






系列文章目录
个人笔记,无参考价值
Droid-SLAM
文章目录
前言
RAFT论文梳理笔记
提示:以下是本篇文章正文内容,下面案例可供参考
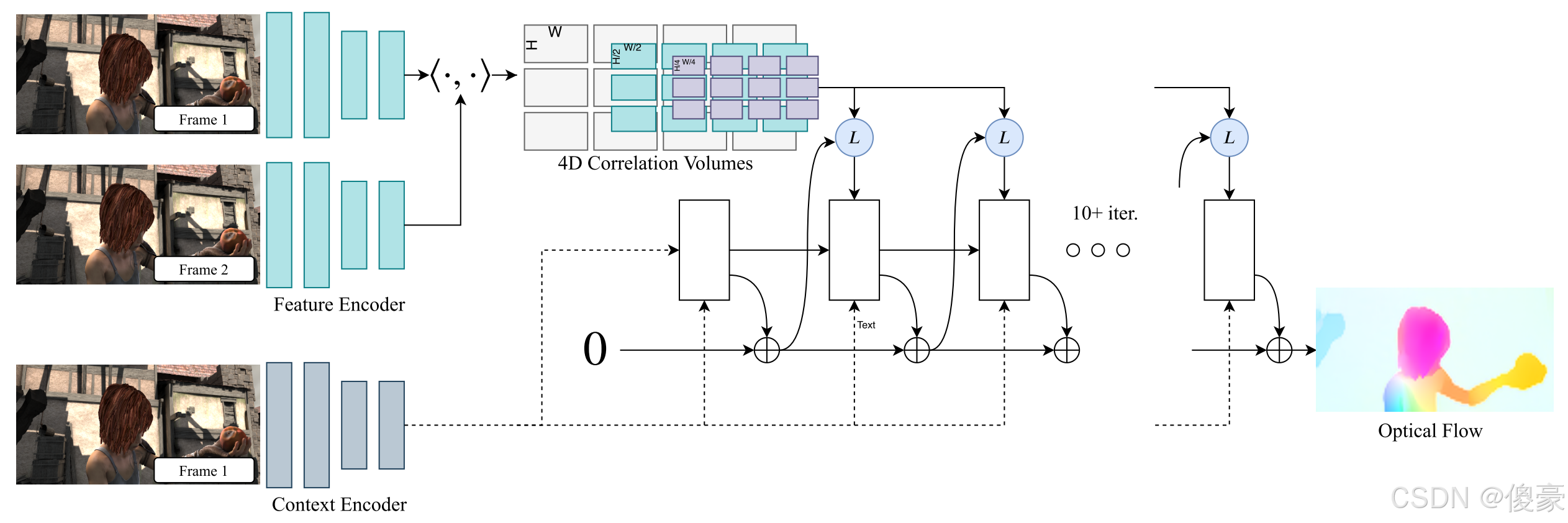
一、特征提取
1.1 feature extraction network
使用卷积网络从输入图像中提取特征。网络应用于图像
I
1
I_1
I1和图像
I
2
I_2
I2,并以1/8的分辨率将输入的图像映射到密集的特征图。
g
θ
:
R
H
×
W
×
3
↦
R
H
/
8
×
W
/
8
×
D
g_\theta:R^{H\times W \times 3}\mapsto R^{H/8\times W/8 \times D}
gθ:RH×W×3↦RH/8×W/8×D
其中D值为256。特征编码器由6个残差块组成,2个1/2分辨率,2个1/4分辨率,2个1/8分辨率
残差块(Residual Blocks)
残差块是深度学习中一种常用的模块,由 ResNet(Residual Network) 提出。它的核心思想是通过 跳跃连接(Skip Connection) 将输入直接加到输出上,从而缓解梯度消失问题,使网络更容易训练。一个典型的残差块结构如下:输入 x,经过若干卷积层和非线性激活函数,得到 F(x)输出为 F(x)+x
1.2 context network
FAFT 额外使用上下文网络。上下文网络仅从第一个输入图像
I
1
I_1
I1中提取特征。上下文网络的架构
h
θ
h_\theta
hθ与特征提取网络相同。
特征网络gθ和上下文网络hθ共同构成了我们方法的第一阶段,只需要执行一次。
1.3 网络结构

二、计算视觉相似度
给定图像特征
g
θ
(
I
1
)
∈
R
H
×
W
×
D
g_\theta(I_1)\in R^{H\times W \times D}
gθ(I1)∈RH×W×D 和
g
θ
(
I
2
)
∈
R
H
×
W
×
D
g_\theta(I_2)\in R^{H\times W \times D}
gθ(I2)∈RH×W×D 。相关性体积(correlation volume)可以通过计算两两特征向量之间的点乘得到.
相关性体积
C
C
C 用公式可以表达为:
C
(
g
θ
(
I
1
)
,
g
θ
(
I
2
)
)
∈
R
H
×
W
×
H
×
W
C(g_\theta(I_1),g_\theta(I_2))\in R^{H\times W \times H\times W}
C(gθ(I1),gθ(I2))∈RH×W×H×W
点积(Dot Product)
点积被广泛用于计算特征向量之间的相似性。点积的几何意义是: a ⋅ b = ∥ a ∥ ∥ b ∥ c o s θ a\cdot b = \|a\| \|b\| cos\theta a⋅b=∥a∥∥b∥cosθ
当两个向量的方向越接近(夹角 θ 越小),点积的值越大;反之,点积的值越小。因此,点积可以有效地衡量两个特征向量之间的相似性。
- 如果两个像素的特征向量相似(方向接近),点积的值较大。
- 如果两个像素的特征向量不相似(方向远离),点积的值较小。
g θ ( I 1 ) ∈ R H × W × D g_\theta(I_1)\in R^{H\times W \times D} gθ(I1)∈RH×W×D 和 g θ ( I 2 ) ∈ R H × W × D g_\theta(I_2)\in R^{H\times W \times D} gθ(I2)∈RH×W×D 之间的相关性体积计算
g θ ( I 1 ) g_\theta(I_1) gθ(I1)的意义: H × W H\times W H×W 个像素,每个像素有一个 D D D维的特征向量, g θ ( I 2 ) g_\theta(I_2) gθ(I2)也如此,这样就是图像 I 1 I_1 I1中 H × W H\times W H×W 个 D D D维的特征向量分别与图像 I 2 I_2 I2中 H × W H\times W H×W 个 D D D维的特征向量进行点积,得到 H × W × H × W H\times W \times H\times W H×W×H×W 个值
2.1 相关性金字塔
构造4层代价空间的金字塔
{
C
1
,
C
2
,
C
3
,
C
4
,
}
\{C^1,C^2,C^3,C^4,\}
{C1,C2,C3,C4,}。将后两个通道通过平均池化的方式进行降采样。(内核大小为1、2、4和8)

因此,相关性体积
C
k
+
1
C^{k+1}
Ck+1 具有尺寸
H
×
W
×
H
/
2
k
×
W
/
2
k
H×W×H/2^k×W/2^k
H×W×H/2k×W/2k,其中
k
=
0
,
1
,
2
,
3
k=0,1,2,3
k=0,1,2,3 。这样相关性金字塔就拥有了关于大位移和小位移的信息。而且,通过保持前2维(图
I
1
I_1
I1的维度)不变,就保持了高分辨率信息,可以恢复快速移动的小物体的运动。

- 在相关性金字塔的高分辨率尺度(如原始分辨率或 1/2 分辨率)上,特征图的细节信息丰富。这些尺度能够捕捉图像中的小位移,因为高分辨率特征图可以精确匹配相邻帧中的微小移动。
- 在相关性金字塔的低分辨率尺度(如 1/4 或 1/8 分辨率)上,特征图的感受野更大。这些尺度能够捕捉图像中的大位移,因为低分辨率特征图可以覆盖更大的空间范围,从而匹配较远的像素。
理解 4D 相关性体积
相关性体积 C 的每个元素 C ( i , j , k , l ) C(i,j,k,l) C(i,j,k,l) 表示:
- 第一帧图像 I 1 I_1 I1 中像素 ( i , j ) (i,j) (i,j) 的特征向量与第二帧图像 I 2 I_2 I2 中像素 ( k , j ) (k,j) (k,j)特征向量之间的点积(即相关性)
因此,对于固定的 ( i , j ) (i,j) (i,j) , C ( i , j , : , : ) C(i,j,:,:) C(i,j,:,:) 是一个 2D 矩阵,表示第一帧图像 I 1 I_1 I1 中像素 ( i , j ) (i,j) (i,j)与第二帧图像 I 2 I_2 I2中所有像素的相关性
2.2 相关性查找
RAFT定义了一个查找算子
L
C
L_C
LC,它通过从相关金字塔中索引来生成特征图。
给定当前的光流估计
(
f
1
,
f
2
)
(f^1,f^2)
(f1,f2),将
I
1
I_1
I1 中的每个像素
x
=
(
u
,
v
)
x=(u,v)
x=(u,v) 映射到
I
2
I_2
I2 中,对应的像素位置为:
x
′
=
(
u
+
f
1
(
u
)
,
v
+
f
2
(
v
)
)
x'=(u+f^1(u),v+f^2(v))
x′=(u+f1(u),v+f2(v))。然后我们在
x
′
x'
x′ 周围定义一个局部网格:
N
(
x
′
)
r
=
{
x
′
+
d
x
∣
d
x
∈
Z
2
,
∣
∣
d
x
∣
∣
1
≤
r
}
N(x')_r = \{x' + dx | dx \in Z^2, ||dx||_1 ≤ r\}
N(x′)r={x′+dx∣dx∈Z2,∣∣dx∣∣1≤r}
N
(
x
′
)
r
N(x ′) r
N(x′)r 表示
x
′
x ′
x′ 周围,半径小于
r
r
r 的坐标集合。使用局部邻域
N
(
x
′
)
N ( x ′ )
N(x′) 从相关性体积中索引,得到特征。由于光流估计可能是浮点数,搜索区域的中心可能不在整数坐标上。因此,需要使用双线性插值 从相关性体积中提取非整数坐标处的相关性值。
提取局部相关性块
对于像素 ( i , j ) (i,j) (i,j)需要从 C ( i , j , : , : ) C(i,j,:,:) C(i,j,:,:) 中提取一个局部区域的相关性值。以下是具体步骤:
已知:相关性体积 C ∈ R H × W × H × W C\in R^{H\times W \times H\times W} C∈RH×W×H×W,当前的光流估计 ( f 1 , f 2 ) (f^1,f^2) (f1,f2),搜索区域大小 K×K(例如 3×3)
- 确定光流估计
根据光流估计,在第二帧图像 I 2 I_2 I2 中确定搜索区域的中心
( k c e n t e r , l c e n t e r ) = ( i + f 1 ( i ) , j + f 2 ( j ) ) (k_{center},l_{center})=(i+f^1(i),j+f^2(j)) (kcenter,lcenter)=(i+f1(i),j+f2(j))- 确定搜索区域范围
- 对于 3×3 的搜索区域,坐标为:
( k c e n t e r − 1 , l c e n t e r − 1 ) , ( k c e n t e r − 1 , l c e n t e r ) , ( k c e n t e r − 1 , l c e n t e r + 1 ) ( k c e n t e r , l c e n t e r − 1 ) , ( k c e n t e r , l c e n t e r ) , ( k c e n t e r , l c e n t e r + 1 ) ( k c e n t e r + 1 , l c e n t e r − 1 ) , ( k c e n t e r + 1 , l c e n t e r ) , ( k c e n t e r + 1 , l c e n t e r + 1 ) (k_{center}-1,l_{center}−1),(k_{center}-1,l _{center}),(k_{center}-1,l_{center} +1)\\(k_{center},l_{center}−1),(k_{center},l _{center}),(k_{center},l_{center} +1)\\(k_{center}+1,l_{center}−1),(k_{center}+1,l _{center}),(k_{center}+1,l_{center} +1) (kcenter−1,lcenter−1),(kcenter−1,lcenter),(kcenter−1,lcenter+1)(kcenter,lcenter−1),(kcenter,lcenter),(kcenter,lcenter+1)(kcenter+1,lcenter−1),(kcenter+1,lcenter),(kcenter+1,lcenter+1)- ( k c e n t e r , l c e n t e r ) (k_{center},l_{center}) (kcenter,lcenter)可能是浮点数,所以搜索范围的坐标也都不是整数,需要搜索区域中的每个坐标 ( k , l ) (k,l) (k,l),使用双线性插值从 C ( i , j , : , : ) C(i,j,:,:) C(i,j,:,:) 中提取值
- 构建局部相关性块
将所有插值后的值组合成一个 K × K K×K K×K 的局部相关性块 R ( i , j ) R(i,j) R(i,j)
在金字塔的所有层级上执行查询。如对于处在
k
k
k 层的
C
k
C^k
Ck ,使用网络
N
(
x
′
/
2
k
)
r
N ( x ′ / 2^k )_r
N(x′/2k)r 来索引。每层使用索引的网格半径
r
r
r 不变,因此层级越低,感受野越大。比如对于最低的层级 k = 4 ,若半径为 4,则在原始图像上对应256个像素(1/8的分辨率,所以一个像素对应64个像素)。
最后,将每个级别的查找值连接成一个特征图。
2.3 相关性查找的具体流程
相关性查找(Correlation Lookup) 是一个针对每个像素的操作,用于从 相关性金字塔(Correlation Pyramid) 中提取与当前光流估计相关的局部相关性信息。
(1) 是否对每个像素进行相关性查找?
是的,相关性查找是针对每个像素进行的。具体来说:
- 对于输入图像中的每个像素,RAFT 会根据当前的光流估计,确定其在下一帧图像中的对应位置。
- 然后,在该位置周围的一个局部区域内,从相关性金字塔中提取相关性值。
- 这个过程会对图像中的所有像素重复进行
(2) 相关性查找的输出是什么?
相关性查找的输出是一个局部相关性特征图,其具体形状和含义如下:
-
输出形状
假设输入图像的空间尺寸为 H × W H×W H×W,相关性金字塔有 L L L 层,查找区域的半径为 r r r。相关性查找的输出形状为:
( B , H , W , ( 2 r + 1 ) 2 , L ) (B,H,W,(2r+1) ^2 ,L) (B,H,W,(2r+1)2,L)
其中:- B B B:批量大小(Batch Size)。
- H × W H×W H×W:输入图像的空间尺寸。
- ( 2 r + 1 ) 2 (2r+1)^2 (2r+1)2:查找区域的大小(如半径为 4 时,区域大小为 9x9)。
- L L L:相关性金字塔的层数。
-
输出的含义
对于每个像素 ( i , j ) (i,j) (i,j),相关性查找会从相关性金字塔的每一层中提取一个局部区域的相关性值。这些相关性值表示当前像素与下一帧图像中局部区域内像素的匹配程度。
多尺度的相关性值(来自不同层的相关性金字塔)被拼接在一起,形成一个多维特征向量,用于后续的光流优化。
2.4 高分辨率图像的高效计算
计算相关性体积的时间复杂度为
O
(
N
2
)
O(N^2)
O(N2),N是像素的个数。但是只需要计算一次,并且在迭代次数M中是恒定的。并且,RAFT方法存在一个等价的实现,通过利用内积和平均池化的线性计算,可以将规模缩小为
O
(
N
M
)
O(NM)
O(NM)
其实通常来说,直接计算点对之间的相关也不会成为性能瓶颈,但是如果有需求的话,确实可以切换到等效的实现中。此外,raft的开源代码中也提供了代价空间的快速实现,可以通过编译cuda进行调用。
三、迭代更新
从初始的光流状态
f
0
f_0
f0 开始,更新操作符输出了N次光流的结果
{
f
1
,
f
2
,
.
.
.
,
f
N
}
\{f_1,f_2,...,f_N\}
{f1,f2,...,fN}。
每次迭代,更新操作符都产生一个更新方向
Δ
f
Δf
Δf,并将其与当前的光流状态进行叠加,得到更新后的光流状态:
f
k
+
1
=
Δ
f
+
f
k
+
1
f_{k+1}=Δf+f_{k+1}
fk+1=Δf+fk+1。
更新操作符将光流状态,相关空间,以及潜在的隐藏状态(初始的隐藏状态由语义提取器提供)作为输入,进而输出两个量,一个是用于更新的
Δ
f
Δf
Δf,另一个则是更新后的隐藏状态。这样的设计主要是为了模拟传统算法中的优化过程。因此,我们使用跨深度的绑定权重并使用有界激活来鼓励收敛到固定点。更新运算符经过训练以执行更新,使序列收敛到固定点
f
k
→
f
∗
f_k→f*
fk→f∗。

3.1 初始化
通常来说,我们会默认光流场在所有开始的时候默认值都是0。但是Raft这种迭代的方式,使得可以采用warm start的方式,比如,在将Raft应用到视频的光流估计的时候,就可以将前一帧的光流投影到下一帧去,作为下一帧的初始值。
3.2 输入
- 给定当前流估计 f k f_k fk,使用它从相关金字塔中检索相关特征,如第2.2节所述。然后用2个卷积层处理相关性特征。
- 此外,我们将2个卷积层应用于流量估计 f k f_k fk本身以生成流量特征。
- 最后,我们直接注入来自上下文网络的输入(上下文特征)。
输入特征图由相关性特征、流特征和上下文特征串联得到。
3.3 更新
更新运算符的核心组件是基于GRU单元的门控激活单元,卷积层替换了全连接层。
z
t
=
σ
(
C
o
n
v
3
×
3
(
[
h
t
−
1
,
x
t
]
,
W
z
)
)
r
t
=
σ
(
C
o
n
v
3
×
3
(
[
h
t
−
1
,
x
t
]
,
W
r
)
)
h
~
t
=
t
a
n
h
(
C
o
n
v
3
×
3
(
[
r
t
⊙
h
t
−
1
,
x
t
]
,
W
h
)
)
h
t
=
(
1
−
z
t
)
⊙
h
t
−
1
+
z
t
⊙
h
~
t
z_t=\sigma(Conv_{3\times 3}([h_{t-1},x_t],W_z))\\ r_t=\sigma(Conv_{3\times 3}([h_{t-1},x_t],W_r))\\ \widetilde{h}_t=tanh(Conv_{3\times 3}([r_t \odot h_{t-1},x_t],W_h)) \\ h_t=(1-z_t)\odot h_{t-1} + z_t \odot \widetilde{h}_t
zt=σ(Conv3×3([ht−1,xt],Wz))rt=σ(Conv3×3([ht−1,xt],Wr))h
t=tanh(Conv3×3([rt⊙ht−1,xt],Wh))ht=(1−zt)⊙ht−1+zt⊙h
t
- x t x_t xt是先前定义的输入特征图,由相关性特征、流特征和上下文特征拼接得到
- h t − 1 h _{t−1} ht−1 是前一时刻的隐藏状态; h t h _{t} ht是当前隐藏状态
- σ 是Sigmoid 激活函数
- W r , W z , W h W_r, W_z,W_h Wr,Wz,Wh是权重矩阵
- ⊙ \odot ⊙ 表示逐元素乘法(Hadamard 积)
GRU 输入: x t x_t xt
GRU 输出:输出是更新后的隐藏状态 h t h_t ht 和用于预测光流更新量 Δ f t Δf_t Δft。 Δ f t = W 0 ⋅ h t + b 0 \Delta f_t = W_0 \cdot h_t + b_0 Δft=W0⋅ht+b0。 W 0 , b 0 W_0, b_0 W0,b0 是可学习的参数
GRU更新: f t + 1 = f t + Δ f t f_{t+1}=f_{t}+Δf_t ft+1=ft+Δft
RAFT还试验了一个可分离的ConvGRU单元,其中用两个GRU替换3×3卷积:一个有1×5卷积,一个有5×1卷积,以增加感受野而不会显着增加模型的大小。
3.4 光流预测
GRU单元输出的潜在状态(hidden state)将会再被送进两个卷积层,用于输出更新的光流值 Δ f Δf Δf。输出光流分辨率是原始输入图像的1/8。在训练和评估期间,都会进一步地将1/8分辨率的输出上采样到全分辨率,进而能够与GT进行比较。
3.5 上采样
具体来说,Raft使用了两个卷积层来预测mask,这个mask的维度是 H / 8 × W / 8 × ( 8 × 8 × 9 ) H/8 \times W/8 ×(8×8×9) H/8×W/8×(8×8×9),因为对于1/8分辨率上的每一个像素来说,都对应着全分辨率的8*8个像素,而Raft又认为全分辨率的每一个像素又和其领域的9个像素相关,再对这9个邻居的权重做softmax,最后再根据这9个邻居的权值加权得到全分辨率上的结果。而这样的过程,可以使用pytorch所提供的unfold函数进行实现。
最终的高分辨率流场是通过使用掩码在邻域上进行加权组合,然后排列和重塑为一个H×W×2维流场来找到的。
四 损失函数
RAFT进行了12次迭代,进而会产生12个全分辨率的光流结果。常理来说,越迭代到后面,理应更为接近GT,因此,给其更大的权重,进而,loss的设计为:
L
=
∑
i
=
1
N
γ
N
−
i
∥
f
g
t
−
f
i
∥
1
L = \sum^{N}_{i=1} \gamma^{N-i} \|f_{gt} - f_i\|_1
L=i=1∑NγN−i∥fgt−fi∥1
其中的
γ
\gamma
γ 是一个经验参数,在Raft中设置为0.8。
N
N
N 的值为12.
总结
提示:这里对文章进行总结:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









