







文章目录
EMT-DLFR:双层次特征修复的高效多模态变压器用于稳健的多模态情感分析
总结:多模态融合时,采用Global-Local的融合策略,利用MPU单元,实现模态的融合。
文章信息
作者:Licai Sun,Bin Liu
单位:University of Chinese Academy of Sciences(中国科学院大学)
会议/期刊:IEEE Transactions on Affective Computing
题目:Efficient Multimodal Transformer with Dual-Level Feature Restoration for Robust Multimodal Sentiment Analysis
年份:2023
研究目的
解决多模态情感分析的两个问题:① MSA 在未对齐的多模态数据集中建立跨模态交互模型(cross-modal interactions )效率低下。② MSA 易受随机模态特征缺失的影响。
-
未对齐的多模态数据集示例:
 三个模态的序列长度不一致。
三个模态的序列长度不一致。 -
随机模态特征缺失示例:
 模态数据不完整(灰色部分代表缺失的模态特征)。
模态数据不完整(灰色部分代表缺失的模态特征)。
研究内容
提出了一个通用的框架 EMT-DLFR ,实现未对齐多模态数据的融合(EMT部分),并提升了随机模态特征缺失的鲁棒性(DLFR部分)。
研究方法
EMT核心:引入了全局多模态上下文 G ,采用 OAGL 的跨模态交互融合策略。(One-to-all Global-Local Fusion)
DLFR核心:结合隐式低层次特征重构(implicit low-level feature reconstruction)和显式高层次特征吸引(explict high-level feature attraction)。
1.总体结构图
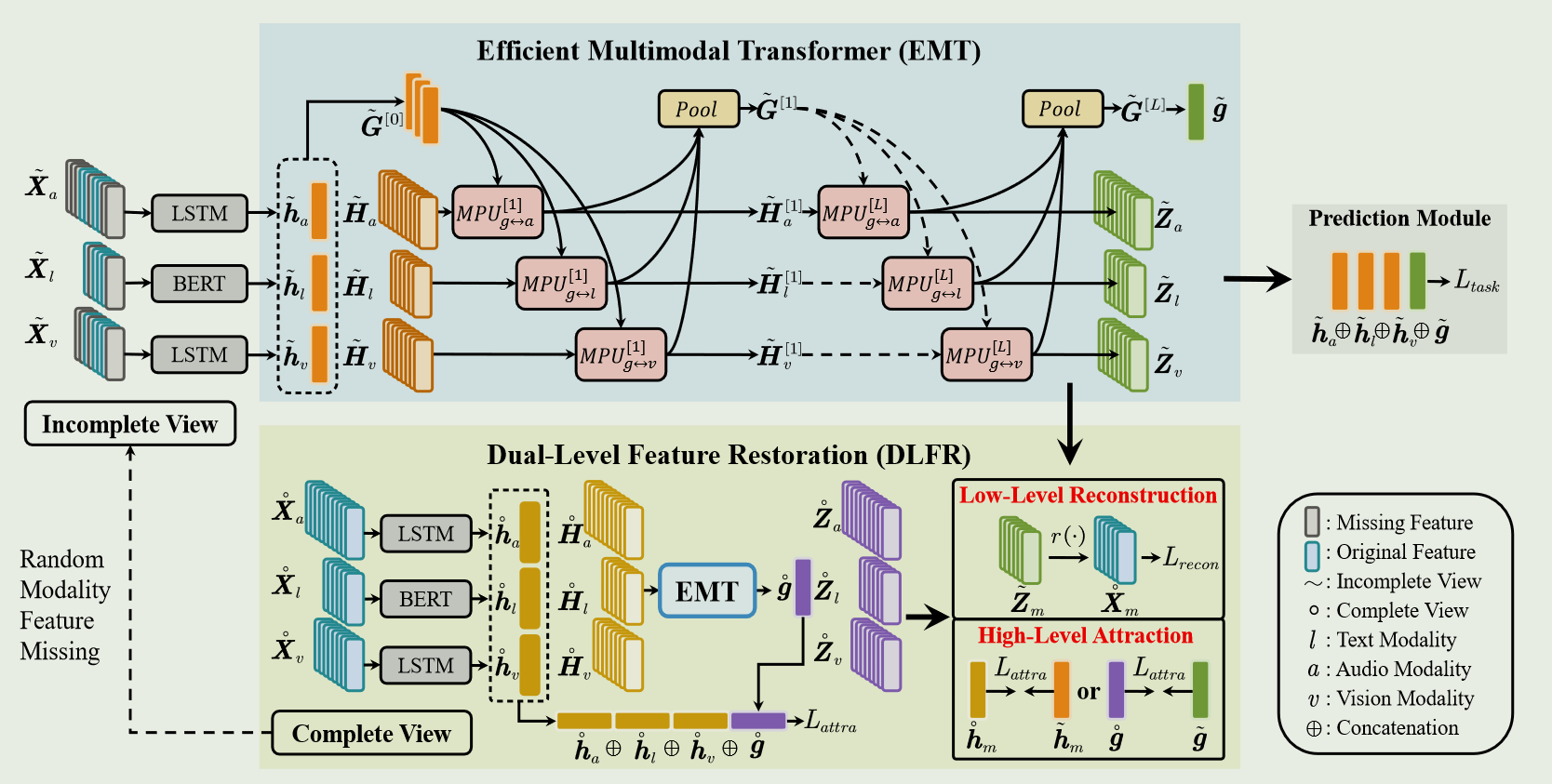
融合过程:首先利用特定的单模态特征编码器1从不同模态2输入中获取语篇级模态内特征3(全局模态内特征)和元素级模态内特征4(局部模态内特征5);然后使用 EMT 捕捉全局多模态上下文6和局部单模态特征5之间的跨模态交互信息;最后结合语篇级模态内特征3和语篇级模态间特征7得出最终的情感强度预测结果。
注:Complete View 仅用于在训练过程中训练模型,在测试阶段无法使用。
2.MPU 单元

MPU 单元利用对称跨模态注意力(CA),将两个输入特征序列之间的内在相关性联系起来,并进行有用的信息交换,使得这两个特征序列相互促进。然后利用自注意力(SA),整合时间依赖,学到上下文信息。最后通过前馈网络(FFN)输出提升后的
H
m
→
n
H_{m\to n}
Hm→n与
H
n
→
m
H_{n\to m}
Hn→m 。
H
n
→
m
′
=
M
H
C
A
(
LN
(
H
m
)
,
LN
(
H
n
)
)
+
H
m
,
H
n
→
m
′
′
=
M
H
S
A
(
LN
(
H
n
→
m
′
)
)
+
H
n
→
m
′
,
H
n
→
m
=
F
F
N
(
L
N
(
H
n
→
m
′
′
)
)
+
H
n
→
m
′
′
\begin{aligned} &H_{n\to m}^{'} =\mathrm{MHCA}(\operatorname{LN}(H_m),\operatorname{LN}(H_n))+H_m, \\ &H_{n\to m}^{^{\prime\prime}} =\mathrm{MHSA}(\operatorname{LN}(H_{n\to m}^{^{\prime}}))+H_{n\to m}^{^{\prime}}, \\ &H_{n\rightarrow m} =\mathrm{FFN}(\mathrm{LN}(H_{n\to m}^{^{\prime\prime}}))+H_{n\to m}^{^{\prime\prime}} \end{aligned}
Hn→m′=MHCA(LN(Hm),LN(Hn))+Hm,Hn→m′′=MHSA(LN(Hn→m′))+Hn→m′,Hn→m=FFN(LN(Hn→m′′))+Hn→m′′
注:这里的 Norm 使用的是 layer Normalization.
3.融合策略(EMT核心)
采用一对多的全局局部融合策略(One-to-all Global-Local Fusion)
H
l
[
i
+
1
]
,
G
l
→
g
[
i
]
=
M
P
U
l
↔
g
[
i
]
(
H
l
[
i
]
,
G
[
i
]
)
H
a
[
i
+
1
]
,
G
a
→
g
[
i
]
=
M
P
U
a
↔
g
[
i
]
(
H
a
[
i
]
,
G
[
i
]
)
H
v
[
i
+
1
]
,
G
v
→
g
[
i
]
=
M
P
U
v
↔
g
[
i
]
(
H
v
[
i
]
,
G
[
i
]
)
G
[
0
]
=
C
o
n
c
a
t
(
h
l
[
0
]
,
h
a
[
0
]
,
h
v
[
0
]
)
∈
R
3
×
d
.
\begin{gathered} H_l^{[i+1]},G_{l\to g}^{[i]} =\mathrm{MPU}_{l\leftrightarrow g}^{[i]}(H_l^{[i]},G^{[i]}) \\ H_a^{[i+1]},G_{a\to g}^{[i]} =\mathrm{MPU}_{a\leftrightarrow g}^{[i]}(H_a^{[i]},G^{[i]}) \\ H_{v}^{[i+1]},G_{v\to g}^{[i]} =\mathrm{MPU}_{v\leftrightarrow g}^{[i]}(H_v^{[i]},G^{[i]}) \\ \\ G^{[0]}~=~\mathsf{Concat}(h_l^{[0]},h_a^{[0]},h_v^{[0]})~\in~\mathbb{R}^{3\times d}. \end{gathered}
Hl[i+1],Gl→g[i]=MPUl↔g[i](Hl[i],G[i])Ha[i+1],Ga→g[i]=MPUa↔g[i](Ha[i],G[i])Hv[i+1],Gv→g[i]=MPUv↔g[i](Hv[i],G[i])G[0] = Concat(hl[0],ha[0],hv[0]) ∈ R3×d.
通过将MPU堆叠多层,全局多模态上下文6和局部单模态特征5之间便可以相互促进。
4.Pool层
Pool层使用的是attention-based pooling layer,通过 Pool层将提升后的全局多模态上下文8融合起来,生成新的全局多模态上下文6
G
[
i
+
1
]
=
s
o
f
t
m
a
x
(
v
T
tanh
(
W
T
G
g
T
+
b
)
)
G
g
G
g
=
C
o
n
c
a
t
(
G
l
→
g
[
i
]
,
G
a
→
g
[
i
]
,
G
v
→
g
[
i
]
)
G^{[i+1]}=\mathrm{softmax}(v^T\tanh{(W^TG_g^T+b)})G_g \\ G_g=\mathsf{Concat}(G_{l\to g}^{[i]},G_{a\to g}^{[i]},G_{v\to g}^{[i]})
G[i+1]=softmax(vTtanh(WTGgT+b))GgGg=Concat(Gl→g[i],Ga→g[i],Gv→g[i])
5.Prediction Module
首先将最后的全局多模态上下文6的时间维度扁平化,进而得到语篇级模态间特征7;接着将 g g g与 h m h_m hm进行拼接;最后通过一个多层感知器(MLP)得到情感预测结果。
使用的损失函数为 L1 损失函数: L t a s k = ∣ y − y ′ ∣ \mathcal{L}_\mathrm{task}=|y-y^{\prime}| Ltask=∣y−y′∣
6.Low-Level Feature Reconstruction

通过 EMT 进行多模态融合后,不完整序列
X
~
m
\tilde{\boldsymbol{X}}_{m}
X~m被映射到一个潜在序列9
Z
~
m
\tilde{\boldsymbol{Z}}_{m}
Z~m上;然后将
Z
~
m
\tilde{\boldsymbol{Z}}_{m}
Z~m通过基于多层感知器(MLP)的解码器
r
(
⋅
)
r(\cdot)
r(⋅)来重建完整的序列
X
˚
m
\boldsymbol{\mathring{X}}_{m}
X˚m。并使用smooth L1 loss来评估重构的质量。
L
r
e
c
o
n
l
=
smooth
L
1
(
(
H
˚
l
−
r
(
Z
~
l
)
)
⋅
(
1
−
g
l
)
)
L
r
e
c
o
n
a
=
s
m
o
o
t
h
L
1
(
(
X
˚
a
−
r
(
Z
~
a
)
)
⋅
(
1
−
g
a
)
)
L
r
e
c
o
n
v
=
s
m
o
o
t
h
L
1
(
(
X
˚
v
−
r
(
Z
~
v
)
)
⋅
(
1
−
g
v
)
)
L
r
e
c
o
n
=
∑
m
∈
{
l
,
a
,
v
}
L
recon
m
\begin{aligned} &\mathcal{L}_{\mathrm{recon}}^{l} =\text{smooth}_{\text{L}1}((\mathring{H}_l-r(\tilde{Z}_l))\cdot(1-g_l)) \\ &\mathcal{L}_{\mathrm{recon}}^a =\mathrm{smooth}_{\text{L}1}((\mathring{X}_a-r(\tilde{Z}_a))\cdot(1-g_a)) \\ &\mathcal{L}_{\mathrm{recon}}^v =\mathrm{smooth}_{\text{L}1}((\mathring{X}_v-r(\tilde{Z}_v))\cdot(1-g_v)) \\ &\mathcal{L}_{\mathrm{recon}} =\sum_{m\in\{l,a,v\}}\mathcal{L}_{\text{recon}}^m \end{aligned}
Lreconl=smoothL1((H˚l−r(Z~l))⋅(1−gl))Lrecona=smoothL1((X˚a−r(Z~a))⋅(1−ga))Lreconv=smoothL1((X˚v−r(Z~v))⋅(1−gv))Lrecon=m∈{l,a,v}∑Lreconm
s m o o t h L 1 ( x ) = { 0.5 x 2 i f x < 1 ∣ x ∣ − 0.5 o t h e r w i s e \mathrm{smooth}_{\mathrm{L}1}(x)=\begin{cases}0.5x^2&\mathrm{if~}x<1\\|x|-0.5&\mathrm{otherwise}&\end{cases} smoothL1(x)={0.5x2∣x∣−0.5if x<1otherwise
注:由于重建原始文本标记会浪费大量模型容量,故使用BERT模型的输出嵌入 H ˚ l \boldsymbol{\mathring{H}}_{l} H˚l作为文本模态的重建目标。对于音频模态和视频模态,依旧使用原始标记序列 X ˚ a \boldsymbol{\mathring{X}}_{a} X˚a与 X ˚ v \boldsymbol{\mathring{X}}_{v} X˚v。这里的 g l , g a , g v g_l,g_a,g_v gl,ga,gv是随机的时间掩码(模拟随机模态特征缺失时所用到的 g m g_m gm),用于排除未掩码位置的损失。
7.High-Level Feature Attraction

进行特征吸引的直接方法是最大化两个视图特征(即 h ~ m 与 h ˚ m , m ∈ { l , a , v } \tilde{\boldsymbol{h}}_{m} 与 \boldsymbol{\mathring{h}}_{m},\quad\begin{aligned}m\in\{l,a,v\}\end{aligned} h~m与h˚m,m∈{l,a,v})的余弦相似度。
通过使用自监督表征学习框架SimSiam,避免最大化余弦相似度出现崩溃(任务损失过大)的情况。

两个视图的输入特征首先由Projector10处理,然后Predictor11将一个视图的中间表征映射到另一个视图的中间表征。在这个过程中使用
s
g
(
⋅
)
sg(\cdot)
sg(⋅)停止梯度操作,避免繁琐解。语篇级模态内表征和语篇级模态间表征的对称SimSiam损失定义如下:
L
s
i
m
m
=
1
2
[
D
(
q
(
p
(
h
~
m
)
)
,
s
g
(
p
(
h
˚
m
)
)
)
+
D
(
q
(
p
(
h
˚
m
)
)
,
s
g
(
p
(
h
~
m
)
)
)
]
L
s
i
m
g
=
1
2
[
D
(
q
(
p
(
g
~
)
)
,
s
g
(
p
(
g
˚
)
)
)
+
D
(
q
(
p
(
g
˚
)
)
,
s
g
(
p
(
g
~
)
)
)
]
\begin{aligned} &\mathcal{L}_{\mathrm{sim}}^{m} =\frac12[\mathcal{D}(q(p(\tilde{h}_m)),sg(p(\mathring{h}_m)))+\mathcal{D}(q(p(\mathring{h}_m)),sg(p(\tilde{h}_m)))] \\ &\mathcal{L}_{\mathrm{sim}}^{g} =\frac12[\mathcal{D}(q(p(\tilde{g})),sg(p(\mathring{g})))+\mathcal{D}(q(p(\mathring{g})),sg(p(\tilde{g})))] \end{aligned}
Lsimm=21[D(q(p(h~m)),sg(p(h˚m)))+D(q(p(h˚m)),sg(p(h~m)))]Lsimg=21[D(q(p(g~)),sg(p(g˚)))+D(q(p(g˚)),sg(p(g~)))]
D ( x , y ) = − x T y ∣ ∣ x ∣ ∣ 2 ∣ ∣ y ∣ ∣ 2 \mathcal{D}(x,y)=\frac{-x^Ty}{||x||_2||y||_2} D(x,y)=∣∣x∣∣2∣∣y∣∣2−xTy
注: D ( x , y ) D(x,y) D(x,y)是负余弦相似度函数
高层次特征吸引损失函数:
L
attra
=
∑
m
∈
{
l
,
a
,
v
}
L
s
i
m
m
+
L
s
i
m
g
+
∣
y
−
y
˚
′
∣
\mathcal{L}_\text{attra}=\sum_{m\in\{l,a,v\}}\mathcal{L}_{\mathrm{sim}}^m+\mathcal{L}_{\mathrm{sim}}^g+|y-\mathring{y}^{\prime}|
Lattra=m∈{l,a,v}∑Lsimm+Lsimg+∣y−y˚′∣
8.总体损失函数
In incomplete modality setting:
L
=
L
t
a
s
k
+
λ
1
L
r
e
c
o
n
+
λ
2
L
a
t
t
r
a
L
t
a
s
k
=
∣
y
−
y
~
′
∣
\mathcal{L}=\mathcal{L}_\mathrm{task}+\lambda_1\mathcal{L}_\mathrm{recon}+\lambda_2\mathcal{L}_\mathrm{attra}\\ \mathcal{L}_{\mathrm{task}}=|y-\tilde{y}^{\prime}|
L=Ltask+λ1Lrecon+λ2LattraLtask=∣y−y~′∣
In complete modality setting:
L
=
L
task
=
∣
y
−
y
′
˚
∣
\mathcal{L}=\mathcal{L}_\text{task}=|y-\mathring{y'}|
L=Ltask=∣y−y′˚∣
结果与讨论
- 通过与sota模型进行对比,表明EMT-DLFR不管是在完整模态设置下还是不完整模态设置下效果都是最好。
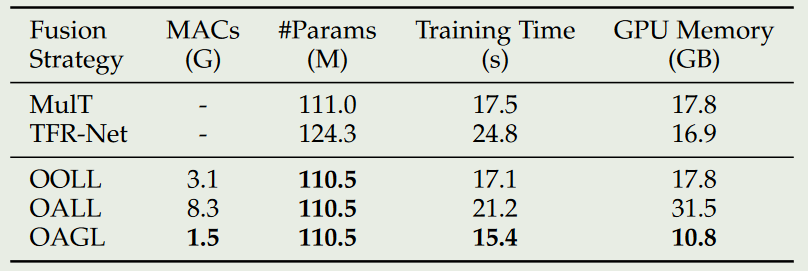
- 通过比对几种不同的融合策略,表明OAGL的融合方式最佳。
- 通过比对是否进行参数共享的几种情况,表明参数共享可以提升模型的效率。
- 通过比对不同的池化方法,表明attention-based的池化方法效果最好。
- 通过比对LLFR、HLFR、DLFR、EMT,表明即使用低层次特征重构又使用高层次特征吸引效果最好。
- 通过对损失函数的超参数进行研究,指出了最佳的超参数的值。
- 通过比较在高层次特征吸引中是否使用SimSiam框架,表明使用该框架效果好。
- 通过可视化全局多模态上下文对局部单模态特征的关注,证明了全局多模态上下文学会了关注每种模态中的有意义信号(如失望的面部表情、强调的语气和情感词)。
代码和数据集
数据集:CMU-MOSI,CMU-MOSEI,CH-SIMS
代码:https://github.com/sunlicai/EMT-DLFR
实验运行环境:Tesla V100 GPU(32GB),batch 大小为 32。
😃😃😃
图中的 LSTM 与 BERT ↩︎
图中的 X ~ m 与 X ˚ m , m ∈ { l , a , v } \tilde{\boldsymbol{X}}_{m}与\boldsymbol{\mathring{X}}_{m},\quad\begin{aligned}m\in\{l,a,v\}\end{aligned} X~m与X˚m,m∈{l,a,v},是初始的不完整与完整情况下的模态特征,是利用一些工具提取出来的。为了模拟随机模态特征缺失,使用了一个掩码函数 F ( ⋅ ) F(\cdot) F(⋅), X ~ m = F ( X ∘ m , g m ) ∈ R T m × f m \tilde{X}_{m}~=~F(\stackrel{\circ}{X}_{m},g_{m})~\in~\mathbb{R}^{T_{m}\times f_{m}} X~m = F(X∘m,gm) ∈ RTm×fm( T m T_m Tm代表序列长度, f m f_m fm代表模态特征的维度, g m ∈ { 0 , 1 } T m \begin{aligned}g_m\in\{0,1\}^{T_m}\end{aligned} gm∈{0,1}Tm是一个随机的时间掩码,表示要掩码的位置)。对于音频和视频模态,掩码函数将掩码位置的原始特征向量替换为零向量。对于文本模态,用 BERT 词汇表中的 [UNK] 标记替换原始标记。 ↩︎
utterance-level intra-modal features,既图中的 h ~ m 与 h ˚ m , m ∈ { l , a , v } \tilde{\boldsymbol{h}}_{m} 与 \boldsymbol{\mathring{h}}_{m},\quad\begin{aligned}m\in\{l,a,v\}\end{aligned} h~m与h˚m,m∈{l,a,v}。由于BERT中的[CLS]标记汇总了所有文本信息,所以将其作为文本模态的语篇级模态内特征。对于音频与视觉模态,使用 H a 和 H v H_a和H_v Ha和Hv中最后一个时间步骤的特征作为语篇级模态内特征。 ↩︎ ↩︎
element-level intra-modal features,既图中的 H ~ m 与 H ˚ m , m ∈ { l , a , v } \tilde{\boldsymbol{H}}_{m} 与 \boldsymbol{\mathring{H}}_{m},\quad\begin{aligned}m\in\{l,a,v\}\end{aligned} H~m与H˚m,m∈{l,a,v}。 H l = BERT ( X l ) H_{l} =\text{BERT}(X_l) Hl=BERT(Xl), H a = LSTM ( X a ) H_{a} =\operatorname{LSTM}(X_a) Ha=LSTM(Xa), H v = LSTM ( X v ) H_{v} =\operatorname{LSTM}(X_v) Hv=LSTM(Xv) ↩︎
local unimodal features,既图中的 H ~ m 与 H ˚ m , m ∈ { l , a , v } \tilde{\boldsymbol{H}}_{m} 与 \boldsymbol{\mathring{H}}_{m},\quad\begin{aligned}m\in\{l,a,v\}\end{aligned} H~m与H˚m,m∈{l,a,v} ↩︎ ↩︎ ↩︎
global multimodal context,既图中的 G ~ m 与 G ˚ m , m ∈ { l , a , v } \tilde{\boldsymbol{G}}_{m} 与 \boldsymbol{\mathring{G}}_{m},\quad\begin{aligned}m\in\{l,a,v\}\end{aligned} G~m与G˚m,m∈{l,a,v} ↩︎ ↩︎ ↩︎ ↩︎
utterance-level inter-modal features,既图中的 g ~ m 与 g ˚ m , m ∈ { l , a , v } \tilde{\boldsymbol{g}}_{m} 与 \boldsymbol{\mathring{g}}_{m},\quad\begin{aligned}m\in\{l,a,v\}\end{aligned} g~m与g˚m,m∈{l,a,v} ↩︎ ↩︎
promoted global multimodal contexts,即 G l → g [ i ] G a → g [ i ] G v → g [ i ] G_{l\rightarrow g}^{[i]}\quad G_{a\rightarrow g}^{[i]}\quad G_{v\rightarrow g}^{[i]} Gl→g[i]Ga→g[i]Gv→g[i] ↩︎
latent sequence,即图中的 Z ~ m 与 Z ˚ m , m ∈ { l , a , v } \tilde{\boldsymbol{Z}}_{m} 与 \boldsymbol{\mathring{Z}}_{m},\quad\begin{aligned}m\in\{l,a,v\}\end{aligned} Z~m与Z˚m,m∈{l,a,v},且 Z ~ m = H ~ m [ L ] \tilde{Z}_m=\tilde{H}_m^{[L]} Z~m=H~m[L],该序列对全局模态间信息与局部模态内信息都有足够的认识。 ↩︎
基于多层感知器(MLP-based projector)的映射器 p ( ⋅ ) p(\cdot) p(⋅) ↩︎
基于多层感知器(MLP-based predictor)的预测器 q ( ⋅ ) q(\cdot) q(⋅) ↩︎


















 2120
2120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









