







文章目录
CAGC:用于多模态意图识别的上下文增强全局对比
总结:CAGC 在两个方面进行了创新,分别是跨视频上下文学习(用于捕捉长上下文依赖关系)与全局上下文引导的对比学习(减少模态差异并增强跨模态对齐)。针对每一个视频数据,构建相对应的跨视频库,然后依据跨视频库来学习到长上下文特征。在对每一个视频数据进行意图识别时,每个视频数据所对应的长上下文特征用于给予一定的上下文提示,进而使得意图识别更加准确。(解释:在看电影片段时,只通过看某一段视频可能无法很好的理解此视频,但是结合整个电影便可以实现较好的理解。也就是我们常说的只见树木,不见森林,强调了在理解事物时,局部和整体之间的关系,只有结合整体才能更好地理解局部的意义。)
一、文章信息
作者:Kaili Sun,Mang Ye
单位:武汉大学
会议/期刊: Computer Vision and Pattern Recognition 2024(CVPR)
题目:Contextual Augmented Global Contrast for Multimodal Intent Recognition
发布日期:2024 年 6 月 17 日
代码:暂未公布
数据集:MIntRec、CMU-MOSI
算力要求:未说明
二、研究目的
旨在通过解决意图歧义、对全局信息进行建模以及开发一种通过有效的情境特征提取来增强性能的可靠方法来改善多模态意图识别。
三、研究内容
提出了一种上下文增强全局对比(CAGC)方法。CAGC 包括两个主要部分:上下文增强转换器 (CAT) 模块和全局上下文引导对比学习 (GCCL) 方案。主要想法是探索丰富而全面的上下文特征,以解决意图识别中的不确定性问题。CAT 的目的是通过同时挖掘视频内和跨视频的上下文关系来学习精炼的全局上下文相关特征,从而减少意图理解中的偏差。为了确保有效的跨视频来源,作者进一步设计了一个跨视频库,该库同时考虑了视频间的意图倾向和相似性。该库可以帮助模型避免和减轻无关视频带来的错误积累,从而确保更精确的跨视频上下文特征学习。GCCL 旨在捕捉稳健一致且具有区分性的跨模态特征,并减少模态差异。该方案纳入了全局上下文信息作为监督,以改进跨模态对齐。
- 提出了一种上下文增强全局对比(CAGC)学习方法,从视频内部和跨视频中挖掘丰富的全局上下文线索,以增强对 MIR 的意图理解。
- 设计了一个上下文增强转换器模块来学习跨视频上下文相关特征,以减少意图理解中的偏差。此外,还引入了一种全局上下文引导的对比学习方案,以捕捉稳健的一致性和跨模态判别特征,减少模态差异。
- 在公共基准 MIR 数据集上进行了大量实验,取得了优于同行的性能。此外,还在一个广泛使用的多模态情感数据集上取得了与之相当的性能。
四、研究方法
1. 总体结构
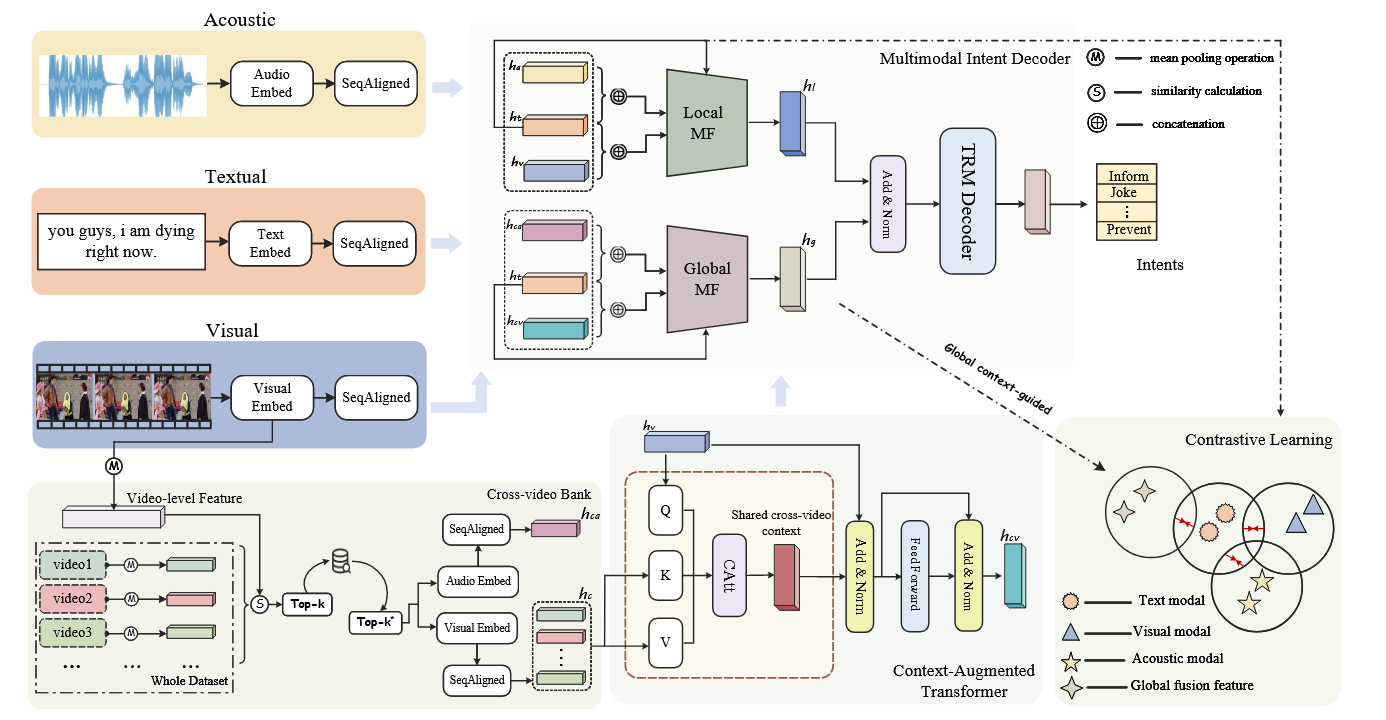
CAGC 主要由四个部分组成:多模态编码器、跨视频上下文学习、多模态意图解码器和全局上下文引导的对比学习。考虑到每种模态原本处于不同的特征空间,通过多模态编码器创建统一的模态表示。为了获得细化的长距离上下文相关特征,作者设计了跨视频上下文学习,其中包括跨视频库和上下文增强转换模块。然后,融合来自局部和全局视角的特征,以捕捉全面的多模态表征并进行意图解码。此外,为了减少模态差异并增强跨模态对齐,提出了一种全局上下文引导的对比学习方案。
2. 多模态编码器
利用预训练的 BERT 对输入文本进行初始化,并从最后一层的输出中提取标记嵌入。对于声学和视觉输入,使用预先训练好的 wav2vec 和 ResNet 模型来获取信号级声学和帧级视觉特征表征。
m
t
=
T
e
x
t
E
m
b
e
d
(
L
)
,
m
a
=
A
u
d
i
o
E
m
b
e
d
(
A
)
,
m
v
=
V
i
d
e
o
E
m
b
e
d
(
V
)
,
\begin{gathered} m_{t} =TextEmbed(L), \\ m_{a} =AudioEmbed(A), \\ m_{v} =VideoEmbed(V), \end{gathered}
mt=TextEmbed(L),ma=AudioEmbed(A),mv=VideoEmbed(V),
为了形成统一的多模态特征表征,利用连接时序分类 CTC 模块对词级序列进行对齐。计算公式如下:
h
t
,
h
a
,
h
v
=
S
e
q
A
l
i
g
n
e
d
(
m
t
,
m
a
,
m
v
)
,
h_t,h_a,h_v=SeqAligned(m_t,m_a,m_v),
ht,ha,hv=SeqAligned(mt,ma,mv),
| 符号 | 含义 | |
|---|---|---|
| m t , m v , m v m_t,m_v,m_v mt,mv,mv | 浅层模态特征表征 | |
| h t , h a , h v h_t,h_a,h_v ht,ha,hv | 单模态特征表征 |
3. 跨视频上下文学习(Cross-video Context Learning)
跨视频上下文学习(Cross-video context learning)包括跨视频库(the cross-video bank)和上下文增强变换器模块(the context-augmented transformer module)。跨视频库旨在检索有效的视频资源,并减轻无关视频的干扰。上下文增强变换器模块基于跨视频库捕捉精炼的全局上下文依赖。
3.1 Cross-video Bank 结构

跨视频库构建分为两个阶段:阶段1的初始建立过程和阶段2的去噪过程。
阶段1:存储每个视频及其与之共享高度相似场景信息的视频,这些视频是在整个训练数据集中筛选出来的。场景相似性是基于视频级特征定义的,这些特征被视为潜在场景信息。具体来说,给定一个由一系列帧
v
i
=
{
v
i
f
r
a
m
(
j
)
}
j
=
1
F
.
v_i{=}\{v_i^{fram(j)}\}_{j=1}^F.
vi={vifram(j)}j=1F.组成的视频
v
i
v_i
vi。
v
‾
i
=
1
F
∑
j
=
1
F
(
v
i
f
r
a
m
(
j
)
)
,
\overline{v}_i=\frac1F\sum_{j=1}^F(v_i^{fram(j)}),
vi=F1j=1∑F(vifram(j)),
然后根据场景相似度得分获得跨视频集
Ω
(
v
‾
i
)
\Omega(\overline{v}_i)
Ω(vi),该得分定义为L2距离。公式如下:
v
c
i
∈
Ω
(
v
i
)
:
=
[
∑
t
=
1
T
(
v
‾
c
t
−
v
‾
i
t
)
2
]
k
,
v_c^i\in\Omega(v_i):=\left[\sum_{t=1}^T(\overline{v}_c^t-\overline{v}_i^t)^2\right]_k,
vci∈Ω(vi):=[t=1∑T(vct−vit)2]k,
阶段2:对跨视频库进行去噪。它旨在减少误差累积和干扰。具体来说,通过采用投票原则,从具有相同意图的集
Ω
(
v
i
)
\Omega(v_i)
Ω(vi)中选择视频,从而获得具有一致意图倾向的视频。最终的跨视频集表示为
Ω
∗
(
v
i
)
=
{
v
c
i
(
1
)
,
v
c
i
(
2
)
,
.
.
.
,
v
c
i
(
k
∗
)
}
(
1
≤
k
∗
≤
k
)
\Omega^*(v_i)=\{v_c^{i(1)},v_c^{i(2)},...,v_c^{i(k^*)}\}(1\leq k^*\leq k)
Ω∗(vi)={vci(1),vci(2),...,vci(k∗)}(1≤k∗≤k) ,其与视频
v
i
v_i
vi共享相似的意图倾向。然后
Ω
∗
(
v
i
)
\Omega^*(v_i)
Ω∗(vi)依次存储到库中。
| 符号 | 含义 |
|---|---|
| v ‾ i \overline{v}_i vi | 视频级特征(video-level feature) |
| F F F | 帧数量 |
| T T T | v ‾ i \overline{v}_i vi的维度 |
| [ ⋅ ] k [\cdot]_{k} [⋅]k | 表示得分最低的前k个视频 |
| Ω ( v i ) = { v c i ( 1 ) , v c i ( 2 ) , . . . , v c i ( k ) } \Omega(v_i)=\{v_c^{i(1)},v_c^{i(2)},...,v_c^{i(k)}\} Ω(vi)={vci(1),vci(2),...,vci(k)} | 与 v i v_i vi 相对应的跨视频集。 |
3.2 Context-augmented Transformer 结构

上下文增强的transformer旨在捕捉全局长范围上下文依赖特征,以减轻意图理解中的模糊性。与典型的transformer 相比,上下文增强的注意力机制是基于跨视频库C设计的,如算法1所述。它利用了一种增强的学习方式,逐步增强长范围的上下文学习。
h
m
=
C
A
t
t
(
h
v
,
h
c
,
h
c
)
,
h
m
v
=
f
n
(
h
m
+
h
v
)
,
h
c
v
=
f
n
(
f
(
h
m
v
)
+
h
m
v
)
,
h_m=CAtt(h_v,h_c,h_c),\\h_{mv}=f_n(h_m+h_v),\\h_{cv}=f_n(f(h_{mv})+h_{mv}),
hm=CAtt(hv,hc,hc),hmv=fn(hm+hv),hcv=fn(f(hmv)+hmv),
| 符号 | 含义 |
|---|---|
| C A t t ( ⋅ ) CAtt(\cdot) CAtt(⋅) | 上下文增强注意机制 |
| h c = { h c i } i = 1 N , h c i ∈ { h c i ( 1 ) , h c i ( 2 ) , . . . , h c i ( k ∗ ) } h_{c}=\left\{h_{c}^{i}\right\}_{i=1}^{N}, h_{c}^{i} \in \{h_{c}^{i(1)},h_{c}^{i(2)},...,h_{c}^{i(k^{*})}\} hc={hci}i=1N,hci∈{hci(1),hci(2),...,hci(k∗)} | 跨视频集 Ω ∗ ( v i ) ( 1 ≤ i ≤ N ) \Omega^*(v_i)(1\leq i\leq N) Ω∗(vi)(1≤i≤N)的视觉特征表征 |
| h c v h_{cv} hcv | 捕获到的长上下文依赖特征 |
| f n ( ⋅ ) f_{n}(\cdot) fn(⋅) | 归一化层 |
| f ( ⋅ ) f(\cdot) f(⋅) | 线性融合层 |
4. 多模态意图解码器

在局部多模态融合中,将文本模态特征与视觉和听觉模态特征结合起来:
h
l
f
=
(
f
w
(
[
h
t
,
h
v
]
)
∘
f
(
h
v
)
+
f
w
(
[
h
t
,
h
a
]
)
∘
f
(
h
a
)
)
,
h
l
=
f
′
(
h
t
,
h
l
f
)
∘
h
l
f
,
h_{lf}=(f_w([h_t,h_v])\circ f(h_v)+f_w([h_t,h_a])\circ f(h_a)),\\h_{l}=f^{\prime}(h_t,h_{lf})\circ h_{lf},
hlf=(fw([ht,hv])∘f(hv)+fw([ht,ha])∘f(ha)),hl=f′(ht,hlf)∘hlf,
在全局多模态融合中,文本模态特征与跨视频视觉和声学模态特征相结合:
h
g
f
=
(
f
w
(
[
h
t
,
h
c
v
]
)
∘
f
(
h
c
v
)
+
f
w
(
[
h
t
,
h
c
a
]
)
∘
f
(
h
c
a
)
)
,
h
g
=
f
′
(
h
t
,
h
g
f
)
∘
h
g
f
,
h_{gf}=(f_w([h_t,h_{cv}])\circ f(h_{cv})+f_w([h_t,h_{ca}])\circ f(h_{ca})),\\h_{g}=f^{\prime}(h_{t},h_{gf})\circ h_{gf},
hgf=(fw([ht,hcv])∘f(hcv)+fw([ht,hca])∘f(hca)),hg=f′(ht,hgf)∘hgf,
最后,对局部和全局多模态融合特征进行意图解码:
h
o
u
t
=
T
R
M
(
f
n
(
h
l
+
h
g
)
)
,
h_{\boldsymbol{out}}=TRM(f_n(h_l+h_g)),
hout=TRM(fn(hl+hg)),
| 符号 | 含义 |
|---|---|
| h l h_l hl | 局部多模态融合特征 |
| h w ( ⋅ ) h_w(\cdot) hw(⋅) | 门函数 |
| f ′ ( ⋅ ) f^{\prime}(\cdot) f′(⋅) | 非线性函数 |
| ∘ \circ ∘ | 逐元素乘法 |
| h g h_g hg | 全局多模态融合特征 |
| T R M ( ⋅ ) TRM(\cdot) TRM(⋅) | 意图解码器 |
5. 全局上下文引导的对比学习
将文本模态作为锚点,而将其他两种模态作为其增强版本。对于局部对比度,将文本模态特征与其他两种模态特征进行对齐。对于全局对比,将文本模态特征与全局多模态融合特征进行对齐。
-
局部对比,正负样本对是根据迷你批次中的视频构建的。具体来说,以文本模态特征 h t h_t ht 为锚。
-
正样本集 P l \mathcal{P}_l Pl 包括:1) 从具有相同意图标签的其他视频中提取声学模态特征;2)从具有相同意图标签的其他视频中提取视觉模态特征;(局部,类内,样本间正对)
-
负样本集 N l \mathcal{N}_l Nl 包括:1)来自其他视频的声学模态特征,其意图标签不同;2)来自其他具有不同意图标签的视频的视觉模态特征。(局部,类间,样本间负对)
-
采用 InfoNCE 损失计算局部对比损失:
L t a = − log ∑ h a + ∈ P l exp ( h t ⋅ h a + / τ ) ∑ h a ± ∈ P l ∪ N l exp ( h t ⋅ h a ± / τ ) , L t v = − log ∑ h v + ∈ P l exp ( h t ⋅ h v + / τ ) ∑ h v ± ∈ P l ∪ N l exp ( h t ⋅ h v ± / τ ) . \begin{gathered} \mathcal{L}_{ta} =-\log\frac{\sum_{h_a^+\in\mathcal{P}_l}\exp(h_t\cdot h_a^+/\tau)}{\sum_{h_a^\pm\in\mathcal{P}_l\cup\mathcal{N}_l}\exp(h_t\cdot h_a^\pm/\tau)}, \\ \mathcal{L}_{tv} =-\log\frac{\sum_{h_v^+\in\mathcal{P}_l}\exp(h_t\cdot h_v^+/\tau)}{\sum_{h_v^\pm\in\mathcal{P}_l\cup\mathcal{N}_l}\exp(h_t\cdot h_v^\pm/\tau)}. \end{gathered} Lta=−log∑ha±∈Pl∪Nlexp(ht⋅ha±/τ)∑ha+∈Plexp(ht⋅ha+/τ),Ltv=−log∑hv±∈Pl∪Nlexp(ht⋅hv±/τ)∑hv+∈Plexp(ht⋅hv+/τ).
-
-
全局对比,正负样本对是从整个数据集中跨视频构建的。具体来说,以文本模态特征 h t h_t ht 为锚。
-
正样本集 P g \mathcal{P}_g Pg 包括:跨视频具有相同意图标签的全局多模态融合特征。(全局,类内,样本间正对)
-
负样本集 N g \mathcal{N}_g Ng 包括:跨视频具有不同意图标签的全局多模态融合特征。(全局,类间,样本间负对)
-
同样采用 InfoNCE 损失计算全局对比损失:
L g = − log ∑ h g + ∈ P g exp ( h t ⋅ h g + / τ ) ∑ h g ± ∈ P g ∪ N g exp ( h t ⋅ h g ± / τ ) . \mathcal{L}_g=-\log\frac{\sum_{h_g^+\in\mathcal{P}_g}\exp(h_t\cdot h_g^+/\tau)}{\sum_{h_g^\pm\in\mathcal{P}_g\cup\mathcal{N}_g}\exp(h_t\cdot h_g^\pm/\tau)}. Lg=−log∑hg±∈Pg∪Ngexp(ht⋅hg±/τ)∑hg+∈Pgexp(ht⋅hg+/τ).
-
6. 训练损失
q = f c ( h o u t ) , L t a s k = − ∑ i = 1 N ( p ( i ) ∘ log ( q ( i ) ) ) L t o t a l = L t a s k + α ( L t a + L t v ) + β L g , q=f_c(h_{out}),\\\mathcal{L}_{task}=-\sum_{i=1}^N\left(p(i)\circ\log(q(i))\right)\\\mathcal{L}_{total}=\mathcal{L}_{task}+\alpha(\mathcal{L}_{ta}+\mathcal{L}_{tv})+\beta\mathcal{L}_g, q=fc(hout),Ltask=−i=1∑N(p(i)∘log(q(i)))Ltotal=Ltask+α(Lta+Ltv)+βLg,
| 符号 | 含义 |
|---|---|
| f c ( ⋅ ) f_c(\cdot) fc(⋅) | 用于分类的线性函数 |
| L t a s k \mathcal{L}_{task} Ltask | 意图预测的损失 |
| p ( i ) p(i) p(i) | 真实意图的分布 |
| L t o t a l \mathcal{L}_{total} Ltotal | 整体训练损失 |
五、实验分析
- 与现有最先进的模型相比,CAGC在准确性和其他指标上有了显着提高,证明了其在意图识别方面的有效性。
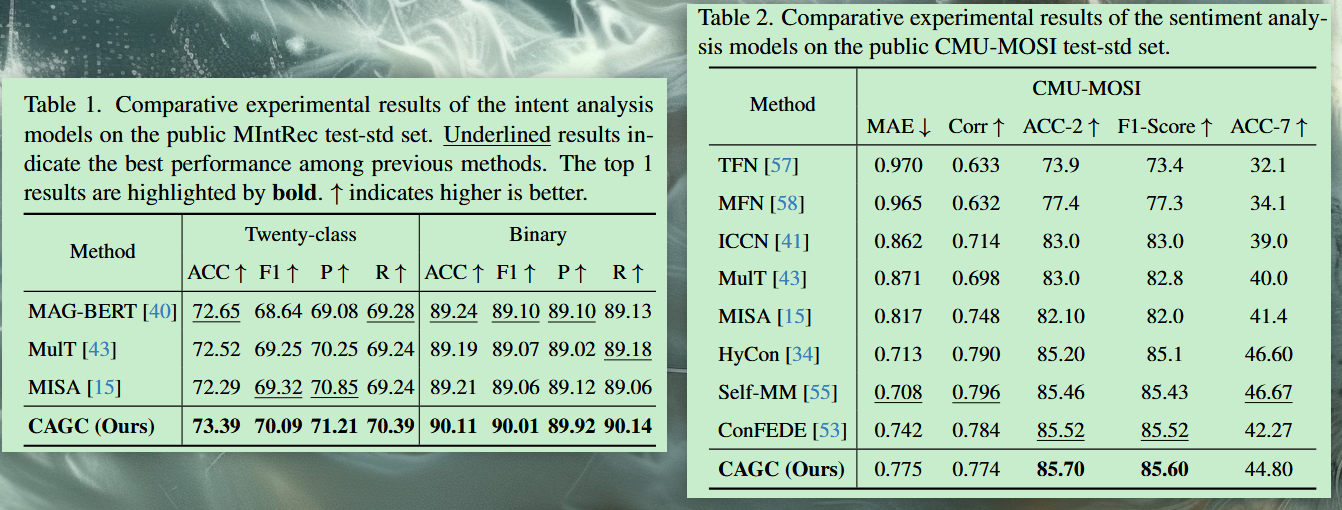
- 跨视频上下文特征提取器显著提高了模型性能,突出了精细视觉交互的重要性。从学习方案中去除全局或局部对比都会导致准确性下降,这表明两种对比在增强特征鲁棒性方面的互补作用。

- 进行了示例研究。示例说明了该模型如何利用文本、视觉和声学模态来推断意图,展示了模糊意图场景的挑战。CAGC 可以有效地从交叉视频中捕获全局上下文,通过提供上下文线索来帮助准确的意图推理。

😃😃😃


















 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









