







 FacebookAI团队提出的新方法BarlowTwins,不需正负样本,通过减小同一图像不同增强版本的特征相似度来学习。目标是使特征的互相关矩阵接近单位阵,防止特征坍塌。实验表明,该方法在小batchsize下也能有效,且数据增强对性能提升显著。线性评估和消融实验揭示了损失函数各部分的重要性。
FacebookAI团队提出的新方法BarlowTwins,不需正负样本,通过减小同一图像不同增强版本的特征相似度来学习。目标是使特征的互相关矩阵接近单位阵,防止特征坍塌。实验表明,该方法在小batchsize下也能有效,且数据增强对性能提升显著。线性评估和消融实验揭示了损失函数各部分的重要性。
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
Introduction
本文是由Facebook AI团队做的自监督学习的工作,作者包含Yann LeCun和Ishan Misra等大佬,论文地址如下:原文地址。
该方法不需要区分正负样本,输入的数据为图像经过变换之后得到的不同增广数据
A
A
A和
B
B
B,作者认为网络对
A
A
A和
B
B
B提取得到的特征
Z
A
Z^A
ZA和
Z
B
Z^B
ZB应该是尽可能相似的。文章提出了一种降低冗余度的损失函数,具体来说就是求
Z
A
Z^A
ZA和
Z
B
Z^B
ZB的互相关矩阵,学习的目标是使互相关矩阵为单位阵。
方法的总体结构如下:
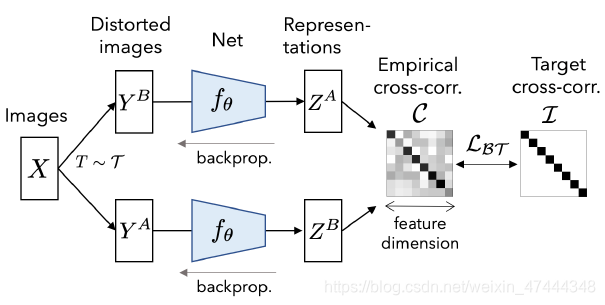
Method
BARLOW TWINS方法描述
首先输入的数据为
X
X
X,是一个batch sample,经过数据增广变换,得到两组数据分别为
Y
A
Y^A
YA和
Y
B
Y^B
YB,经过网络提取特征为
Z
A
Z^A
ZA和
Z
B
Z^B
ZB。对于一个batch来说,网络的损失函数为:
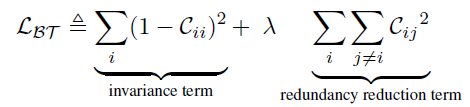
其中,
C
C
C为互相关矩阵,可以用下面的方式计算:
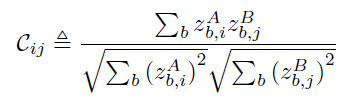
这里,
b
b
b代表的是不同的batch sample,也就是说计算
C
C
C中的每个元素是从batch的维度计算的。
个人理解,这里从batch维度计算是很重要的,但是好像实验部分没有尝试从别的维度计算,因此无从得到这个的影响大小。我的理解是从batch的维度可以保证每次的输出都有变化,不至于出现特征坍塌的现象。
执行细节
首先文中给出进行的数据变换为随机裁剪,resize到(224,224),水平翻转,颜色变换,转化为灰度图,高斯模糊等,之后前两个是每一个变换都要做的,后面的变换随机做。
使用的backbone为ResNet50,后面跟着一个三层的MLP,隐神经元个数为8192。前两层后面会跟着批量归一化和ReLu。
使用LARS优化器训练100个epoch,在ImageNet训练集上训练,batchsize为2048,不过作者也同时强调了batch size为256的时候该方法同样可以取得不错的效果。
Results
目前自监督表示学习的效果已经到了瓶颈了,该方法在实验阶段的结果并不是非常突出,因此对于和其他方法对比的结果,就不做过多的介绍,只介绍一些典型的,具体的可以看原文。本部分重点会介绍一些消融和分析实验,也就是看不同的部分对结果的影响,希望综合不同的论文,可以总结出自监督表示学习未来的发展方向以及一些实用的技巧。
Linear Evalution
以下是该方法在ImageNet验证集上应用于线性分类的结果,不是最好的结果。
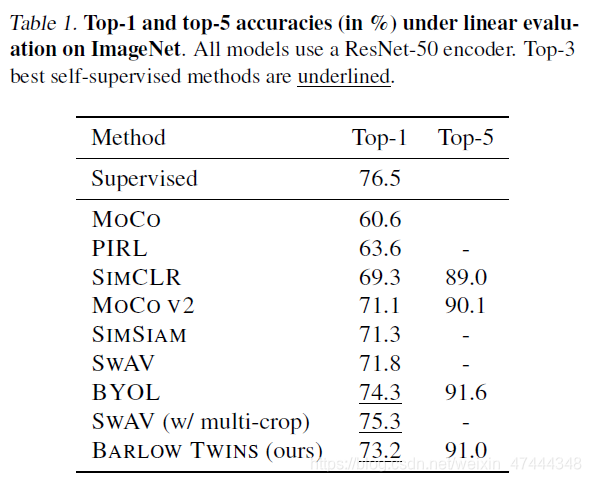
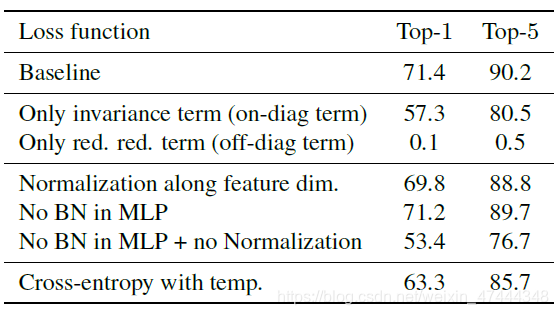
消融实验
以下是消融实验的结果。第一行为baseline,第二行和第三行为在损失函数中只保存限制对角线元素和非对角线元素的部分,可以看出,只使用对角线元素还可以取得一定的效果,但是只使用非对角线元素结果直接崩溃。另外,从第三部分中可以看出,normalize的方法不是很重要,但是必须得有,不然结果会大幅下降,但是MLP中的BN可以不要。
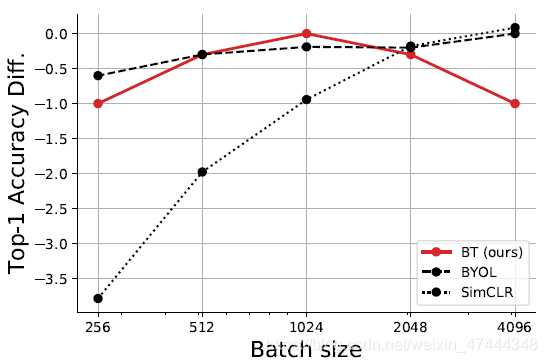
Batch size的作用
下图显示了该方法在不同batchsize下的效果,可以看出,该方法不需要很大的batch size也可以取得不错的效果,但是随着batchsize的增加,效果反而会下降,这个的影响主要来源于求
C
C
C的时候,batch size越大,一次抽出来的特征维度就越大。
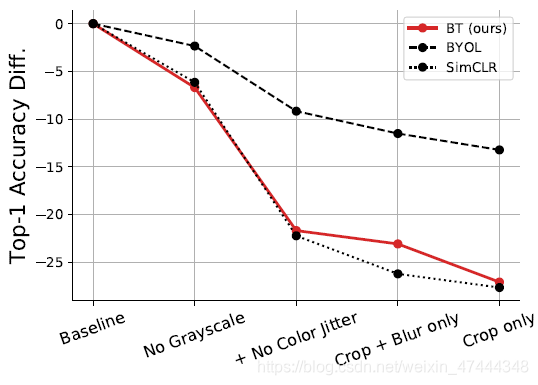
移除一些数据增广操作
下图展示了移除一些数据增广操作的影响。说明增加数据增广是非常有必要的,能加就多加。

















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









