






1,MinerU(PDF-Extract-Kit...)
MinerU是opendatalab的开源项目,目标是提供一站式开源高质量数据提取工具,将PDF转换成Markdown和JSON格式。
2,PDF提取工具
https://github.com/opendatalab/PDF-Extract-Kit
包含Layout检测、公式检测、公式识别、OCR识别等文档解析核心任务的多个模型,并集成在开箱即用的开源项目中。
3,Layout检测
Layout检测支持两个模型
3.1、LayoutLMV3
https://github.com/microsoft/unilm/tree/master/layoutlmv3
LayoutLMv3的目标是成为一个通用的预训练模型,适用于以文本为中心和以图像为中心的文档AI任务。LayoutLMv3不仅在以文本为中心的任务中(包括表单理解、收据理解和文档视觉问答)性能优异,而且在以图像为中心的任务(如文档图像分类和文档布局分析)中也表现出色。
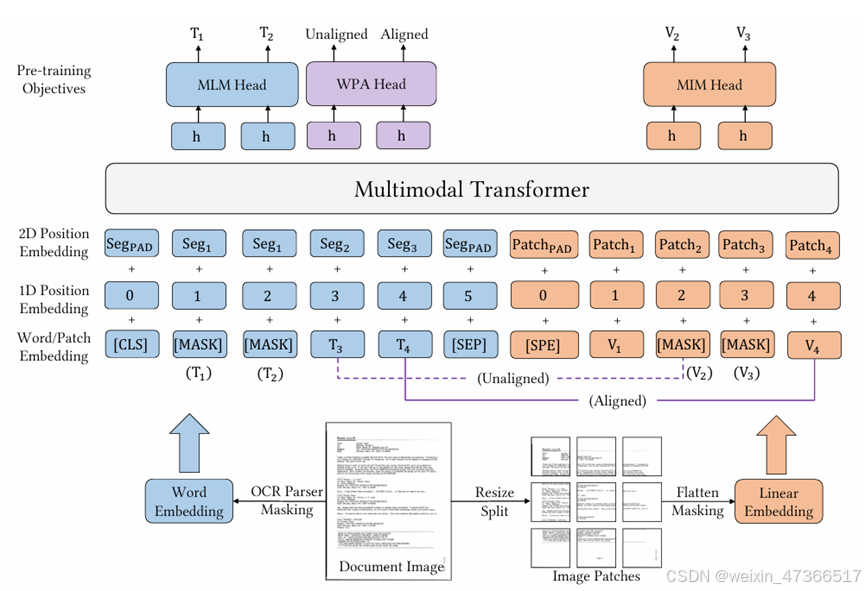
LayoutLMV3模型结构
3.2、DocLayout-YOLO
LayoutLMv3效果很好,但是速度比较慢。于此,opendatalab基于YOLO-v10训练了DocLayout-YOLO模型。
https://github.com/opendatalab/DocLayout-YOLO
YOLOv10是由清华大学提出的,遵循 YOLO 系列设计原则,实现实时端到端的高性能目标检测器。
DocLayout-YOLO在推理速度上快了很多,而且性能也非常优秀。
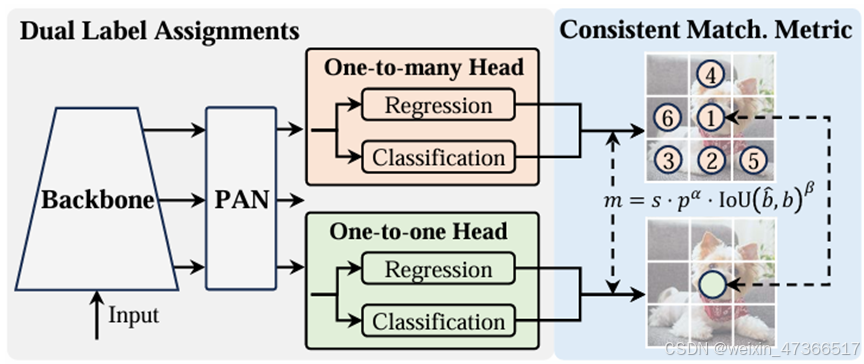
4、公式检测
公式检测,PDF-Extract-Kit 使用了基于 YOLOv8 finetune 的公式检测模型。
https://github.com/ultralytics/ultralytics
基于ultraytics的yolo平台,任何人都可以训练自己的yolo模型。
5、公式识别
5.1、UniMERNet
UniMERNet 也是opendatalab开源的实时公式检测模型。
https://github.com/opendatalab/UniMERNet
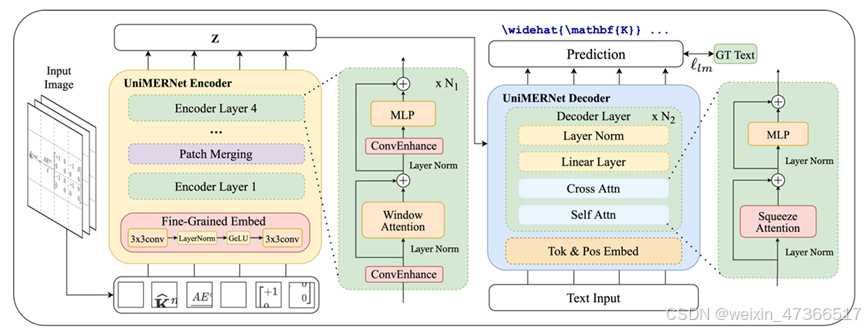
UniMER-Encoder融合了细粒度嵌入(FGE)、卷积增强(CE)以及移窗去除(RSW)技术,以提升识别能力。而UniMER-Decoder则采用了压缩注意力机制(SA),以此加快推理速度。
5.2、LaTeX-OCR
LaTeX-OCR在github上星标13k,但对于比较长的公式识别效果并不够好。
https://github.com/lukas-blecher/LaTeX-OCR
5.3、TexTeller
TexTeller 是一个端到端公式识别模型,基于 TrOCR 模型。TrOCR是一个轻量级的Transform OCR识别模型。
https://github.com/OleehyO/TexTeller
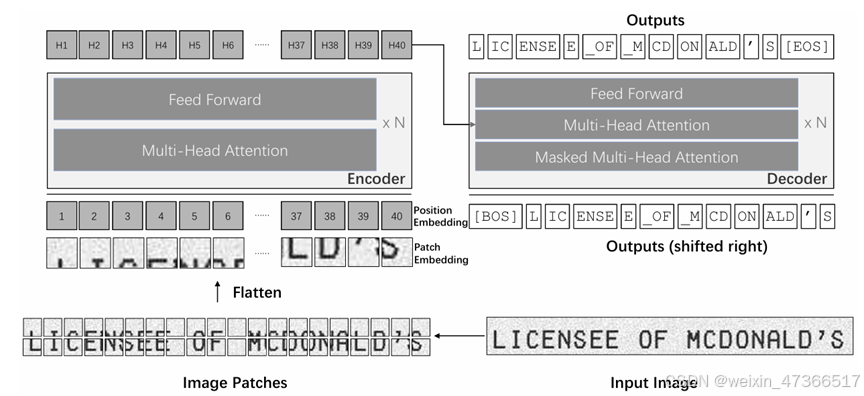
TrOCR是一种编码器-解码器模型,采用视觉Transformer作为编码器,文本Transformer作为解码器。
6 OCR 模型
6.1 PaddleOCR
MinerU使用了 PaddleOCR 模型。
https://github.com/PaddlePaddle/PaddleOCR
当然,基于 PaddleOCR 进行了修改,整合了公式检测、识别和文本检测、识别,最后输出统一的文本识别结果。
6.2 RapidOCR
rapidocr也是基于 PaddleOCR 的OCR推理模型,将原生 PaddleOCR 模型转换为 ONNX 模型用于推理,使用方便、而且速度更快。
https://github.com/RapidAI/RapidOCR
6 表格识别
6.1、StructEqTable
https://github.com/Alpha-Innovator/StructEqTable-Deploy
StructEqTable 是一个多模态大模型(视觉-语言),基于internVL模型进行finetune。
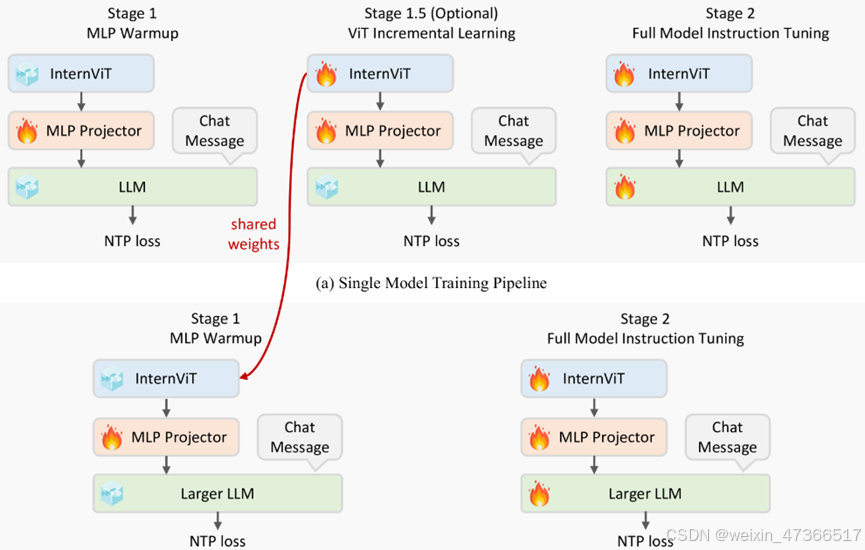
6.2、InternVL2.5
https://github.com/OpenGVLab/InternVL
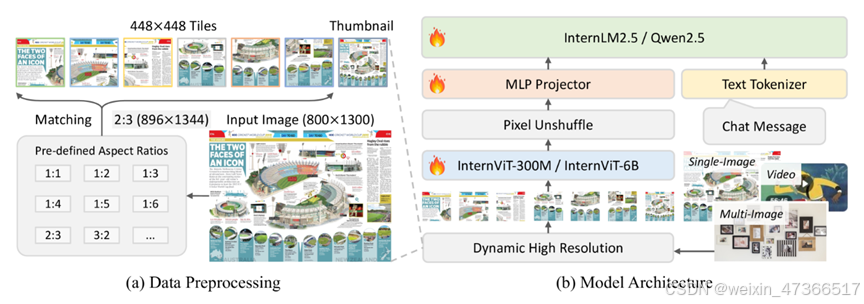
数据处理过程和模型结构
6.3、RapidTable
RapidTable是一个表格识别快速推理库,包含多个表格识别模型,基于ONNX进行推理。可以作为补充模型来考虑使用。
https://github.com/RapidAI/RapidTable
在线使用
开源工具以及足够丰富,但如果只是简单使用,比如pdf转excel、或者图片批量转 excel,在线工具会方便一些。
https://www.seefine.cc/docai/convert/image/excel/

















 3273
3273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









