







实现目标检测与发布话题的功能包
实现的结果 :
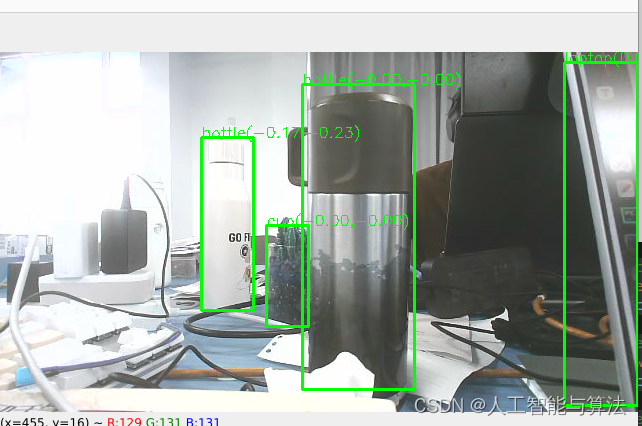
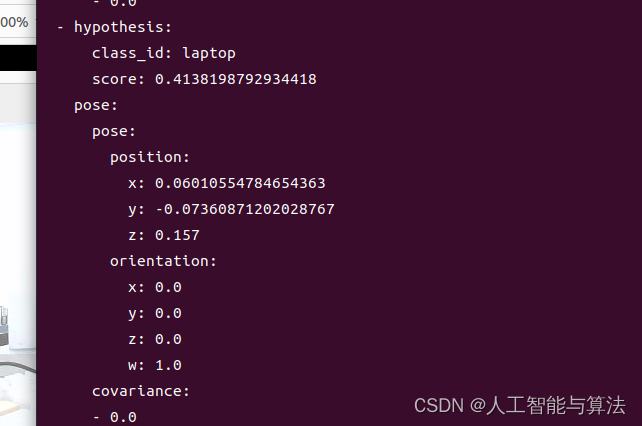
position 里面的x,y,z分别对应于检测出来的物体的基于相机坐标系的实际的三维坐标检测 ,目前是基于相机的坐标系要实现机械臂的自动抓取,还需要手眼标定。
目标检测使用的是YOLOv5的模型
二YOLO工作空间的配置
安装依赖
sudo apt update
sudo apt install python3-pip ros-$ROS_DISTRO-vision-msgs
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple yolov5
配置工作空间
sudo -p mkdir yolo_ros2_3d/src
cd yolo_ros2_3d/src
源码包
conlcon git -i 网址.git
编译
cd yolo_ros2_3d
source /opt/ros/humble/setup.bash
colcon build
source install/setup.bash
三运行程序
首先需要启动相机发布话题
cd ~/YOLO/ros2_ws
. ./install/setup.bash
ros2 launch orbbec_camera dabai_dcw.launch.py
查看话题
ros2 topic list
在运行程序之前首先需要启动深度相机方便获取话题
运行程序
cd ~/YOLO/yolo_ros2_3d
. ./install/setup.bash
ros2 run yolov5_ros2 yolo_detect_2d --ros-args -p device:=cpu -p image_topic:=/camera/color/image_raw -p show_result:=True -p image_topic_depth:=/camera/depth/image_raw -p camera_info:=/camera/depth/camera_info
参数说明
device 设备默认cpu
model 加载的识别的模型
imag_topic 彩色图像的话题
image_topic_depth 深度图像的话题
camera_info_topic 输入相机的参数
camera_info 可自定义在文件内部
show_result 是否展示结果默认是flase
pub_result_img 是否发布结果 默认是true
查看发布出来的数据
ros2 topic echo /yolo_result
yolo_result话题
self.yolo_result_pub = self.create_publisher(Detection2DArray, "yolo_result", 10)
self.result_msg = Detection2DArray()
yolo_result 的数据类型是 Detection2DArray()
# yolo_result层次关系是
self.result_msg.detections.clear()
self.result_msg.header.frame_id = "camera"
self.result_msg.header.stamp = self.get_clock().now().to_msg()#时间戳stamp
detection2d = Detection2D()# 检测框的对象处理检测数据
#detection2d的层次
# 以像数坐标系检测的物体的中心位置
detection2d.bbox.center.x = center_x
detection2d.bbox.center.y = center_y
# 以像数坐标系检测的物体的框的大小
detection2d.bbox.size_x = float(x2-x1)
detection2d.bbox.size_y = float(y2-y1)
obj_pose 对象是 obj_pose = ObjectHypothesisWithPose()「#存储detection2d处理后的数据
# obj_pose的层次
obj_pose.hypothesis.class_id = name #识别到的类别
obj_pose.hypothesis.score = float(scores[index])#识别物体的得分
#具体的位置坐标信息在:
#相机坐标系下的实际物体的三维坐标以米为单位
obj_pose.pose.pose.position.x = world_x
obj_pose.pose.pose.position.y = world_y
obj_pose.pose.pose.position.z = depth_value_in_meters
detection2d.results.append(obj_pose)#对象obj_pose添加进detection2d的result里
self.result_msg.detections.append(detection2d)#detection添加进话题里
源代码
首先是获取识别物体然后通过识别的框去计算出以物体中心点的坐标去获取深度图像的深度值。
cv_tool.py
# 导入所需的库
# Import the required libraries
import cv2 # OpenCV library for image processing
import numpy as np # NumPy library for array and matrix operations
# 相机内参矩阵K,包括相机的焦距和主点坐标
# Camera intrinsic matrix K, including camera's focal length and principal point coordinates
K = [[360.2007751464844, 0, 323.737548828125],
[0, 360.2007751464844, 176.65692138671875],
[0, 0, 1]]
# 相机畸变参数D,用于校正图像畸变
# Camera distortion parameters D, used for correcting image distortion
D = [-0.019475774839520454, 0.003557757008820772,
0, 0, 0]
# 定义一个函数px2xy,用于将像素坐标转换为相机坐标系下的二维坐标
# Define a function px2xy to convert pixel coordinates to 2D coordinates in camera coordinate system
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7691
7691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









