







Unsupervised Deep Embedding for Clustering Analysis
Introduction
该论文也是一篇介绍无监督聚类的方法,采用的思路和上一篇博客类似,论文发表在ICML2016上:论文地址。
作者首先通过深度编码解码网络对数据进行降维,之后利用软分配确定样本点属于某个簇的分布,计算其与辅助目标分布的KL散度,得到聚类的效果。
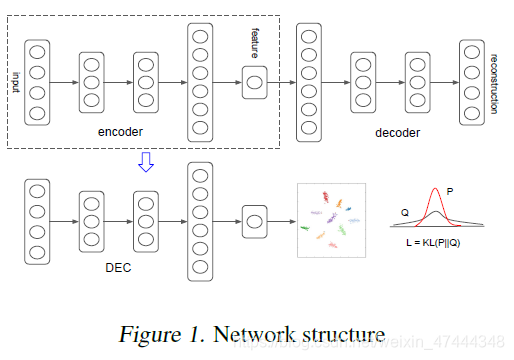
Method
SOFT ASSIGNMENT
对于每一个样本点的隐向量
z
i
z_i
zi,我们其与每一个预定义簇
μ
j
\mu_j
μjd的相似度,在这里作者是采用了软指定的做法,将相似度看作是一个概率分布,而不是固定的。作者使用了t-分布计算
z
i
z_i
zi和
u
j
u_j
uj的相似度:
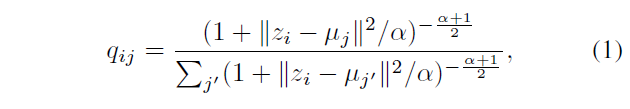
α
\alpha
α设置为1。
KL DIVERGENCE MINIMIZATION
作者在这里计算
q
i
j
q_{ij}
qij与辅助目标分布的KL散度,实现迭代聚类。目标分布应该满足以下的条件:1)有更好的预测结果;2)将数据点按照高可信度分配;3)规范每个质心的损失贡献。以上是原文中作者给出的解释,实际上我读完之后也不是很理解,不过从任务的目标来看,作者无非是希望随着网络的训练,一个簇中的样本点可以尽可能聚集在质心周围,所以可以采用最简单的delta distribution,计算起来也简单。但是作者可能是觉得这个太简单,因此提出了下面这种目标分布,效果我认为是类似的。辅助的目标分布定义为下面的形式:
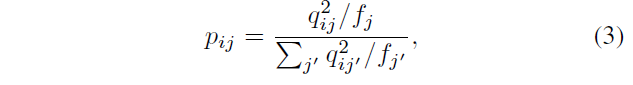
其中,
f
j
=
∑
i
q
i
j
f_j=\sum_i q_{ij}
fj=∑iqij。
Experiments
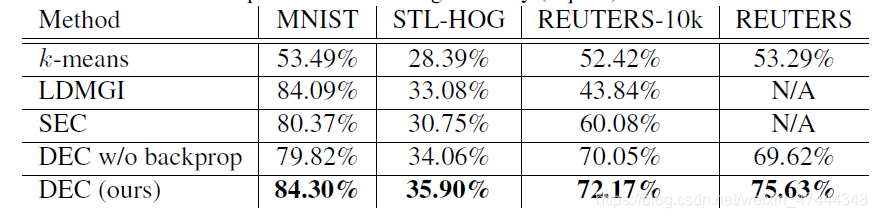
作者分析了该方法在三个数据集上的效果:
Conclusion
这篇文章采用了一个相对比较简单的框架,实现了无监督的聚类方法,取得了不错的结果。但是感觉论文写得比较随意,有一些地方没有写明白,尤其是实验部分,感觉很乱…。另外,该方法的计算过程决定了,必须积攒了足够多的样本才可以计算题反传,无法像批量梯度下降那样更新参数。

















 1107
1107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









