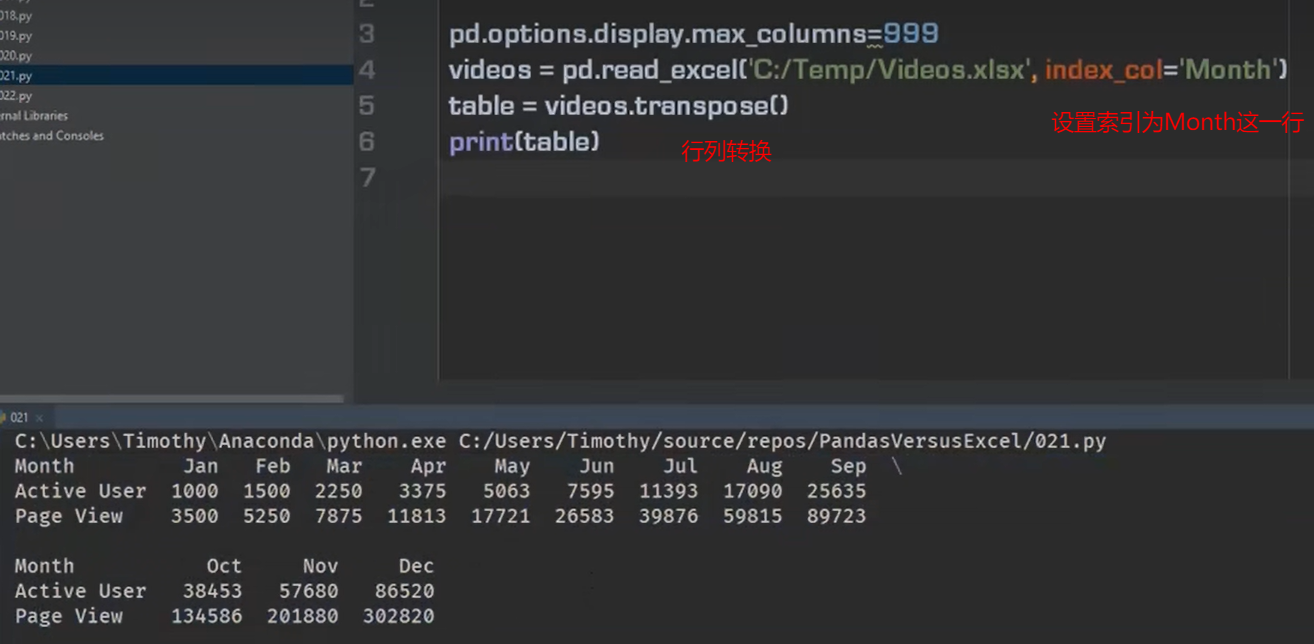
行列转换

















 2565
2565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









