








项目简介
(下文摘录来自giuhub官方中文文档)
PDF-Extract-Kit 是一款功能强大的开源工具箱,旨在从复杂多样的 PDF 文档中高效提取高质量内容。以下是其主要功能和优势:
-
集成文档解析主流模型:汇聚布局检测、公式检测、公式识别、OCR等文档解析核心任务的众多SOTA模型;
-
多样性文档下高质量解析结果:结合多样性文档标注数据在进行模型微调,在复杂多样的文档下提供高质量解析结果;
-
模块化设计:模块化设计使用户可以通过修改配置文件及少量代码即可自由组合构建各种应用,让应用构建像搭积木一样简便;
-
全面评测基准:提供多样性全面的PDF评测基准,用户可根据评测结果选择最适合自己的模型。
注意: PDF-Extract-Kit 专注于高质量文档处理,适合作为模型工具箱使用。 如果你想提取高质量文档内容(PDF转Markdown),请直接使用MinerU,MinerU结合PDF-Extract-Kit的高质量预测结果,进行了专门的工程优化,使得PDF文档内容提取更加便捷高效;
如果你是一位开发者,希望搭建更多有意思的应用(如文档翻译,文档问答,文档助手等),基于PDF-Extract-Kit自行进行DIY将会十分便捷。特别地,我们会在PDF-Extract-Kit/project下面不定期更新一些有趣的应用,敬请期待!
环境需求(github原文附有详细官方教材)
1.下载github项目
(github打不开或下载速度过慢推荐使用fastgithub,gitee链接)
2.anconda安装
详见大佬文档:anaconda安装教程
3.python环境搭建
切换目录至项目路径(.\PDF-Extract-Kit-main)
打开命令行输入:
conda create -n pdf-extract-kit-1.0 python=3.10 -y
conda activate pdf-extract-kit-1.0创建pdf-extract-kit虚拟环境,使用python3.10版本
切换目录至项目路径(.\PDF-Extract-Kit-main)
# 对于GPU设备
pip install -r requirements.txt
# 对于CPU设备
pip install -r requirements-cpu.txt4.配置模型文件
下载模型文件
方法:Git LFS
HuggingFace 和 ModelScope 的远程模型仓库就是一个由 Git LFS 管理的 Git 仓库。因此,我们可以利用 git clone 完成权重的下载:
git lfs install
# From HuggingFace
git lfs clone https://huggingface.co/opendatalab/pdf-extract-kit-1.0
# From ModelScope
git clone https://www.modelscope.cn/opendatalab/pdf-extract-kit-1.0.git下载后的文件默认保存在C:\users\username\pdf-extract-kit-1.0内
将内部的model文件夹拷贝到项目路径(.\PDF-Extract-Kit-main)下
以布局检测算法为例配置模型文件
- 模型文件配置路径:\configs\layout_detection.yaml
- 打开文件如下:
inputs: assets/demo/layout_detection outputs: outputs/layout_detection tasks: layout_detection: model: layout_detection_yolo model_config: img_size: 1024 conf_thres: 0.25 iou_thres: 0.45 model_path: path/to/doclayout_yolo_model visualize: True
修改模型文件:路径:model_path: models/Layout/YOLO/doclayout_yolo_ft.pt修改输入输出路径:
输入:(两种模式:单个文件、多个文件的文件目录)
inputs: assets/demo/layout_detection/exam_paper.png
输出:(若指定可视化(visualize: True)输出会输出在此路径)
outputs: outputs/layout_detection
- 配置识别模式:
路径:\scripits\layout_detection.py
识别模式:layout_detection.py修改detection_results(两种模式:images,pdfs。)
执行程序
在项目路径(.\PDF-Extract-Kit-main) 下进入anaconda虚拟环境
执行代码:
python scripts/layout_detection.py --config configs/layout_detection.yaml输出结果:
The predicted results can be found at outputs/layout_detection成功执行布局检测。
识别效果如下图所示
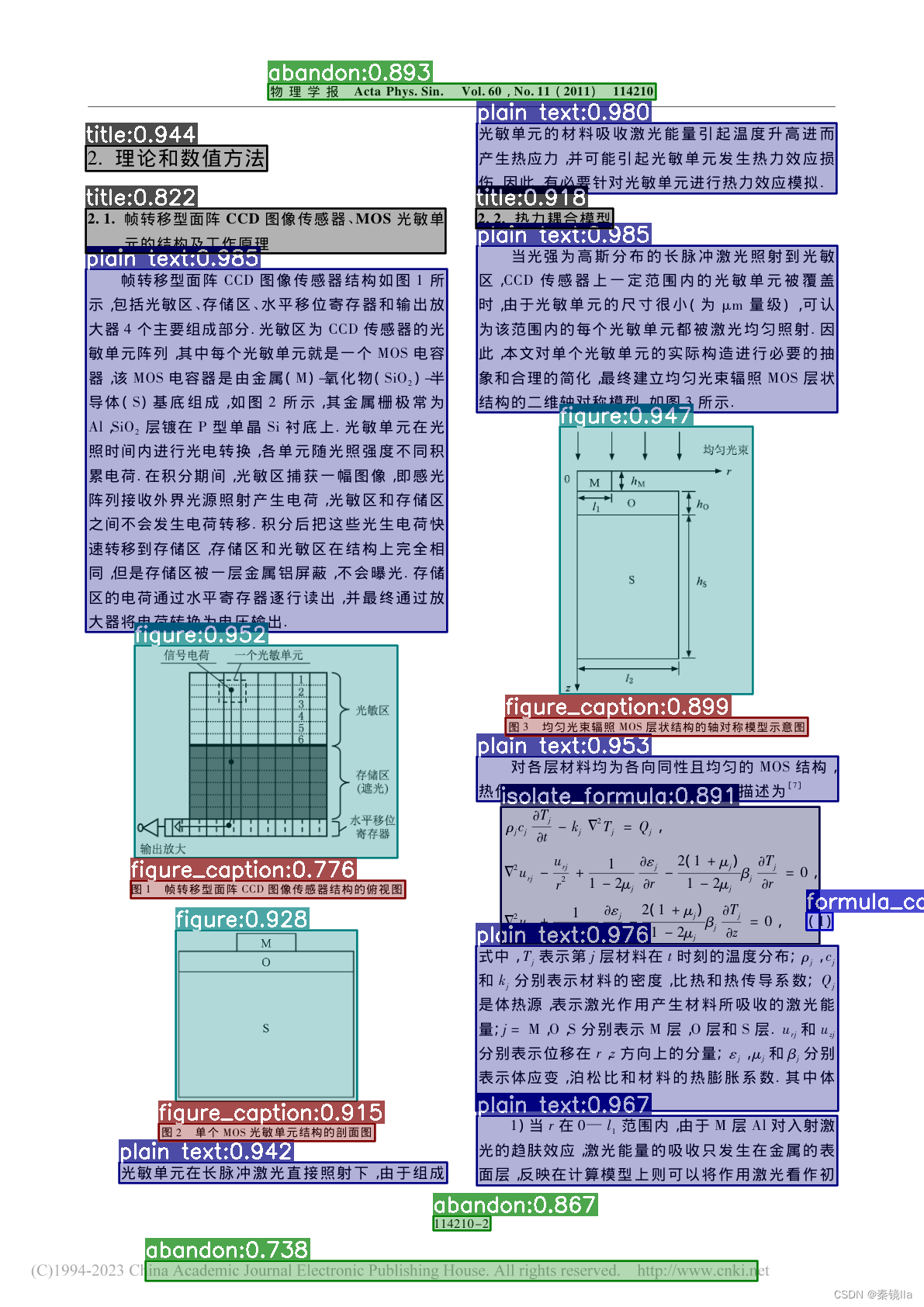
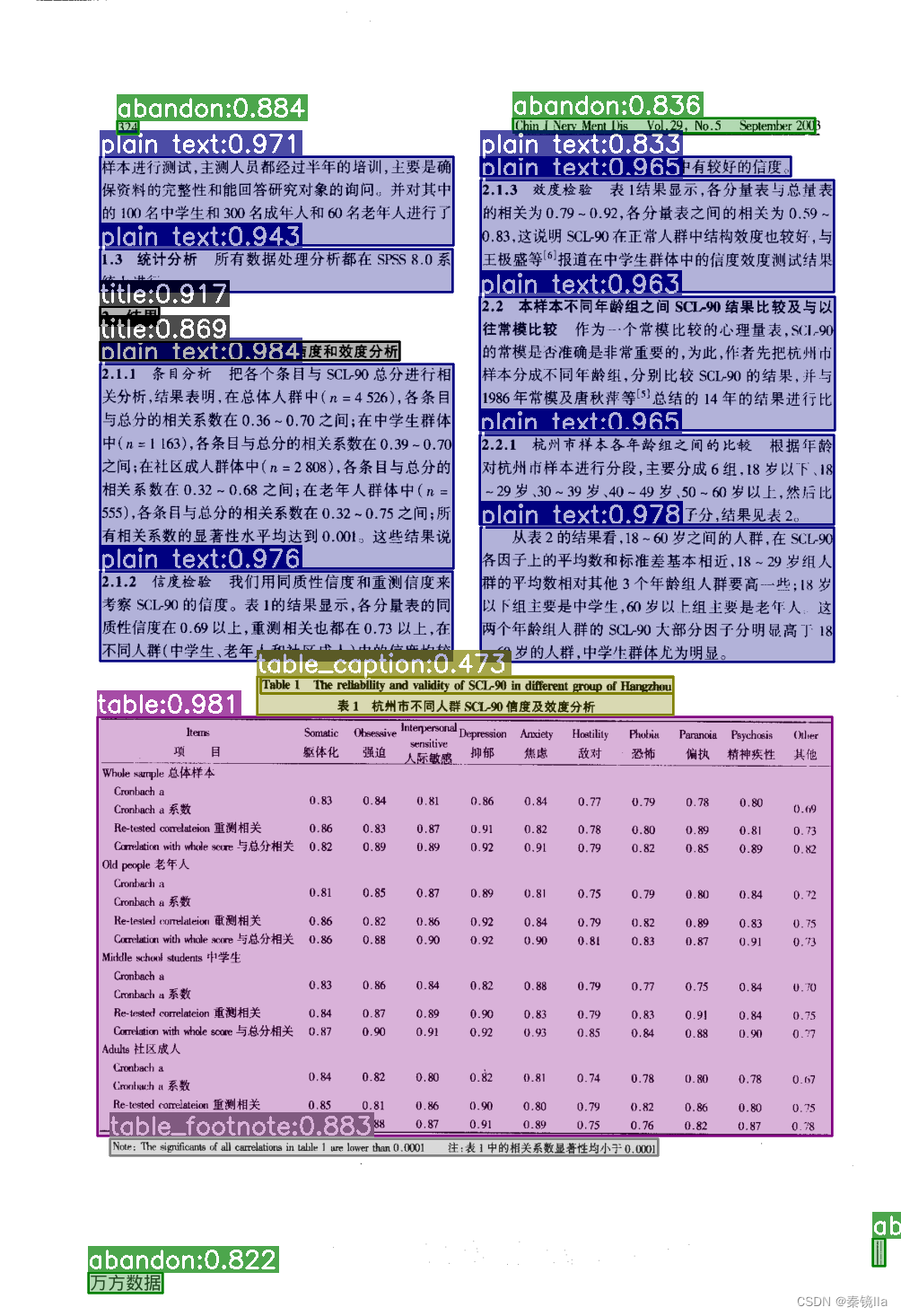
总结
本文是对PDF-Extract-Kit安装的简要教程,详细信息见官方文档:pdf-extract-kit官方中文文档![]() https://pdf-extract-kit.readthedocs.io/zh-cn/latest/index.html欢迎交流学习
https://pdf-extract-kit.readthedocs.io/zh-cn/latest/index.html欢迎交流学习

















 4704
4704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









