



前言
困难重重,但好在国内已经存在开源网站了,在各种资料的帮助下终于。主要参考https://zhuanlan.zhihu.com/p/30627923321和https://zhuanlan.zhihu.com/p/663712983
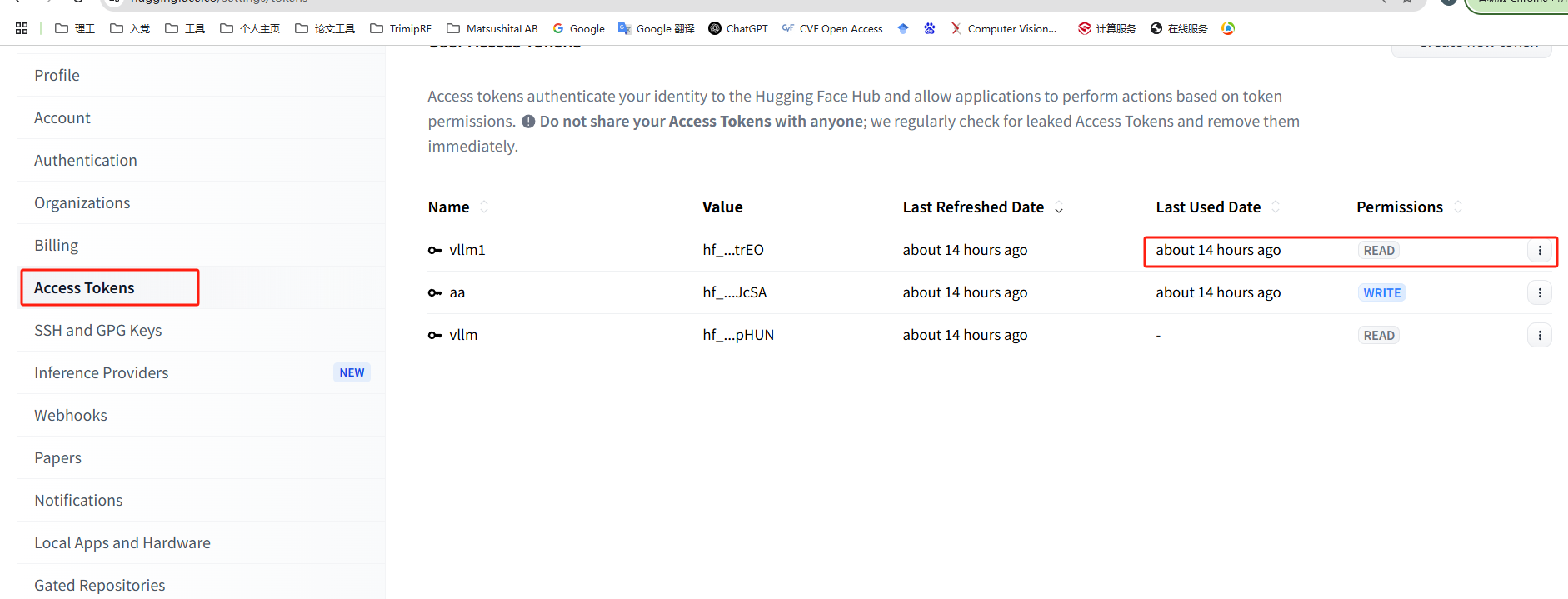
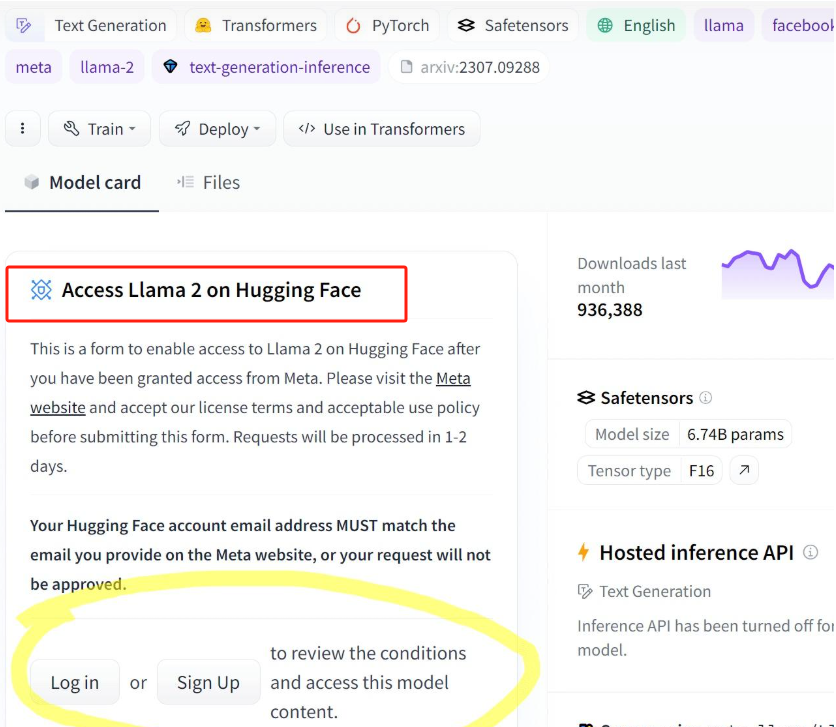
提醒: token自己去Huggingface注册账号申请,一次性token。进入https://huggingface.co/google/gemma-3-12b-it的网站后,需要同意一些东西才能成功下载(位置大概在左上角很大一个区域)。
# 配置gemma3
conda create -n gemma3 python=3.12
# 激活gemma3环境
conda activate gemma3
#使用阿里云pip源来加速下载
pip install --upgrade pip -i https://mirrors.aliyun.com/pypi/simple/
git clone https://github.com/vllm-project/vllm.git
cd vllm
VLLM_USE_PRECOMPILED=1 pip install --editable . -i https://mirrors.aliyun.com/pypi/simple/
# 测试
pip show vllm
# 配置transformers
pip install git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3
# 网络配置
export HF_ENDPOINT="https://hf-mirror.com"
# 模型下载
huggingface-cli download --resume-download google/gemma-3-12b-it --local-dir gemma --token hf_your_token
这里--tensor-parallel-size要能被16整除,-gpu-memory-utilization不要太大,不然会OOM.另外,
# 运行服务
export CUDA_VISIBLE_DEVICES=0,1
# 需要在vllm那一级的目录下运行
# (gemma3) [yangtongyv@gpu2 code1]$ ....
vllm serve gemma --tensor-parallel-size 2 --max-model-len 16384 --port 8102 --trust-remote-code --served-model-name gemma3-12b --enable-chunked-prefill --max-num-batched-tokens 2048 --gpu-memory-utilization 0.8 --max-num-seqs 16
vllm serve gemma3-27 --tensor-parallel-size 4 --max-model-len 16384 --port 8102 --trust-remote-code --served-model-name gemma3-27b --enable-chunked-prefill --max-num-batched-tokens 2048 --gpu-memory-utilization 0.8 --max-num-seqs 16
开始测试
import requests
url = "http://localhost:8102/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"model": "gemma3-12b", # 注意:这个名字要和你 serve 时的 --served-model-name 一致
"messages": [
{"role": "user", "content": "写个100字的散文"}
]
}
response = requests.post(url, headers=headers, json=data)
# 输出结果
print("Response:", response.json())


















 991
991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









