







Kmeans 聚类数据任务实现与分析
摘要:作为无监督聚类算法中的代表——K均值聚类(Kmeans)算法,该算法的主要作用是将相似的样本自动归到一个类别中。Kmeans算法是最常用的聚类算法,主要思想是:在给定K值和K个初始类簇中心点的情况下,把每个点(即数据记录)分到离其最近的类簇中心点所代表的类簇中,所有点分配完毕之后,根据一个类簇内的所有点重新计算该类簇的中心点(取平均值),然后再迭代的进行分配点和更新类簇中心点的步骤,直至类簇中心点的变化很小,或者达到指定的迭代次数。
一、问题介绍
本案例,通过各类广告渠道90天内额日均UV,平均注册率、平均搜索率、访问深度、平均停留时长、订单转化率、投放时间、素材类型、广告类型、合作方式、广告尺寸和广告卖点等特征,将渠道分类,找出每类渠道的重点特征,为业务讨论和数据分析提供支持。
数据13个维度介绍
- 渠道代号:渠道唯一标识
- 日均UV:每天的独立访问量
- 平均注册率=日均注册用户数/平均每日访问量
- 平均搜索量:每个访问的搜索量
- 访问深度:总页面浏览量/平均每天的访问量
- 平均停留时长=总停留时长/平均每天的访问量
- 订单转化率=总订单数量/平均每天的访客量
- 投放时间:每个广告在外投放的天数
- 素材类型:‘jpg’ ‘swf’ ‘gif’ ‘sp’
- 广告类型:banner. tips. 不确定. 横幅. 暂停
- 合作方式:‘roi’ ‘cpc’ ‘cpm’ ‘cpd’
- 广告尺寸:‘14040’ ‘308388’ ‘450300’ ‘60090’ ‘480360’ ‘960126’ ‘900120’
‘390270’ - 广告卖点:打折. 满减. 满赠. 秒杀. 直降. 满返
要求:
完成缺失值处理
完成相关性分析
完成数据编码与标准化
完成建立KMeans聚类模型
对模型结果进行分析总结
聚类分析可视化展示(选做)
输出聚类结果result.csv
二、结题步骤
2.1导入项目所用到的包
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, OneHotEncoder,LabelEncoder # 预处理
from sklearn.cluster import KMeans # 聚类算法
from sklearn.metrics import silhouette_score # 用于评估度量的模块
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
# 设置显示格式
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
pd.set_option('max_colwidth', 30)
# 设置图像的字体
matplotlib.rc("font",family="STXingkai")
# plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
2.2导入数据并查看
# 获取到数据
data = pd.read_csv('ad_performance.csv',index_col=0)
print(data)
2.3对数据进行审查,看是否有缺失值
# 对数据进行审查:是否有缺失值
print('{:*^60}'.format('数据样本:统计描述'))
print(data.describe().round(4).T)

从数据审查可以看出:
1.UV的数据波动很大,说明不同渠道差异是很明显的。但是差异并不一定是异常值,所以一般不作为异常值处理。
2.平均注册率,平均搜索量,订单转化率多个统计量为0,考虑到极大值本身就很小,说明数据本身就很小,符合实际情况,所以是正常的。
2.4填充缺失值
# 对缺失值的填充(均值)
print('{:*^60}'.format('缺失值:填充法'))
print(data[data.isna().values == True])
# print(data.isna().values)
data = data.fillna(419.77)
print(data[data.isna().values == True])

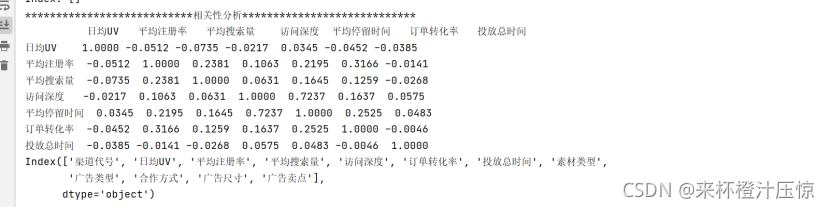
2.5相关性分析
在使用K-Means进行聚类分析时,该算法会计算数据与中心点之间的欧氏距离,两个高相关性的变量会使算法重复计算高相关特征这会夸大影响,影响最终的聚类结果,因此需要合并高相关性变量。
#相关性分析
print('{:*^60}'.format('相关性分析'))
print(data.corr().round(4).T)
# 生成相关性统计表格
#pd.DataFrame(data.corr().round(4).T).to_excel('result.xlsx')
data = data.drop(['平均停留时间'], axis=1)
print(data.columns)
print("**********************")
print(data.corr().round(4).T)
2.6数据标准化
#数据标准化
matrix = data.iloc[:, 1:7] #获得要转换的矩阵
print(matrix)
#print("****************")
min_max_model = MinMaxScaler()
data_rescaled = min_max_model.fit_transform(matrix)
print('{:*^60}'.format('数据标准化'))
print(data_rescaled.round(2))

2.7数字特征化,即将字符特征转化为标志位(0、1)
# 特征数字化
print(data.iloc[:, 7:12])
onehot_mode = OneHotEncoder(sparse=False)
le=LabelEncoder()
y=data.iloc[:,7:12]
data_le=[]
for L in y.columns:
y[L]=le.fit_transform(y[L])
data_le< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3034
3034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











