







深度学习调参技巧总结
1.寻找合适的学习率
学习率(Learning Rate, LR)是机器学习模型训练中极其重要的超参数。它直接影响模型的收敛速度和最终的性能表现。由于不同的模型规模、batch-size、优化方法和数据集的差异,最合适的学习率值往往是不确定的,因此很难仅凭经验确定最佳学习率。解决方法是通过训练过程中的动态调整,不断探索和寻找适合当前模型状态的学习率,以确保高效且稳定的模型优化。
- 采用较大的batch-size,只要不超出显存就可以。
- 越大的batch-size使用越大的学习率,反之亦然。
2.优化算法选择
不同的优化算法按理说适合不同的任务,但在实际应用中常用的还是 Adam 和 SGD+Momentum。
Adam 可以解决许多奇怪的问题(例如 loss 降不下去时,换成 Adam 往往会迅速改善),但也可能引发一些意想不到的问题(例如,单词词频差异较大时,即使当前 batch 中没有某个单词,它的词向量也会被更新;或者在与 L2 正则结合时产生复杂效果)。使用 Adam 时需要谨慎,一旦出现问题,可以尝试各种改进版 Adam(如 MaskedAdam、AdamW 等)来应对。不过,一些博客指出,虽然 Adam 收敛快,但其泛化能力不如 SGD,想要取得更优结果可能需要精细调参 SGD。Adam 和 Adadelta 在小数据集上的效果不如 SGD。虽然 SGD 的收敛速度较慢,但最终的收敛结果通常更好。如果使用 SGD,可以从较大的学习率(如 1.0 或 0.1)开始,定期在验证集上检查 cost,如果不再下降,则将学习率减半。我看到过很多论文采用这种策略,自己实验的效果也很不错。当然,也可以先用自适应优化器(如 Ada 系列)进行初期训练,接近收敛时再切换到 SGD,这样也能带来提升。有研究表明,Adadelta 在分类问题上表现较好,而 Adam 则更适合生成任务。虽然 Adam 收敛更快,但得到的解往往不如 SGD+Momentum 稳定,如果不急于求成,选择 SGD 可能是更好的选择。Adam 不需要频繁调整学习率,而 SGD 则需要更多时间来调节学习率和初始权重。
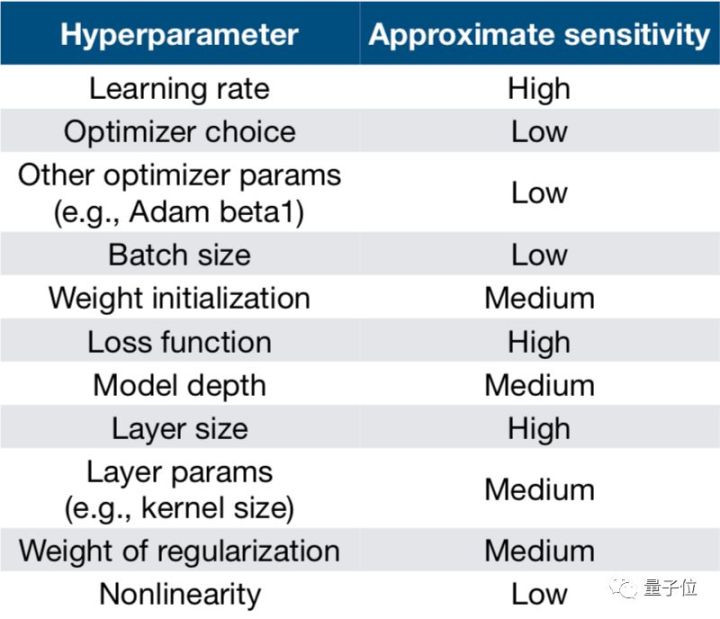
3.模型对不同超参数的敏感性
常用的超参数优化方法有:手动优化、网格搜索、随机搜索、由粗到细、贝叶斯优化。
4.训练技巧
- Dropout 对小数据防止过拟合有很好的效果,值一般设为0.5。
- Adam 不需要频繁调整学习率,而 SGD 则需要更多时间来调节学习率和初始权重。
- 小数据集上 Dropout+SGD 效果提升都非常明显,因此可能的话,建议一定要尝试一下。
- 除了gate之类的地方,需要把输出限制成0-1之外,尽量不要用sigmoid激活函数。可以用tanh或者relu之类的激活函数。
- 超参上,learning rate 最重要,推荐了解 cosine learning rate 和 cyclic learning rate,其次是 batchsize 和 weight decay。当模型还不错的时候,就可以试着做数据增广和改损失函数锦上添花了。
参考
😃😃😃


















 356
356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









