







微分方程
欧拉法
前向欧拉: y n + 1 = y n + h f ( x n , y n ) y_{n+1} = y_n + hf(x_n, y_n) yn+1=yn+hf(xn,yn)
后退欧拉: y n + 1 = y n + h f ( x n + 1 , y n + 1 ) y_{n+1} = y_n + hf(x_{n+1}, y_{n+1}) yn+1=yn+hf(xn+1,yn+1)
两步欧拉: y n + 1 = y n − 1 + 2 h f ( x n , y n ) y_{n+1} = y_{n-1} + 2hf(x_n, y_n) yn+1=yn−1+2hf(xn,yn)
变形欧拉: y n + 1 = y n + h f ( x n + 1 2 , y n + 1 2 ) y_{n+1} = y_n + hf(x_{n+\frac{1}{2}}, y_{n+\frac{1}{2}}) yn+1=yn+hf(xn+21,yn+21)
改进欧拉: KaTeX parse error: \tag works only in display equations
误差分析
截断方法误差
前向欧拉: h 2 2 y ( 2 ) ( η ) \frac{h^2}{2}y^{(2)}(\eta) 2h2y(2)(η)
后退欧拉: h 2 2 y ( 2 ) ( η ) \frac{h^2}{2}y^{(2)}(\eta) 2h2y(2)(η)
两步欧拉: h 3 3 y ( 3 ) ( η ) \frac{h^3}{3}y^{(3)}(\eta) 3h3y(3)(η)
变形欧拉: h 3 24 y ( 3 ) ( η ) \frac{h^3}{24}y^{(3)}(\eta) 24h3y(3)(η)
改进欧拉: − h 3 12 y ( 3 ) ( η ) -\frac{h^3}{12}y^{(3)}(\eta) −12h3y(3)(η)
- O ( h n + 1 ) O(h^{n+1}) O(hn+1)等价于有 n n n阶精度
前向欧拉累积方法误差
δ
n
+
1
=
(
1
+
h
∂
f
∂
y
)
δ
n
+
h
2
2
y
(
2
)
(
η
)
≤
(
1
+
h
M
)
δ
n
+
h
2
2
L
≤
1
−
A
n
1
−
A
B
≤
k
h
M
h
2
2
L
=
O
(
h
)
\delta_{n+1} = (1+h\frac{\partial f}{\partial y})\delta_n + \frac{h^2}{2}y^{(2)}(\eta) \leq (1+hM)\delta_n + \frac{h^2}{2}L\leq \frac{1-A^n}{1-A}B \leq \frac{k}{hM}\frac{h^2}{2}L = O(h)
δn+1=(1+h∂y∂f)δn+2h2y(2)(η)≤(1+hM)δn+2h2L≤1−A1−AnB≤hMk2h2L=O(h)
前向欧拉累积舍入误差
δ
n
+
1
=
(
1
+
h
∂
f
∂
y
)
δ
n
+
1
2
⋅
1
0
−
m
≤
(
1
+
h
M
)
δ
n
+
1
2
⋅
1
0
−
m
≤
1
−
A
n
1
−
A
B
≤
k
2
h
M
⋅
1
0
−
m
=
O
(
1
h
)
\delta_{n+1} = (1+h\frac{\partial f}{\partial y})\delta_n + \frac{1}{2}\cdot 10^{-m} \leq (1+hM)\delta_n + \frac{1}{2}\cdot 10^{-m} \leq \frac{1-A^n}{1-A}B \leq \frac{k}{2hM}\cdot 10^{-m} = O(\frac{1}{h})
δn+1=(1+h∂y∂f)δn+21⋅10−m≤(1+hM)δn+21⋅10−m≤1−A1−AnB≤2hMk⋅10−m=O(h1)
改进欧拉累积方法误差
{
δ
ˉ
n
+
1
≤
(
1
+
h
M
)
δ
n
+
L
2
⋅
h
2
δ
n
+
1
≤
δ
n
+
h
2
M
δ
n
+
h
2
M
δ
ˉ
n
+
1
+
T
⋅
h
3
12
δ
n
≤
(
1
+
h
⋅
M
+
h
2
2
⋅
M
2
)
δ
n
−
1
+
(
L
M
4
+
T
12
)
h
3
=
∣
1
−
(
1
+
h
M
+
h
2
2
M
2
)
n
1
−
(
1
+
h
M
+
h
2
2
M
2
)
∣
(
L
M
4
+
T
12
)
h
3
=
∣
1
−
(
1
+
h
M
+
h
2
2
M
2
)
n
(
h
M
+
h
2
2
M
2
)
∣
(
L
M
4
+
T
12
)
h
3
\begin{cases} \bar \delta_{n+1} \leq (1+hM)\delta_n + \frac{L}{2}\cdot h^2 \\ \delta_{n+1} \leq \delta_n + \frac{h}{2}M\delta_n + \frac{h}{2}M\bar\delta_{n+1} + \frac{T\cdot h^3}{12} \end{cases} \\ \delta_{n} \leq (1+h\cdot M + \frac{h^2}{2}\cdot M^2)\delta_{n-1} + (\frac{LM}{4} + \frac{T}{12})h^3 \\ = |\frac{1 - (1+hM+\frac{h^2}{2}M^2)^n}{1 - (1+hM+\frac{h^2}{2}M^2)}|(\frac{LM}{4} + \frac{T}{12})h^3 \\ = |\frac{1 - (1+hM+\frac{h^2}{2}M^2)^n}{(hM+\frac{h^2}{2}M^2)}|(\frac{LM}{4} + \frac{T}{12})h^3 \\
{δˉn+1≤(1+hM)δn+2L⋅h2δn+1≤δn+2hMδn+2hMδˉn+1+12T⋅h3δn≤(1+h⋅M+2h2⋅M2)δn−1+(4LM+12T)h3=∣1−(1+hM+2h2M2)1−(1+hM+2h2M2)n∣(4LM+12T)h3=∣(hM+2h2M2)1−(1+hM+2h2M2)n∣(4LM+12T)h3
改进欧拉累积舍入误差
{
δ
ˉ
n
+
1
≤
(
1
+
h
M
)
δ
n
+
1
2
⋅
1
0
−
m
δ
n
+
1
≤
δ
n
+
h
2
M
δ
n
+
h
2
M
δ
ˉ
n
+
1
+
1
2
⋅
1
0
−
m
δ
n
≤
(
1
+
h
⋅
M
+
h
2
2
⋅
M
2
)
δ
n
−
1
+
(
1
+
h
M
2
)
⋅
1
2
⋅
1
0
−
m
=
∣
1
−
(
1
+
h
M
+
h
2
2
M
2
)
n
1
−
(
1
+
h
M
+
h
2
2
M
2
)
∣
(
1
+
h
M
2
)
⋅
1
2
⋅
1
0
−
m
\begin{cases} \bar \delta_{n+1} \leq (1+hM)\delta_n + \frac{1}{2}\cdot 10^{-m} \\ \delta_{n+1} \leq \delta_n + \frac{h}{2}M\delta_n + \frac{h}{2}M\bar\delta_{n+1} + \frac{1}{2}\cdot 10^{-m} \end{cases} \\ \delta_{n} \leq (1+h\cdot M + \frac{h^2}{2}\cdot M^2)\delta_{n-1} + (1 + \frac{hM}{2})\cdot \frac{1}{2}\cdot 10^{-m} \\ = |\frac{1 - (1+hM+\frac{h^2}{2}M^2)^n}{1 - (1+hM+\frac{h^2}{2}M^2)}|(1 + \frac{hM}{2})\cdot \frac{1}{2}\cdot 10^{-m} \\
{δˉn+1≤(1+hM)δn+21⋅10−mδn+1≤δn+2hMδn+2hMδˉn+1+21⋅10−mδn≤(1+h⋅M+2h2⋅M2)δn−1+(1+2hM)⋅21⋅10−m=∣1−(1+hM+2h2M2)1−(1+hM+2h2M2)n∣(1+2hM)⋅21⋅10−m
龙格-库塔
二阶龙格-库塔
y n + 1 = y n + h [ λ 1 K 1 + λ 2 K 2 ] y_{n+1} = y_n + h[\lambda_1 K_1 + \lambda_2 K_2] yn+1=yn+h[λ1K1+λ2K2]
K
1
=
f
(
x
n
,
y
n
)
K_1 = f(x_n, y_n)
K1=f(xn,yn),
K
2
=
f
(
x
n
+
p
h
,
y
n
+
p
h
K
1
)
K_2 = f(x_{n+ph}, y_n+phK_1)
K2=f(xn+ph,yn+phK1)
y
n
+
1
=
y
n
+
h
[
λ
1
f
(
x
n
,
y
n
)
+
λ
2
f
(
x
n
+
p
h
,
y
n
+
p
h
K
1
)
]
=
y
n
+
h
(
λ
1
+
λ
2
)
f
(
x
n
,
y
n
)
+
∂
f
∂
x
p
h
+
∂
f
∂
y
p
h
K
1
=
y
n
+
h
(
λ
1
+
λ
2
)
f
(
x
n
,
y
n
)
+
(
∂
f
∂
x
+
∂
f
∂
y
f
)
λ
2
p
h
2
y_{n+1} = y_n + h[\lambda_1 f(x_n, y_n) + \lambda_2 f(x_{n+ph}, y_n+phK_1)] \\ = y_n + h(\lambda_1+\lambda_2) f(x_n, y_n) + \frac{\partial f}{\partial x}ph + \frac{\partial f}{\partial y}phK_1 \\ = y_n + h(\lambda_1+\lambda_2) f(x_n, y_n) + (\frac{\partial f}{\partial x}+\frac{\partial f}{\partial y}f)\lambda_2 ph^2
yn+1=yn+h[λ1f(xn,yn)+λ2f(xn+ph,yn+phK1)]=yn+h(λ1+λ2)f(xn,yn)+∂x∂fph+∂y∂fphK1=yn+h(λ1+λ2)f(xn,yn)+(∂x∂f+∂y∂ff)λ2ph2
四阶龙格-库塔
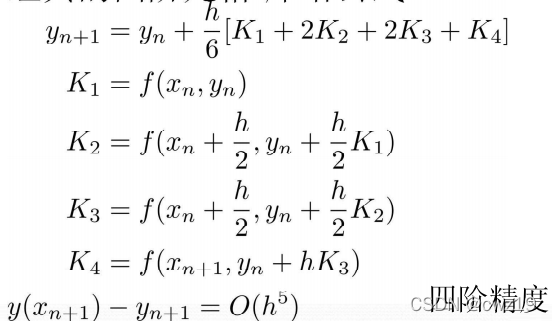
线性多步法
显性公式
y
n
+
1
=
y
n
+
h
∑
k
=
0
m
β
k
f
n
−
k
R
(
f
)
=
f
′
′
(
η
)
2
∫
x
n
x
n
+
1
Π
k
=
0
m
(
x
−
x
n
−
k
)
d
x
y_{n+1} = y_n + h\sum_{k=0}^{m} \beta_k f_{n-k} \\ R(f) = \frac{f''(\eta)}{2}\int_{x_n}^{x_n+1}\Pi_{k=0}^m(x-x_{n-k})dx
yn+1=yn+hk=0∑mβkfn−kR(f)=2f′′(η)∫xnxn+1Πk=0m(x−xn−k)dx
隐性公式
y
n
+
1
=
y
n
+
h
∑
k
=
0
m
β
k
f
n
+
1
−
k
R
(
f
)
=
f
′
′
(
η
)
2
∫
x
n
x
n
+
1
Π
k
=
0
m
(
x
−
x
n
+
1
−
k
)
d
x
y_{n+1} = y_n + h\sum_{k=0}^{m} \beta_k f_{n+1-k} \\ R(f) = \frac{f''(\eta)}{2}\int_{x_n}^{x_n+1}\Pi_{k=0}^m(x-x_{n+1-k})dx
yn+1=yn+hk=0∑mβkfn+1−kR(f)=2f′′(η)∫xnxn+1Πk=0m(x−xn+1−k)dx
隐性公式优于显示公式 (显示预测、隐式校正)
m
=
1
;
R
(
f
隐
)
=
−
h
3
12
f
′
′
(
η
)
;
R
(
f
显
)
=
5
h
3
12
f
′
′
(
η
)
m
=
2
;
R
(
f
隐
)
=
−
h
3
24
f
′
′
′
(
η
)
;
R
(
f
显
)
=
9
h
4
24
f
′
′
′
(
η
)
m = 1 ; R(f_隐) = -\frac{h^3}{12}f''(\eta); R(f_显) = \frac{5h^3}{12}f''(\eta) \\ m = 2 ; R(f_隐) = -\frac{h^3}{24}f'''(\eta); R(f_显) = \frac{9h^4}{24}f'''(\eta)\\
m=1;R(f隐)=−12h3f′′(η);R(f显)=125h3f′′(η)m=2;R(f隐)=−24h3f′′′(η);R(f显)=249h4f′′′(η)
泰勒展开构造
例如: 令 y n + 1 = y n + h [ a 0 f n + a 1 f n − 1 + a 2 f n − 2 ] y_{n+1} = y_n + h[a_0 f_n + a_1 f_{n-1} + a_2 f_{n-2}] yn+1=yn+h[a0fn+a1fn−1+a2fn−2]
解: 把 y n + 1 , f n , f n − 1 . . . y_{n+1}, f_n, f_{n-1} ... yn+1,fn,fn−1...都泰勒展开,让尽可能多的项被消掉
方程求根
迭代法
-
问题: 求解 y = f ( x ) y= f(x) y=f(x)
求解: 由于 f ( x ) = 0 f(x) = 0 f(x)=0,因此构造 ϕ ( x ) = x ± f ( x ) \phi(x)=x\pm f(x) ϕ(x)=x±f(x),迭代求取 x n + 1 = ϕ ( x n ) x_{n+1} = \phi(x_n) xn+1=ϕ(xn)有 lim n → ∞ x n = x ∗ \lim_{n\rightarrow\infty}x_n = x^* limn→∞xn=x∗
-
定理: 若 1 x ∈ [ a , b ] , ϕ ( x ) ∈ [ a , b ] 2 0 < L < 1 , ∣ ϕ ( x ) − ϕ ( x ′ ) ∣ ≤ L ∣ x − x ′ ∣ ⇒ x n ^1 x\in[a,b], \phi(x)\in [a,b] ^2 0<L<1, |\phi(x)-\phi(x')|\leq L|x-x'| \Rightarrow x_n 1x∈[a,b],ϕ(x)∈[a,b]20<L<1,∣ϕ(x)−ϕ(x′)∣≤L∣x−x′∣⇒xn收敛到 x ∗ x^* x∗
(第二个条件等价于区间内导数恒小于一)
-
定理: 若 1 ϕ ′ ( x ) ^1 \phi'(x) 1ϕ′(x)在 x ∗ x^* x∗附近连续 2 ∣ ϕ ′ ( x ∗ ) ∣ < 1 ⇒ x n ^2 |\phi'(x^*)|<1 \Rightarrow x_n 2∣ϕ′(x∗)∣<1⇒xn在 x ∗ x^* x∗附近收敛到 x ∗ x^* x∗
方法: 令 ϕ ( x ) = x + a f ( x ) \phi(x) = x + af(x) ϕ(x)=x+af(x)、要求 ∣ ϕ ′ ( x ∗ ) ∣ < 1 |\phi'(x^*)|<1 ∣ϕ′(x∗)∣<1、给 x x x求 a a a或给 a a a求 x x x
-
x n + 1 − x ∗ = ϕ ( p ) ( x ∗ ) e p ⇒ x_{n+1}-x^* = \phi^{(p)}(x^*)e^{p} \Rightarrow xn+1−x∗=ϕ(p)(x∗)ep⇒ p阶收敛 ⇒ e n + 1 = 1 p ! ⋅ e n p \Rightarrow e_{n+1}=\frac{1}{p!}\cdot e_n^p ⇒en+1=p!1⋅enp
-
事后估计(给出误差上界): ∣ x k − x ∗ ∣ ≤ 1 1 − L ∣ x k + 1 − x k ∣ |x_k-x^*|\leq\frac{1}{1-L}|x_{k+1}-x_k| ∣xk−x∗∣≤1−L1∣xk+1−xk∣
事前估计(给出迭代次数): ∣ x k − x ∗ ∣ ≤ L k 1 − L ∣ x 1 − x 0 ∣ |x_k-x^*|\leq\frac{L^k}{1-L}|x_{1}-x_0| ∣xk−x∗∣≤1−LLk∣x1−x0∣
牛顿法
-
ϕ ( x ) = x + a f ( x ) = x − f ( x ) f ′ ( x ) \phi(x) = x + af(x) = x - \frac{f(x)}{f'(x)} ϕ(x)=x+af(x)=x−f′(x)f(x) 二阶收敛
-
M 2 ∣ e 0 ∣ < 1 \frac{M}{2}|e_0|<1 2M∣e0∣<1 ⇒ \Rightarrow ⇒ 收敛 (证明 e n ≤ 2 M ( M 2 ∣ e 0 ∣ ) 2 n + 1 e^n \leq \frac{2}{M}(\frac{M}{2}|e_0|)^{2^{n+1}} en≤M2(2M∣e0∣)2n+1)
-
牛顿下山法(可以不用在意初值)
x ˉ k + 1 = x k − f ( x ) f ′ ( x ) x k + 1 = { x ˉ k + 1 , i f ∣ f ( x ˉ k + 1 ) ∣ < ∣ f ( x k ) ∣ λ x ˉ k + 1 + ( 1 − λ ) x k , o t h e r w i s e \bar x_{k+1} = x_k - \frac{f(x)}{f'(x)} \\ x_{k+1} = \begin{cases} \bar x_{k+1},if\space |f(\bar x_{k+1})|<|f(x_k)| \\ \lambda\bar x_{k+1} + (1-\lambda)x_k, otherwise \end{cases} xˉk+1=xk−f′(x)f(x)xk+1={xˉk+1,if ∣f(xˉk+1)∣<∣f(xk)∣λxˉk+1+(1−λ)xk,otherwise -
m重根
若 f ( x ) = ( x − x ∗ ) m g ( x ) f(x) = (x-x^*)^mg(x) f(x)=(x−x∗)mg(x)则有 ϕ ( x ) = x − f ( x ) f ′ ( x ) ⇒ ϕ ′ ( x ) = 1 − 1 m \phi(x) = x - \frac{f(x)}{f'(x)} \Rightarrow \phi'(x)=1-\frac{1}{m} ϕ(x)=x−f′(x)f(x)⇒ϕ′(x)=1−m1
法一: ϕ ( x ) = x − m f ( x ) f ′ ( x ) \phi(x) = x - m\frac{f(x)}{f'(x)} ϕ(x)=x−mf′(x)f(x)
法二: f ( x ) = ( x − x ∗ ) g ( x ) f(x) = (x-x^*)g(x) f(x)=(x−x∗)g(x)
弦截法&抛物线法
-
弦截法
x k + 1 = x k − f ( x k ) f [ x k − 1 − x k ] x ∈ [ x ∗ − δ , x ∗ + δ ] , ∣ e n + 1 ∣ ≤ M ∣ e n ∣ ∣ e n − 1 ∣ ≤ ( M δ ) n M , M = m a x f ′ ′ ( η ) 2 ⋅ m i n f ′ ( ξ ) x_{k+1} = x_k - \frac{f(x_k)}{f[x_{k-1}-x_k]} \\ x\in [x^*-\delta, x^*+\delta], |e_{n+1}| \leq M|e_n||e_{n-1}|\leq\frac{(M\delta)^n}{M}, M = \frac{maxf''(\eta)}{2\cdot minf'(\xi)} xk+1=xk−f[xk−1−xk]f(xk)x∈[x∗−δ,x∗+δ],∣en+1∣≤M∣en∣∣en−1∣≤M(Mδ)n,M=2⋅minf′(ξ)maxf′′(η) -
抛物线法
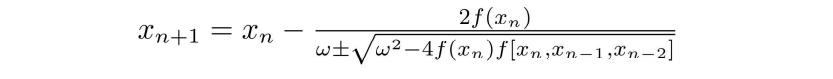
线性方程组
高斯法
-
高斯消去: 加减法 n 3 3 \frac{n^3}{3} 3n3次、乘除法 n 3 3 \frac{n^3}{3} 3n3次、各阶顺序主子式不为零
-
主元素消去: 列主元素消去(交换行)、行主元素消去(交换列)、全面主元素消去
-
三角分解: A = L U A=LU A=LU存在且唯一 (其中L是单位下三角U是上三角阵)
三角分解
- 直接法: 欲求 A x = b Ax = b Ax=b、分解为 A = L U A=LU A=LU、先用 L y = b Ly=b Ly=b求得 y y y、再用 U x = y Ux=y Ux=y求得 x x x
- 平方根法: A A A为对称阵、可分解为 A = L D L T = ( L D 1 2 ) ( D 1 2 L T ) A=LDL^T=(LD^{\frac{1}{2}})(D^{\frac{1}{2}}L^T) A=LDLT=(LD21)(D21LT)、先用 y = ( L D 1 2 ) b y=(LD^{\frac{1}{2}})b y=(LD21)b求得 y y y、再用 ( D 1 2 L T ) x = y (D^{\frac{1}{2}}L^T)x=y (D21LT)x=y求得 x x x
范数
-
向量范数
- ∣ ∣ x ∣ ∣ ≥ 0 , x ≠ 0 ||x|| \geq 0, x\neq 0 ∣∣x∣∣≥0,x=0
- $ ||cx|| \geq c||x||$
- ∣ ∣ x + y ∣ ∣ ≤ ∣ ∣ x ∣ ∣ + ∣ ∣ y ∣ ∣ ||x+y|| \leq ||x|| + ||y|| ∣∣x+y∣∣≤∣∣x∣∣+∣∣y∣∣
-
矩阵范数(需额外满足)
- ∣ ∣ A B ∣ ∣ ≤ ∣ ∣ A ∣ ∣ ⋅ ∣ ∣ B ∣ ∣ ||AB|| \leq ||A||\cdot ||B|| ∣∣AB∣∣≤∣∣A∣∣⋅∣∣B∣∣
- ∣ ∣ A x ∣ ∣ ≤ ∣ ∣ A ∣ ∣ ⋅ ∣ ∣ x ∣ ∣ ||Ax|| \leq ||A||\cdot ||x|| ∣∣Ax∣∣≤∣∣A∣∣⋅∣∣x∣∣ , 称 ∣ ∣ A ∣ ∣ ||A|| ∣∣A∣∣为与向量范数相容的矩阵范数
-
范数
- ∣ ∣ x ∣ ∣ 1 = ∑ i ∣ x i ∣ ||x||_1 = \sum_i |x_i| ∣∣x∣∣1=∑i∣xi∣, 列范数 ∣ ∣ A ∣ ∣ 1 = max j ∑ i ∣ x i j ∣ ||A||_1 = \max_j\sum_i |x_{ij}| ∣∣A∣∣1=maxj∑i∣xij∣
- ∣ ∣ x ∣ ∣ 2 = ∑ i x i 2 ||x||_2 = \sqrt{\sum_ix_i^2} ∣∣x∣∣2=∑ixi2, $||A||2 = \sqrt{\lambda{max}(A^TA)} $
- ∣ ∣ x ∣ ∣ ∞ = m a x i ∣ x i ∣ ||x||_\infty = max_i |x_i| ∣∣x∣∣∞=maxi∣xi∣, 列范数 ∣ ∣ A ∣ ∣ ∞ = max i ∑ j ∣ x i j ∣ ||A||_\infty = \max_i\sum_j |x_{ij}| ∣∣A∣∣∞=maxi∑j∣xij∣
-
误差分析
- ( A + δ A ) ( x + δ x ) = b ⇒ ∣ ∣ δ x ∣ ∣ ∣ ∣ x ∣ ∣ = ∣ ∣ A ∣ ∣ ⋅ ∣ ∣ A − 1 ∣ ∣ ⋅ ∣ ∣ δ A ∣ ∣ ∣ ∣ A ∣ ∣ (A+\delta A)(x+\delta x) = b \Rightarrow \frac{||\delta x||}{||x||} = ||A|| \cdot ||A^{-1}||\cdot \frac{||\delta A||}{||A||} (A+δA)(x+δx)=b⇒∣∣x∣∣∣∣δx∣∣=∣∣A∣∣⋅∣∣A−1∣∣⋅∣∣A∣∣∣∣δA∣∣
- A ( x + δ x ) = ( b + δ b ) ⇒ ∣ ∣ δ x ∣ ∣ ∣ ∣ x ∣ ∣ = ∣ ∣ A ∣ ∣ ⋅ ∣ ∣ A − 1 ∣ ∣ ⋅ ∣ ∣ δ b ∣ ∣ ∣ ∣ b ∣ ∣ A(x+\delta x) = (b+\delta b) \Rightarrow \frac{||\delta x||}{||x||} = ||A|| \cdot ||A^{-1}||\cdot \frac{||\delta b||}{||b||} A(x+δx)=(b+δb)⇒∣∣x∣∣∣∣δx∣∣=∣∣A∣∣⋅∣∣A−1∣∣⋅∣∣b∣∣∣∣δb∣∣
- ( A + δ A ) ( x + δ x ) = ( b + δ b ) ⇒ ∣ ∣ δ x ∣ ∣ ∣ ∣ x ∣ ∣ = ∣ ∣ A ∣ ∣ ⋅ ∣ ∣ A − 1 ∣ ∣ ⋅ ( ∣ ∣ δ A ∣ ∣ ∣ ∣ A ∣ ∣ + ∣ ∣ δ b ∣ ∣ ∣ ∣ b ∣ ∣ ) (A+\delta A)(x+\delta x) = (b+\delta b) \Rightarrow \frac{||\delta x||}{||x||} = ||A|| \cdot ||A^{-1}||\cdot (\frac{||\delta A||}{||A||}+\frac{||\delta b||}{||b||}) (A+δA)(x+δx)=(b+δb)⇒∣∣x∣∣∣∣δx∣∣=∣∣A∣∣⋅∣∣A−1∣∣⋅(∣∣A∣∣∣∣δA∣∣+∣∣b∣∣∣∣δb∣∣)
-
条件数 (条件数过大称为病态) c o n d ( A ) = ∣ ∣ A ∣ ∣ ⋅ ∣ ∣ A − 1 ∣ ∣ cond(A) = ||A||\cdot ||A^{-1}|| cond(A)=∣∣A∣∣⋅∣∣A−1∣∣
- c o n d ( A ) ≥ 1 cond(A)\geq 1 cond(A)≥1, c o n d ( A ) = 1 ⇔ A = I cond(A)=1 \Leftrightarrow A=I cond(A)=1⇔A=I
- c o n d ( A ) = c o n d ( A − 1 ) cond(A) = cond(A^{-1}) cond(A)=cond(A−1)
- c o n d ( c A ) = c o n d ( A ) cond(cA) = cond(A) cond(cA)=cond(A)
- c o n d 2 ( A ) ≥ λ m a x λ m i n cond_2(A) \geq \frac{\lambda_{max}}{\lambda_{min}} cond2(A)≥λminλmax
-
事后估计
∣ ∣ x − x ∗ ∣ ∣ ∣ ∣ x ∗ ∣ ∣ = ∣ ∣ A ∣ ∣ ⋅ ∣ ∣ A − 1 ∣ ∣ ⋅ ∣ ∣ b − A x ∣ ∣ ∣ ∣ b ∣ ∣ \frac{||x - x^*||}{||x^*||} = ||A|| \cdot ||A^{-1}||\cdot \frac{||b-Ax||}{||b||} ∣∣x∗∣∣∣∣x−x∗∣∣=∣∣A∣∣⋅∣∣A−1∣∣⋅∣∣b∣∣∣∣b−Ax∣∣
迭代法
A x = b ⇒ ( D + L + U ) x = b ⇒ x ( k + 1 ) = B x ( k ) + f Ax=b \Rightarrow (D+L+U)x = b \Rightarrow x^{(k+1)} = Bx^{(k)}+f Ax=b⇒(D+L+U)x=b⇒x(k+1)=Bx(k)+f
-
雅可比法
x ( k + 1 ) = − D − 1 ( L + U ) x ( k ) + − D − 1 b = B x + f x^{(k+1)} = -D^{-1}(L+U)x^{(k)}+-D^{-1}b = Bx+f x(k+1)=−D−1(L+U)x(k)+−D−1b=Bx+f -
G-S法
x ( k + 1 ) = − ( D + L ) − 1 U x ( k ) + − ( D + L ) − 1 b = B x + f x^{(k+1)} = -(D+L)^{-1}Ux^{(k)}+-(D+L)^{-1}b= Bx+f x(k+1)=−(D+L)−1Ux(k)+−(D+L)−1b=Bx+f -
定理:
-
ρ ( B ) = m a x i ∣ λ i ∣ < 1 ⇔ \rho(B) = max_i|\lambda_i| \lt 1 \Leftrightarrow ρ(B)=maxi∣λi∣<1⇔ 迭代法收敛
-
$||B|| \lt 1 \Rightarrow $ 迭代法收敛 (证明: B x = λ x ⇒ ∣ ∣ B ∣ ∣ ≥ ∣ ∣ λ ∣ ∣ Bx=\lambda x \Rightarrow ||B||\geq||\lambda|| Bx=λx⇒∣∣B∣∣≥∣∣λ∣∣)
-
A是严格对角优势阵 ⇒ \Rightarrow ⇒ 雅可比法&G-S法收敛
-
A是正定对称阵 ⇒ \Rightarrow ⇒ G-S法收敛
-
逐次超松弛迭代
- SOR法: 由G-S可知、加入松弛因子 w w w、整理可得
x ( k + 1 ) = x ( k ) + D − 1 [ b − L x ( k + 1 ) − ( D + U ) x ( k ) ] x ( k + 1 ) = x ( k ) + w D − 1 [ b − L x ( k + 1 ) − ( D + U ) x ( k ) ] x ( k + 1 ) = ( D + w L ) − 1 [ ( 1 − w ) D − w U ] x ( k ) + w ( D + w L ) − 1 b = B x + f x^{(k+1)} = x^{(k)} + D^{-1}[b-Lx^{(k+1)} - (D+U)x^{(k)}] \\ x^{(k+1)} = x^{(k)} + wD^{-1}[b-Lx^{(k+1)} - (D+U)x^{(k)}] \\ x^{(k+1)} = (D+wL)^{-1}[(1-w)D-wU]x^{(k)} + w(D+wL)^{-1}b = Bx+f x(k+1)=x(k)+D−1[b−Lx(k+1)−(D+U)x(k)]x(k+1)=x(k)+wD−1[b−Lx(k+1)−(D+U)x(k)]x(k+1)=(D+wL)−1[(1−w)D−wU]x(k)+w(D+wL)−1b=Bx+f
-
定理
- SOR法收敛 ⇒ 0 ≤ w ≤ 2 \Rightarrow 0\leq w\leq 2 ⇒0≤w≤2
- A正定对称且 0 ≤ w ≤ 2 ⇒ 0\leq w\leq 2 \Rightarrow 0≤w≤2⇒ SOR法收敛
-
误差估计
- 事后 ∣ ∣ x ( k ) − x ∗ ∣ ∣ ≤ ∣ ∣ B ∣ ∣ 1 − ∣ ∣ B ∣ ∣ ∣ ∣ x ( k ) − x ( k − 1 ) ∣ ∣ ||x^{(k)}-x^*|| \leq \frac{||B||}{1-||B||}||x^{(k)}-x^{(k-1)}|| ∣∣x(k)−x∗∣∣≤1−∣∣B∣∣∣∣B∣∣∣∣x(k)−x(k−1)∣∣, (给出上界)
- 舍入 ∣ ∣ δ k + 1 ∣ ∣ ≤ ∣ ∣ B ∣ ∣ ⋅ ∣ ∣ δ k ∣ ∣ + 1 2 × 1 0 − m ||\delta_{k+1}|| \leq ||B||\cdot ||\delta_k|| + \frac{1}{2}\times 10^{-m} ∣∣δk+1∣∣≤∣∣B∣∣⋅∣∣δk∣∣+21×10−m
第八章
特征值求取
-
引理
B y = λ y , B = P − 1 A P , A ( P y ) = λ ( P y ) By=\lambda y, B = P^{-1}AP, A(Py) = \lambda (Py) By=λy,B=P−1AP,A(Py)=λ(Py) -
幂法
v 0 = α 1 x 1 + . . . + α k x k v k = A v k − 1 = α 1 λ 1 x 1 + . . . + α k λ k x k λ m a x = l i m k → ∞ v k + 1 / v k v_0 = \alpha_1 x_1 + ...+\alpha_kx_k \\ v_k = Av_{k-1} = \alpha_1\lambda_1 x_1 + ...+\alpha_k\lambda_k x_k \\ \lambda_{max} = lim_{k\rightarrow\infty}v_{k+1} / v_k v0=α1x1+...+αkxkvk=Avk−1=α1λ1x1+...+αkλkxkλmax=limk→∞vk+1/vk -
反幂法
A − 1 的 特 征 值 λ m i n A^{-1}的特征值 \lambda_min A−1的特征值λmin -
QR法
{ A 1 = A A k = Q R A k + 1 = Q T A k Q l i m k → ∞ a i i ( k ) = λ i , ∣ λ 1 ∣ ≥ ∣ λ 2 ∣ . . . \begin{cases} A_1 = A \\ A_k = QR \\ A_{k+1} = Q^TA_kQ \\ \end{cases} \\ lim_{k\rightarrow\infty} a_{ii}^{(k)} = \lambda_i, |\lambda_1|\ge|\lambda_2|... ⎩⎪⎨⎪⎧A1=AAk=QRAk+1=QTAkQlimk→∞aii(k)=λi,∣λ1∣≥∣λ2∣...

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









