






前言
以下均是个人理解,不足之处欢迎指正。引用一些大佬的话
Instant-ngp
positional encoding原理: 在位置上临近而像素值却差异很大的两个点,在MLP计算loss时,为保证min{loss},会使得MLP选择一个折中的方案,这就导致最终的结果变得模糊。加入位置编码后,会使得两个原本位置上很近的点变得很远,从而保留了高频特征。
两个参数: 最大分辨率Nmax,hash表的大小T
哈希冲突: 当两个位置差距很大的点映射到hash表的同一个位置上。(距离很小的话,不属于hash冲突)
虽然总参数量变多,但每次更新的参数变少(只需要更新立方体的8个顶点)
方法流程: 以2D为例,现有一个坐标x(a,b),先将其映射到体素网格中,该网格有L=2种分辨率,在L1分辨率下获得4个角点的索引,L2同理,使用角点索引映射到hash网格中获得对应的F维特征向量,对特征向量进行插值获得特征值,并将所有分辨率下的特征值concatenate到一起并加上一个方向向量,作为最终的编码,也是MLP的输入。
以上,我们就构建了一个由 Hash Table 主导的 Mapping,通过这种方式用一个 Hash Table 就能建立一个 Mapping,那如果我们有m个独立的 Hash Table,自然就有m个这样的 Mapping,那就可以理解为实现了一个有3到m的投影。不同于positional encoding,hash表中的内容可以进行反向传播,使得其可优化。
我们就理清了 Hash Encoding 的实际操作,可以看到 Hash Encoding 想要解决的最直观的问题就是怎么利用更少的显存实现高分辨率的特征存储。而结合 MLP 以及梯度下降,Hash Encoding 可以自适应地关注有效区域,避免哈希冲突带来的负面影响。
代码层面: 对于一个点[x,y,z],先计算其在网格中的8个顶点的坐标(分辨率和bounding_box范围已经预定义过了),此时的张量维度是[Batch_size,8,3],通过以下公式建立每个网格顶点坐标到 Hash Table 的索引,从而将网格顶点坐标映射到hash表中。
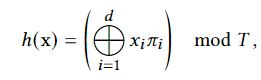
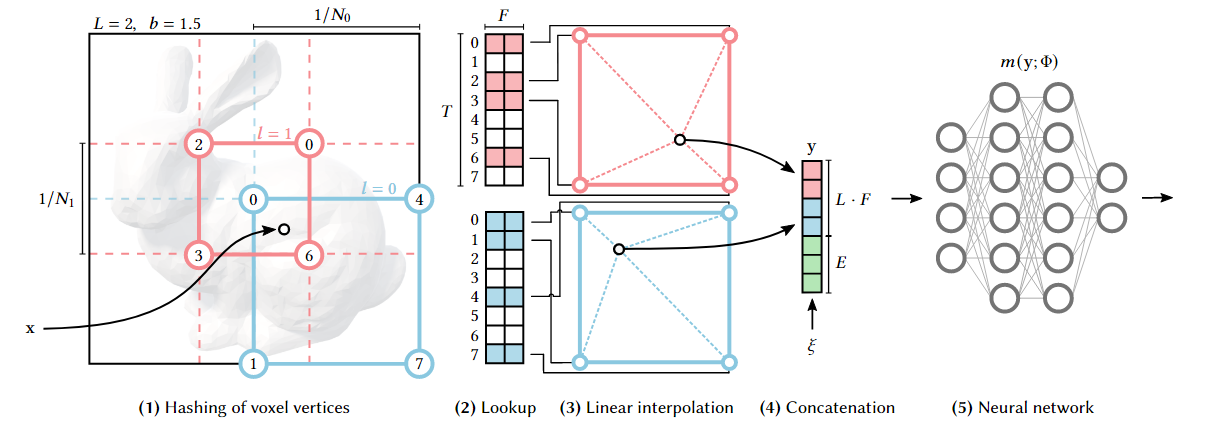
一些理解:(引用大佬的话)
- 空间利用率: 若使用dense grid势必会造成空间上的浪费,但由于哈希冲突的存在,空白区域有概率被挤掉,一定程度上缓解了空间浪费。
- 如何保持高频: 哪部分对应了NeRF中的positional encoding?首先明确positional encoding的作用:为了保证距离相近的两个点对应的特征编码尽量不同,这样不同的特征输入到MLP当中,才能优化出高频的信息,而高分辨率的特征网格编码可以对应这一点,只要两个点处于不同的网格格点上,那么这两个点就是独立优化的,不存在距离很近被放在一起优化的问题。 还是有疑惑,无论是不是独立优化,至少输入MLP的值距离依然很近,如果很近就无法保证高频。

总结: 文章的contribution有两个——hash encoding和Multi-Resolution,哈希编码的哈希冲突问题有利有弊,弊端可以用MLP的反向传播进行优化,使得表里存储的内容更关注于物体表面,而多分辨率中的高分辨率则保证了最终优化结果的高频信息。
DVGO
BARF
项目链接
总结: 当输入的位姿不准确时,也可以通过错误的位姿获得正确的建图。
贡献:
1.对位姿进行优化(这里参考了图像配准)
2.添加mask以保证高维位置编码不会对配准产生影响
展开来讲:
针对第一点——作者提出了一个新的loss函数,可以对MLP中的参数
θ
\theta
θ和位姿
p
p
p都进行优化。

针对第二点——作者发现对位置编码求导后会出现很大的常数项(公式12),使得信号不平滑,这对配准不利。因此,作者添加了mask函数,其中
α
\alpha
α随着训练次数的增大而增大,使得前期平滑信号学习图像配准,后期高频信号学习场景表示。


Mip-NeRF-pytorch代码记录
采样 → 位置编码
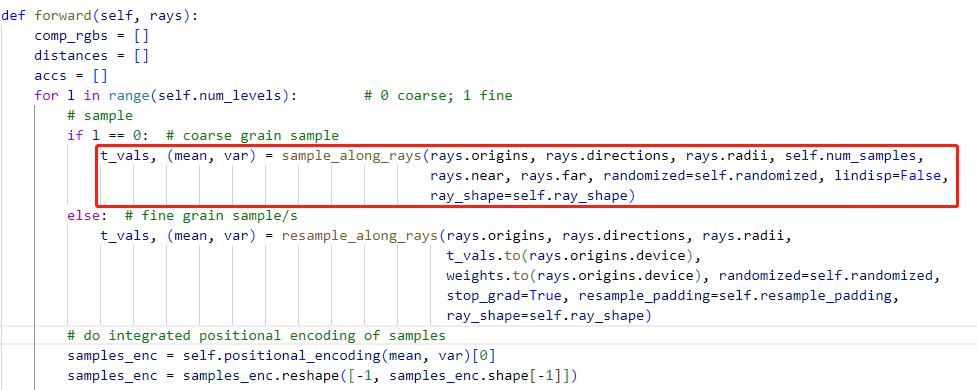
Seathru-NeRF
方法
基于散射场景,提出一个新的渲染模型,并在合成和真实数据集上进行验证,方法做到了以下几点:
1.颜色复原
2.3D场景结构估计(超越了SFM和原始NeRF)尤其是在远处
3.参数估计
方法改进了nerf的渲染公式,在渲染过程中除了物体光以外,还增加了介质的光
实验
合成数据集合成了 fog和水下两种场景(都包含散射介质),水下场景额外考虑了光线的吸收(给出Sea-thru模型参数进行合成)。

















 1146
1146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









