







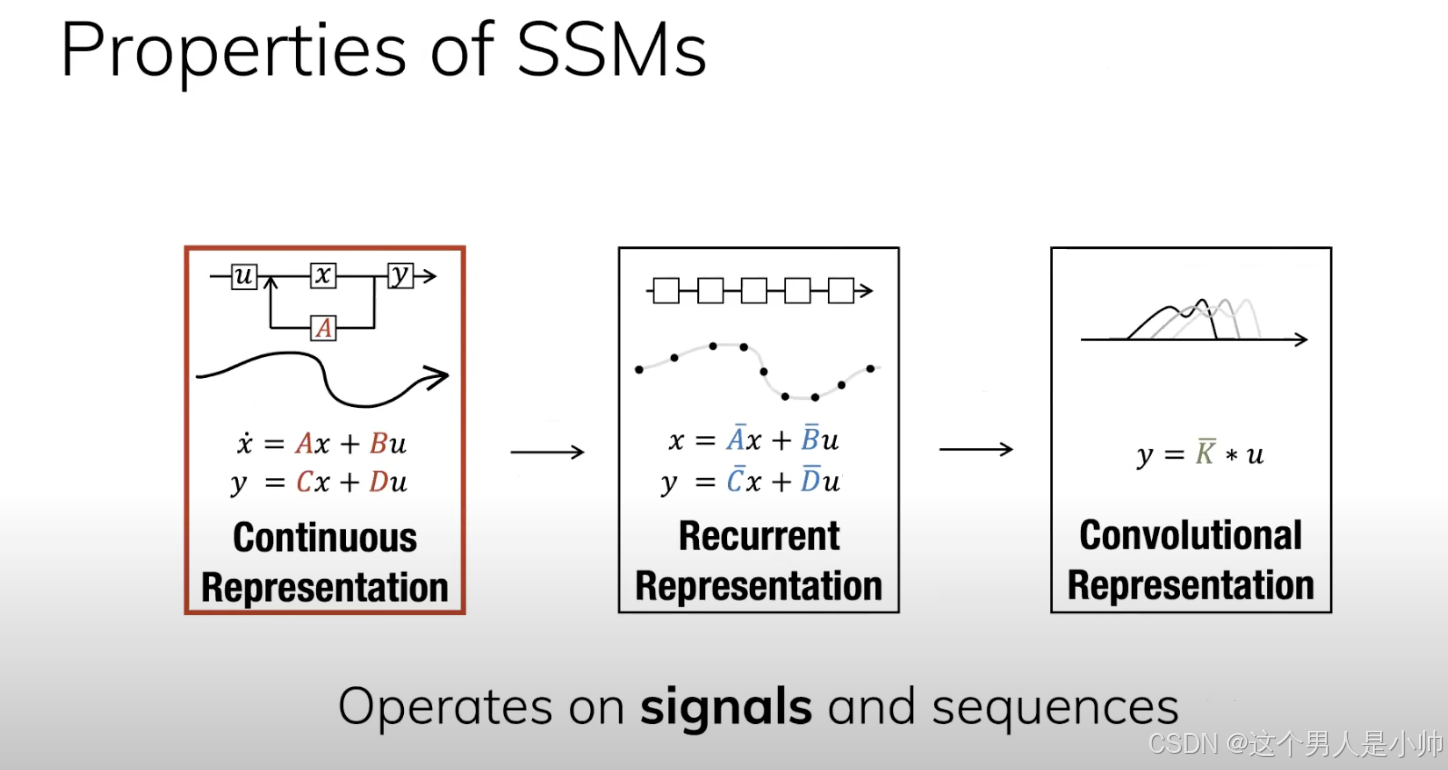
0.引言
在上一章节中实际上讨论了Mamba的核心基础SSM模型, 本章节重点讲解的是对SSM模型的离散化处理以及SSM的并行化操作。学习这些枯燥的理论知识都是为了我们最终的去领略Mamba全部风景的楼梯,所以如果你真的想去一睹Mamba这座大山的雄伟先从这里开始吧。
实际上这 Mamba 也是为了干掉 Transformer 如果你不理解这样的背景可以先看去看我的其他博文,给自己打个广告,如果您对 Transformer 还不太了解,欢迎访问我的博客专栏,其中包含了丰富的NLP入门内容。即使您不是NLP领域的学者,这些内容对您深入理解深度学习和神经网络也大有裨益。点击这里学习更多。
此外,如果您对图神经网络的了解还不够深入,我建议您先阅读相关基础知识。点击此处,都是我的个人理解,简单易懂。话不多说,那咱们就开始今天的学习吧。
1. 增强SSM理解
上一章节中对RNN和SSM的理解进行了一个强的定义。简单粗暴即 RNN 的参数矩阵
W
,
U
,
V
W,U,V
W,U,V 是可学习的,而SSM的
A
,
B
,
C
A,B,C
A,B,C 是固定的这就是两者最大的区别。但是有一些细节我们还是要继续了解下,RNN参数矩阵
W
,
U
,
V
W,U,V
W,U,V 的形状还是和
A
,
B
,
C
A,B,C
A,B,C 是不一样的,一方面是其思想不一样,同样也是这样的思想造就了SSM可并行化的能力。这个我们后面再说。
W
,
U
,
V
W,U,V
W,U,V 的形状在我们的NLP入门中讨论过,仅仅是正常的全连接层可以定义的。但是SSM
A
,
B
,
C
A,B,C
A,B,C 是不一样的。我们看下图:
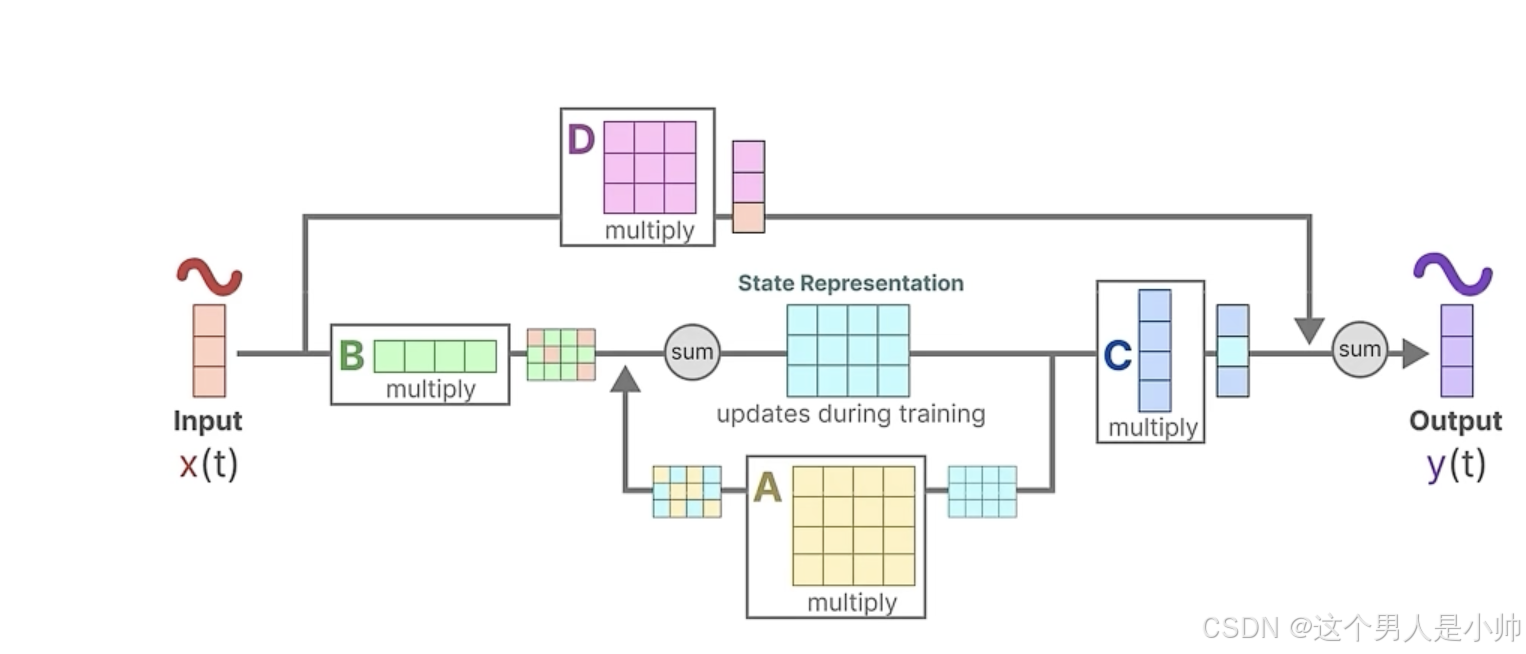
可以看到
B
,
C
B,C
B,C 是向量而
A
A
A 是矩阵。注意这里的
B
,
C
B,C
B,C 的维度是由多种信息决定的。放在后面讨论。
在传统的控制系统领域中是SSM 通常被用于描述和分析动态系统的行为。这些模型中的参数(A - 状态转移矩阵,B - 控制输入矩阵,C - 输出矩阵)往往是根据狭义系统动态学、物理定律或通过系统辨识技术得到的:
- 系统动态学和物理定律:这些通常基于对系统的理解和实际物理行为的数学建模,例如,在机械系统中,可以根据牛顿力学来设定这些矩阵。
- 系统辨识:在一些复杂或未能完全了解内部机理的系统中,工程师可能会通过实验数据采用参数估计或系统辨识方法来识别这些矩阵。
说人话就是通过先验知识进行定义的,即 上一节中讨论的SSM A , B , C A,B,C A,B,C 矩阵是提前固定好的不可学习的。
2. 离散化SSM
为了将SSM引入到深度学习领域我们需要将SSM进行离散化处理。
因为计算机和数字系统通常只能处理离散的数据点。
离散化状态空间模型(Discrete State Space Model,简称离散化SSM)是将原本在连续时间下描述的系统行为转化为在离散时间点上的描述。离散化的过程对于计算机模拟、数字信号处理、以及实际操作中的数据采样都是至关重要的。
就是要让计算机更好的去处理,所以我们要对设计的模型进行离散化操作
还有部分原因如下了解即可:
- 数据存储与分析:在现实世界中,许多数据采集系统是基于离散时间间隔进行数据记录的,因此数据本身就是离散化的。
- 实际应用的需要:在进行系统设计和分析时,使用离散模型可以更直接地应对实际工程问题,如控制系统设计、经济模型预测等。
- 稳定性与实用性:离散模型通常更容易实现计算和控制,并且可以使用广泛的数字工具和软件进行分析和设计。
如何实现模型离散化??
这个技术被称为零阶保持,行为如下:
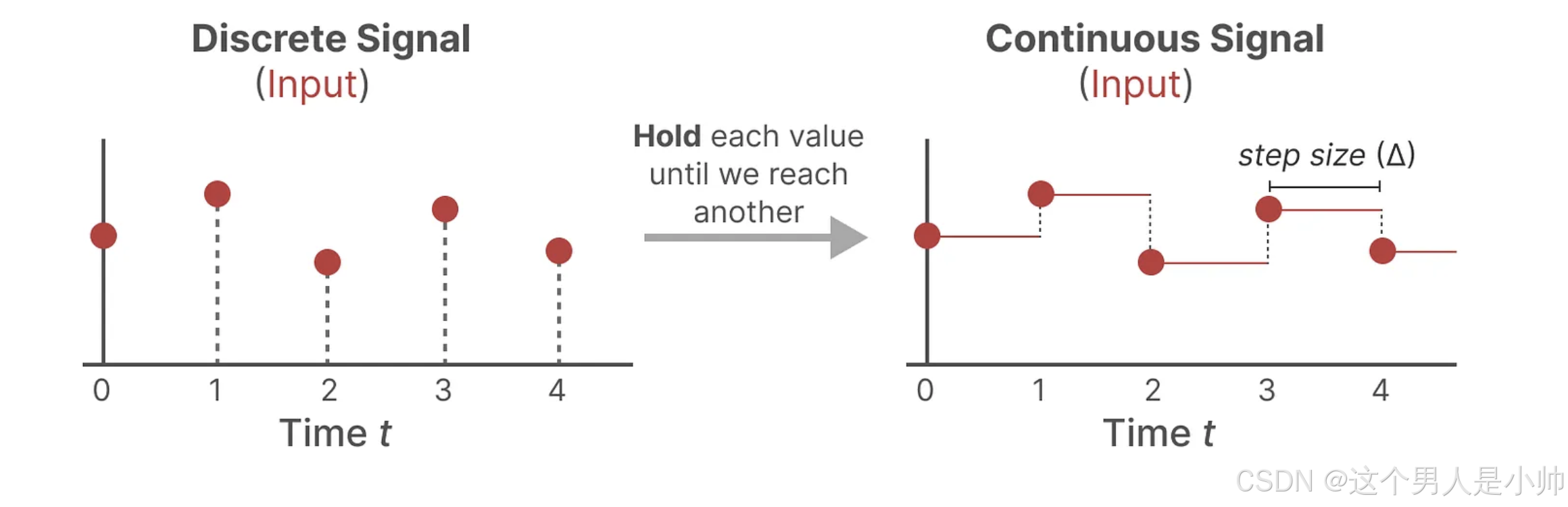
首先输入离散信号时,通常采取的做法是将每个离散信号的值保持不变,直到接收到下一个离散信号为止。这种方法有效地将离散信号转换为适用于状态空间模型(SSM)的连续信号。这个过程中,保持信号值不变的时间长度是由一个新的可调参数决定的,我们称之为步长 Δ \Delta Δ(size)。 步长代表了输入信号保持的分辨率或周期性。简而言之就是一个离散的信号在时间上重复输入直至下一个时间段的新的离散信息输入为止 现阶段还是为了将离散信号连续化,
一旦拥有了这种形式的连续输入信号,我们便能根据输入的步长生成连续的输出信号,并且可以按照设定的时间步长对这些连续输出值进行采样。这使得模型能够更精确地反映输入信号的变化,从而提高对系统行为的预测和控制效果。我们可以通过这样的方式对连续和离散反复的转换。这一步长。
他是如何对模型进行修改的呢??
首先来看下我们上一章节研究的这个两个公式:
h
′
(
t
)
=
A
h
(
t
)
+
B
x
(
t
)
(
1
a
)
h'(t) = Ah(t) + Bx(t) (1a)
h′(t)=Ah(t)+Bx(t)(1a)
y
(
t
)
=
C
h
(
t
)
(
1
b
)
y(t) = Ch(t)(1b)
y(t)=Ch(t)(1b)
在上一节中讨论过 1 b 1b 1b 公式是即这个观测方程实际上是很少用到的 D D D 的,所以我们先忽略掉这 D D D 仅仅考虑 A , B A,B A,B
其实很简单,仅仅需要使用 Δ \Delta Δ(size) 函数进行处理即可得到这样的形式:
h
(
t
)
=
A
‾
h
(
t
)
+
B
‾
x
(
t
)
(
2
a
)
h(t) = \overline{A}h(t) + \overline{B}x(t) (2a)
h(t)=Ah(t)+Bx(t)(2a)
y
(
t
)
=
C
h
(
t
)
(
2
b
)
y(t) = Ch(t)(2b)
y(t)=Ch(t)(2b)
这里的离散化操作仅仅是为了方便计算机的处理,具体是如何计算得到的来自于下面的这个公式:
A
‾
=
e
x
p
(
Δ
A
)
B
‾
=
(
Δ
A
)
−
1
(
e
x
p
(
Δ
A
)
−
I
)
Δ
B
\overline{A} = exp({\Delta}A) \ \ \ \ \ \ \ \ \ \ \overline{B} =({\Delta}A )^{-1}( exp({\Delta}A) -I) {\Delta}B
A=exp(ΔA) B=(ΔA)−1(exp(ΔA)−I)ΔB
当然作为一种技术这个公式不需要记,大家只需要了解即可。这里仅仅是解释如何操作的,这样就从之前只能接受连续输入的模型变成了下面离散的形式。
我解释下下图,下图展示的这个

就是一个连续的输入,简单的理解就是
x
(
t
)
x(t)
x(t),只不过输入是连续的形式。而连续型的SSM则是要进行状态的更新,并且输出一个连续数据作为输出。

同样的一个离散的数值,就是一个离散的输入,作为
x
(
t
)
x(t)
x(t),只不过输入是离散的形式。通过离散型的SSM则是要进行状态的更新,并且输出一个离散数据作为输出。
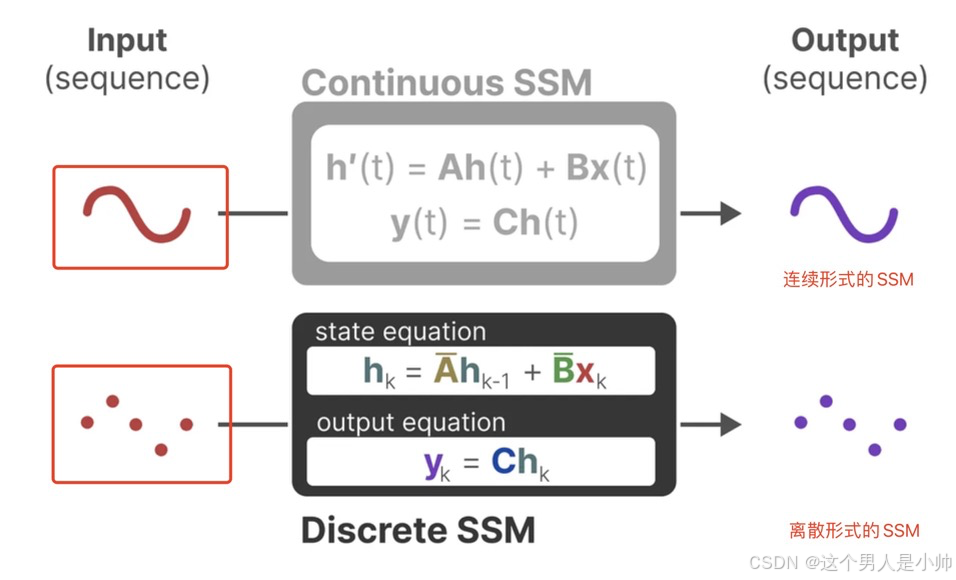
完成了模型的离散化处理,这里介绍的很细致主要是因为确实有些地方容易出现思维上的不连贯,所以我尽量不忽视掉任何一个细节,但是这个离散化过程需要点控制理论的基础,我作为程序猿还是理解有限,当然如果你是好学的话可以去看看那这个ZOH技术。
现阶段我们已经完成了对SSM模型的离散化可在计算机领域使用,这个传统的控制系统的连续SSM有什么不同呢??
最大的不同就是在离散的SSM是给深度学习技术使用的,即SSM的 A , B , C A,B,C A,B,C 即可训练的,是通过数据驱动的方式学习得到的:
- 梯度反向传播:这是训练神经网络的标准方法,用于优化网络参数以最小化损失函数。在此过程中,网络通过从大量数据中学习来自动调整其参数(权重和偏置),这些参数在本质上充当了 SSM 中的 A、B、C 矩阵的角色。
- 数据驱动的学习:与控制系统中基于物理定律或先验知识的方法不同,深度学习侧重于从数据中自动发现模式和关系。这使得深度学习模型能够适用于更广泛的应用场景,尤其是那些难以用传统物理方法建模的领域。
所以我们后续讨论的SSM参数都是随机初始化并且可训练的。
所以我们后续讨论的SSM参数都是随机初始化并且可训练的。
所以我们后续讨论的SSM参数都是随机初始化并且可训练的。
稍微总结下,连续SSM与离散SSM的基本区别
- 时间模型的变化:
- 连续SSM:通常使用差分方程以表示系统状态的连续变化,这种模型主要用于对物理系统的模拟,其中时间被看作是连续变量。
- 离散SSM:在处理实际数据或进行数字计算时,连续模型通常需要转换为离散模型。离散SSM使用差分方程的离散形式,适应于计算机操作和数字信号处理,时间步被视为离散的点。
参数的可训练性与数据驱动
-
传统控制系统中的SSM参数 (A, B, C):
- 这些参数在模型构建阶段通常是固定的,基于物理洞察、系统理论或经验设计。这种方法在参数确定后,很少根据新数据进行调整,除非进行系统重新设计或优化。
-
深度学习中的离散SSM参数 (A, B, C):
- 在深度学习应用中,这些参数是可训练的,意味着它们是通过机器学习技术从数据中学习得到的。这种方法利用大量数据来自动识别最优的系统模型,适应数据中隐含的复杂模式和非线性关系。
应用领域与技术适应性
-
传统SSM:
- 通常用于工程和物理系统中,如航空控制、机械动态系统等,强调模型的物理准确性和可解释性。
-
离散化与可训练的SSM:
- 适用于需要从大量复杂数据中提取信息的场景,如金融预测、语音识别、复杂系统行为预测等。这些领域的数据通常包含高度的动态变化和非线性效应,传统模型难以准确捕捉。
所以我们后续讨论的SSM参数都是随机初始化并且可训练的。
所以我们后续讨论的SSM参数都是随机初始化并且可训练的。
所以我们后续讨论的SSM参数都是随机初始化并且可训练的。
3. SSM的并行化处理
其实看到这里的同学可能最大的疑惑为什么是这玩意和RNN差不多啊?你参数可训练,模型也有着状态的思想为什么你能并行化呢??
我们慢慢来解释这个问题
在学习RNN得过程中我们知道RNN的训练是十分费力的这是因为其结构导致训练起来收敛比较慢,最大的问题就是其无法实现模型的并行化训练。
RNN 由于其循环依赖的特性,计算当前状态需要等待前一个状态的计算完成,因此传统的 RNN 很难进行真正的并行计算。Teacher Forcing 虽然改变了训练过程中的输入方式,但并没有改变这种序列依赖的本质,因此它本身并不提供并行化的能力。 啰哩啰嗦说了一大堆就是RNN不能并行化。
但是SSM可以 SSM最大的能力就是实现了计算上的并行化。那么是如何实现并行化的呢??要说并行化的概念主要还是给CNN加速,所以我们先看CNN是怎么做到并行化,再去理解什么样的形式卷积才能进行并行。
CNN的并行化主要是卷积层操作的能力,这是CNN中的核心,它通过 卷积核(或滤波器) 在输入数据(如图像)上进行滑动窗口操作,计算窗口内数据和卷积核的点积。由于每个窗口的操作相互独立,这使得卷积操作非常适合并行处理:
- 空间并行性:可以同时计算多个窗口的卷积操作。例如 ,在处理图像的不同区域时,可以将图像分割成多个部分,每部分在不同的处理器上并行处理。 各位好好理解下
SSM实际上就是在这方面实现的并行化能力 - 滤波器并行性:当使用多个滤波器生成多个特征图时,每个滤波器的操作也可以并行执行。这里主要讨论的是多个卷积核并行
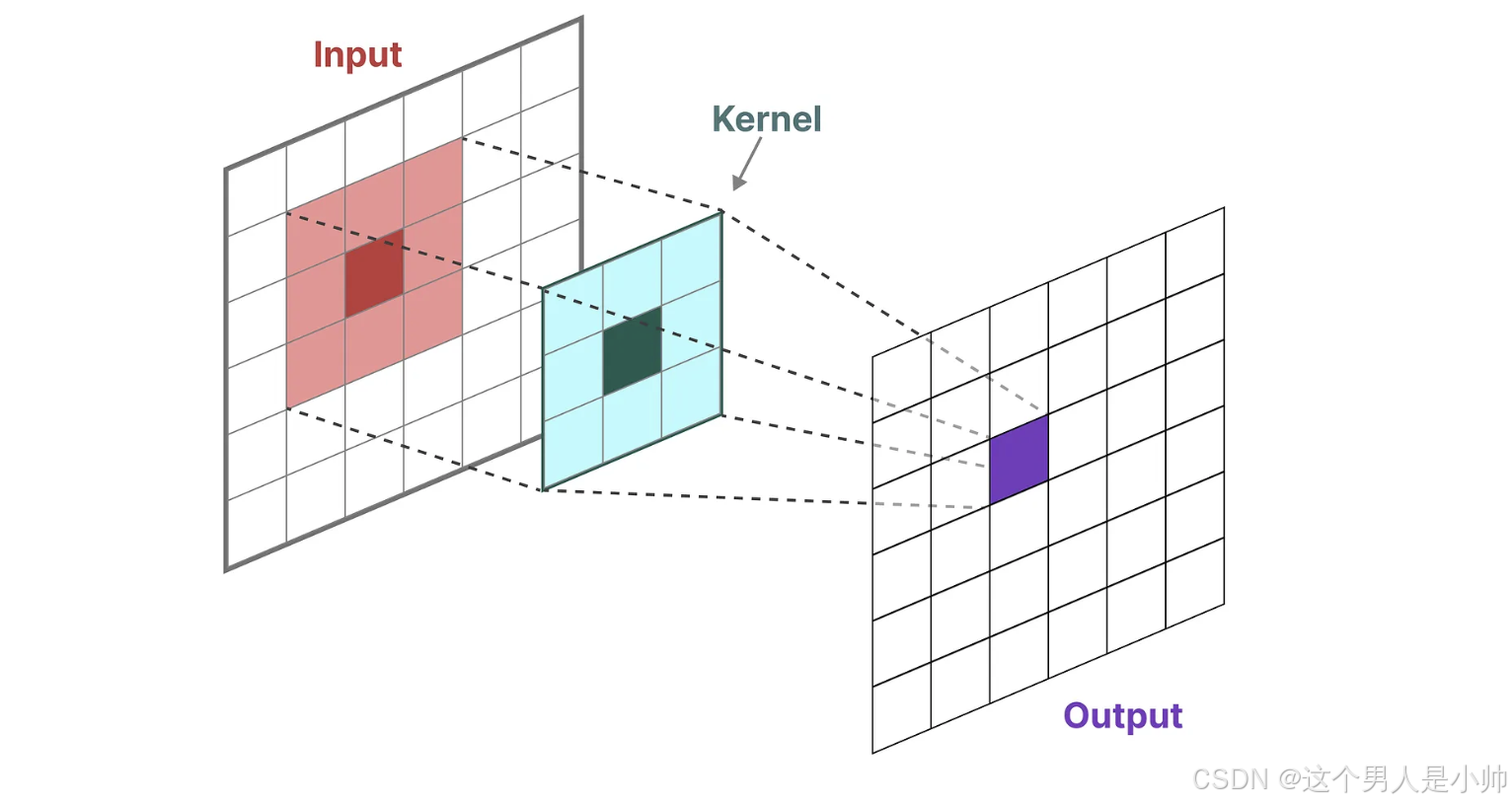
听起来是不是很抽象。我这里解释下:
首先这是卷积行为, 在卷积神经网络(CNN)中,使用卷积核或过滤器对数据进行特征提取是一种基本的操作。以3x3的卷积核为例,它可以看作是一个小的窗口,滑动遍历整个图像或矩阵数据。在每个位置,这个卷积核都会覆盖数据的一个局部区域,并通过该区域内对应位置的数值与卷积核上的权重系数相乘,然后将所有乘积求和得到一个单一的数值。这个过程就是所谓的卷积操作。

在时间变换的视角下动图是这样的:

随着时间的变换卷积核缓慢的移动,得到全部的输出就是一个矩阵,而矩阵中的每个数值都是依赖于卷积核和卷积核大小的输入共同计算的结果。我们如果在时间维度上 展开思考这个行为。就是时间的不同,输入值数值也不同,使用相同的卷积核,我们将输入图分解成多个,作为输入,然后复制和输入数量一样的卷积核,同时进行这个行为并行计算呗, 这样就不用等这卷积核移动了。直接就实现了一个时间计算全部的,最后将这个输出拼接,注意我们这里讨论的是在时间维度上展开。
我们整理下上面的思绪,让我们进一步详细解释这个过程:
时间维度的并行卷积处理
-
将输入分割: 根据时间维度,将输入图片分成多个小块作为不同时间的输入。
时间维度上的输入并行化展开 -
复制卷积核: 对每个时间点的输入使用相同的卷积核。由于每个输入都独立处理,可以复制卷积核并同时对所有输入应用卷积操作。
每一个时间输入应用一个卷积核,由于其卷积核用的都是一个可以直接复制得到每一个输入的卷积核 -
并行处理: 将卷积核应用于每个时间点的输入可以并行执行。在现代计算平台上,这可以通过多核处理器或GPU实现,极大地加速了整体的处理速度。
-
结果拼接: 将所有时间点上的卷积结果重新组合或拼接,形成最终的输出,这个输出保留了整个时间序列的处理结果。
优势
-
效率提升: 通过并行处理不同的时间点上的输入,大幅减少了处理时间。这对于实时处理应用尤其重要,例如实时视频分析或在线信号处理。
-
资源最大化利用: 利用现代计算硬件(如多核CPU和GPU)的并行计算能力,可以更有效地处理大规模数据。
-
简化时间依赖: 通常,卷积网络处理视频或时间序列数据时需要考虑时间依赖性,通过并行处理可以在一定程度上简化这些依赖,每个时间段的处理更为独立。
ok👌,我相信大家应该是理解了CNN可以并行的能力,就是将输入在时间维度上展开。每一个时间输入应用一个卷积核,由于其卷积核用的都是一个可以直接复制得到每一个输入的卷积核,最终对结果进行拼接,其卷积行为就是加权求和。现在咱们明白了CNN卷积行为就是加权求和,并行化能力就是时间维度上的展开。然后同时计算。那么离散化的SSM并行整理
我们回过头来看离散化SSM的输出过程计算整理。
状态更新方程
-
当前时刻的状态 h ( t ) h_{(t)} h(t):
h ( t ) = A ‾ h ( t − 1 ) + B ‾ x ( t ) h_{(t)}= \overline{A}h_{(t-1)} + \overline{B}x_{(t)} h(t)=Ah(t−1)+Bx(t) -
前一个时刻的状态 h ( t − 1 ) h_{(t-1)} h(t−1):
h ( t − 1 ) = A ‾ h ( t − 2 ) + B ‾ x ( t − 1 ) h_{(t-1)} = \overline Ah_{(t-2)} + \overline{B}x_{(t-1)} h(t−1)=Ah(t−2)+Bx(t−1)
将第二个方程代入第一个方程中得:
h
(
t
)
=
A
‾
(
A
‾
h
(
t
−
2
)
+
B
‾
x
(
t
−
1
)
+
B
‾
x
(
t
)
h_{(t)} = \overline{A}(\overline{A}h_{(t-2)}+ \overline{B}x_{(t-1)} + \overline{B}x_{(t)}
h(t)=A(Ah(t−2)+Bx(t−1)+Bx(t)
h
(
t
)
=
A
‾
2
h
(
t
−
2
)
+
A
‾
B
‾
x
(
t
−
1
)
+
B
‾
x
(
t
)
h_{(t)} = \overline{A}^2 h_{(t-2)} + \overline{A}\overline{B}x_{(t-1)} + \overline{B}x_{(t)}
h(t)=A2h(t−2)+ABx(t−1)+Bx(t)
进一步将这个表达式一般化:
h
(
t
)
=
∑
k
=
0
t
A
‾
k
B
‾
x
(
t
−
k
)
h_{(t)}= \sum_{k=0}^{t} \overline{A}^k \overline{B} x_{(t-k)}
h(t)=k=0∑tAkBx(t−k)
输出方程
利用状态表达式来计算输出
y
(
t
)
y_{(t)}
y(t):
y
(
t
)
=
C
h
(
t
)
=
C
(
∑
k
=
0
t
A
‾
k
B
‾
x
(
t
−
k
)
)
y_{(t)} = C h_{(t)} = C \left(\sum_{k=0}^{t} \overline{A}^k \overline{B} x_{(t-k)}\right)
y(t)=Ch(t)=C(k=0∑tAkBx(t−k))
y
(
t
)
=
∑
k
=
0
t
C
A
‾
k
B
‾
x
(
t
−
k
)
y_{(t)}= \sum_{k=0}^{t} C \overline{A}^k \overline{B} x_{(t-k)}
y(t)=k=0∑tCAkBx(t−k)
慢慢的梳理下,我们看上面的这个公式, x ( t − k ) x_{(t-k)} x(t−k)就是当前时间步的输入,前面的ABC矩阵就是各种各样的参数,就是说 y ( t ) y_{(t)} y(t) y ( t ) = ∑ k = 0 t C A ‾ k B ‾ x ( t − k ) y_{(t)}= \sum_{k=0}^{t} C \overline{A}^k \overline{B} x_{(t-k)} y(t)=k=0∑tCAkBx(t−k)
输出是对当前和所有历史输入的加权求和,权重由观测矩阵、状态转移矩阵的幂次和输入矩阵的乘积确定。
总结下重点就是当前时间步输出需要将前面全部的输出进行加权求和呗。计算当前时间步的输出就是对之前的全部输入进行加权求和。
当然这里要注意的实际上是 t − k t-k t−k可以通过 k k k 的设定确保你设计一个时间窗(卷积核的大小),考虑多久前的输入。k=0就是考虑前面全部的。很简单思考下即可。
而CNN的并行化是对输入在时间维度的展开。这个SSM很简单啊我们就是按照时间一个一个输入的所以我们仅仅排列开全部的输入就可以了。这里有一个窗口的信息,决定了每一个时间步需要输入多少输入的信息, t − k t-k t−k k k k 就是计算当前时间步需要多少个输入信息。这个都是固定循环的可以很容易的在并行前计算出来。
那卷积核怎么设计呢??CNN的卷积核只需要复制就可以了啊。注意CNN某一时间段的输入就是一个局部特征和卷积核加权求和的就计算某一个时间的输出。而卷积核用的永远都是一个,所以卷积核不需要计算 得到直接复制就行。SSM可以中我们讨论并行化其输入是很容易确定的但是权重即卷积核不好整,忘了我们之前总结的公式了嘛。 y ( t ) = ∑ k = 0 t C A ‾ k B ‾ x ( t − k ) y_{(t)}= \sum_{k=0}^{t} C \overline{A}^k \overline{B} x_{(t-k)} y(t)=k=0∑tCAkBx(t−k) 也可以通过这个公式提前计算出每个输入的权重信息,这样我们就能实现输入和权重的预处理,并行计算全部时段的输出了。
举个例子1,2,3,4,5.这就是SSM的输入。第一个卷积核卷积就是一个权重的特征是1,第二个就是两个权重特征是12第三个就是123.这些都是可以按照规律提前设定好的了即通过预先计算所有可能的 A ‾ k \overline{A}^k Ak 和 C A ‾ k B ‾ C \overline{A}^k \overline{B} CAkB 来实现,并行处理每个输入对应的贡献。,所以我们的输出 y 1 − y k y_1-y_k y1−yk 都是可以并行化计算的。仅仅是针对不同时间步的输入卷积核大小不一样,这实际上是可以提前预见(存在着一定的规律)的所以并行化处理很容易。当然我上面是以 k = 0 k=0 k=0 举例子,如果 k k k 为一个固定数值这和咱们的CNN差不多了,就是当时间的输出依赖于前面的 t − k t-k t−k 个时间步的输入。如果是 k = 2 k=2 k=2 那我计算输入5的输出就是 需要通过 3,4,5 作为输入然后卷积的权重通过 C A ‾ k B ‾ C \overline{A}^k \overline{B} CAkB 计算三个然后得到最终的输出。以上内容好好理解这是全文的核心。
再看下,下面的这个图,最左侧就是一个连续形态的SSM。我们将SSM类比成CNN就是最右侧的形态
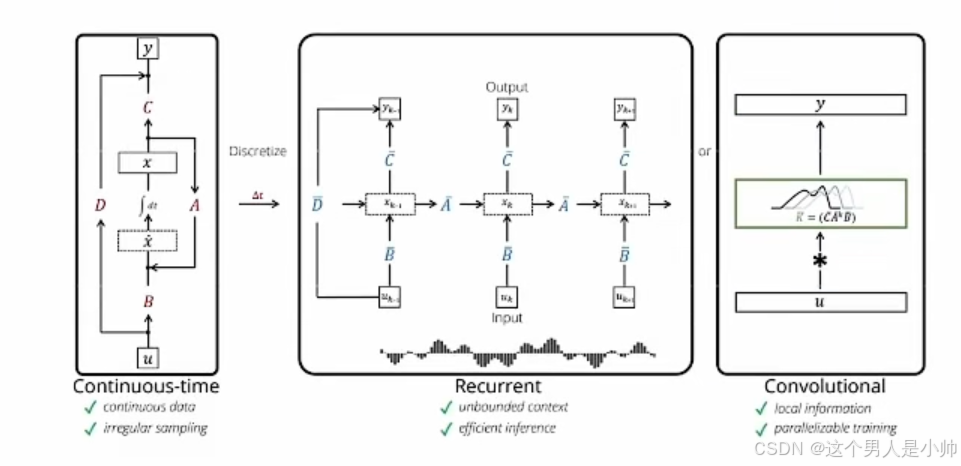
说起来可能是比较抽象,实际这个卷积核是由多个不同的卷积核构成,我们类别CNN在和时间维度上的展开不就是相同的卷积核按照时间步的不同复制成了时间步一致的多个嘛,同样如果SSM按照时间步展开,我们上面公式就得到了多个卷积核,这些卷积核的权重也是由咱们上面的 A ‾ k \overline{A}^k Ak和 C A ‾ k B ‾ C \overline{A}^k \overline{B} CAkB来实现,就是存放着多行权重分别对应不同输入。我们说一行的权重就是一个卷积核而已。每一行都可以通过上述公式计算得到:
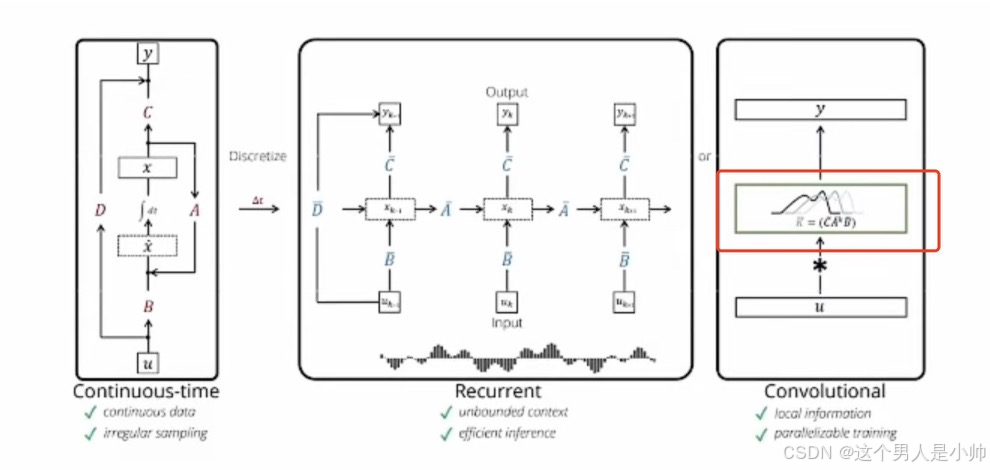
上面说了很多抽象的理解,可能有些读者还是不理解折麽卷积核到底是怎么回事我再解释下。
我这里再画一个图去解释下SSM的并行化,实际上很简单:

如果各位还是不理解的话,可以私信评论都可以。当然我建议各位反复的去看抽象的概念和我上面的这个图相互的理解。就能看懂这部分的内容了。当然我上面举例子是k=0的情况,即使当前输出考虑全部的输入的情况。当然也可以k取一个数值做一个窗口的理解,当然这部分我不讲解的,各位自己做一个小的思考想象一下是什么样子的吧。
大家有没有发现为什么RNN一样的核心思想却不能实现并行化呢???
我们看下这个图。
文章开头提到过可以看到
B
,
C
B,C
B,C 是向量而
A
A
A 是矩阵。而RNN中则是
U
,
V
,
W
U,V,W
U,V,W 则全是矩阵,RNN 的参数矩阵和状态更新的序列依赖性确实限制了其并行处理能力。而上述内容我们也看到了SSM 的参数形状和更新策略可以提供了更多并行化的可能性。同样这个
B
,
C
B,C
B,C的维度是随着输入的维度变化而变换。
至此, SSM 可以像卷积神经网络CNN一样进行并行训练。训练速度显著提升,但是推理速度变慢了。
有同学对此疑惑为什么CNN推理逻辑就变慢了呢??
其实很简单就是CNN训练的时候的和推理一样的策略,就是不断的使用输入和卷积核做一个加权求和。这实际上需要大量的乘积运算,但是在RNN中做的就很简单了,对当前输入和之前的计算结果进行乘积操作,这里最多仅需要三次乘积操作即输入的线性上一步的线性变化以及输出的线性变化吗,但是CNN则要进行多次即一个图和卷积核大小决定的。
所以推理的时候使用并行化形式不好用。
我在墨迹几句,训练的时候这么计算每一个输出:
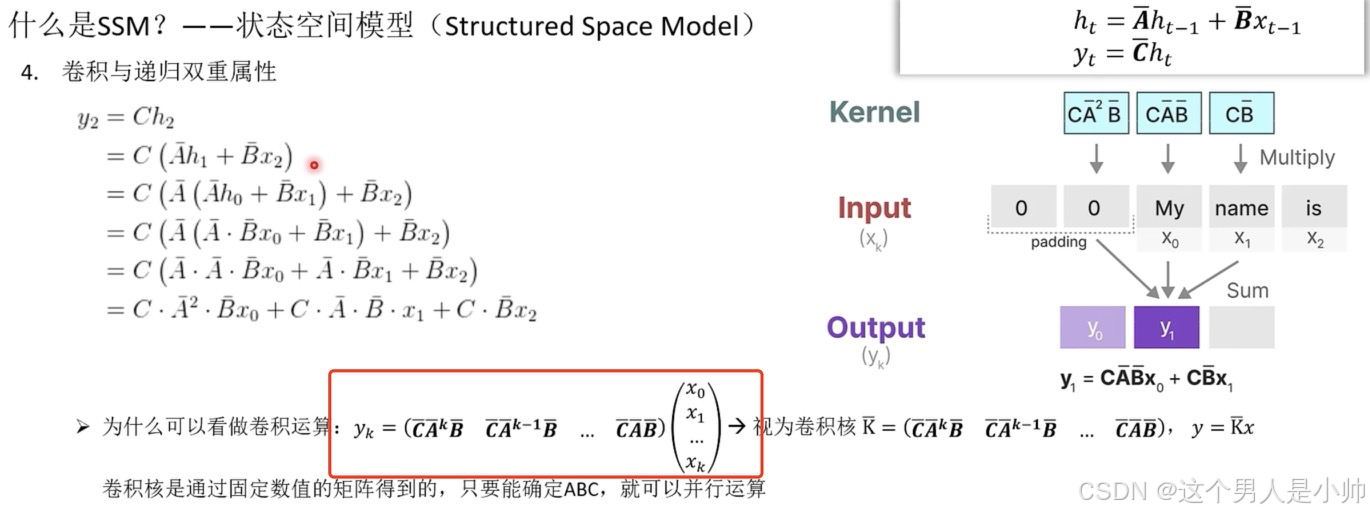
但是同样我们要要在推理过程中这么计算多费劲啊,会反复的计算前几项的计算结果,极大的浪费了算力。而RNN中则不会这样就是上一步的状态当前的输入然后计算即可。所以我们在并行时候训练可以,但是推理太费劲了。那怎么办??

就是上述这个图中例子你不展开一步一步的算不就得了嘛!!!!
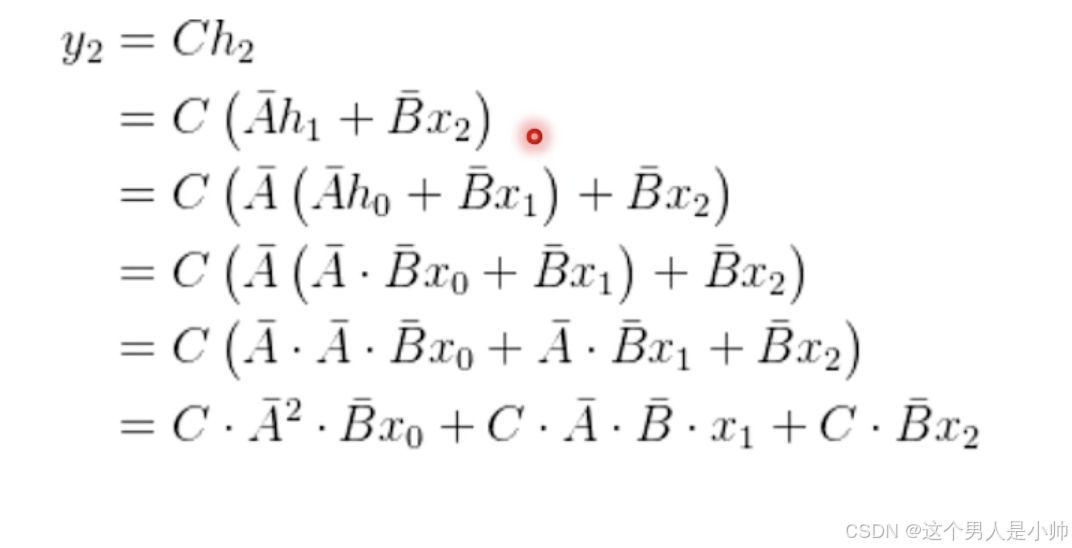
不断的使用前一次的递归结果进行新的运算,就避免了计算资源的浪费从而减少了计算的时间。
okk可算是讲完了,下面这个图就是上述内容的解释。
各位可以看看上图咱们最后一个结果实际上要算一下之前的全部数值。所以一种满足CNN的并行化优势的又可以推理速度是RNN的形态的解决方案出现了SSMs。如下图所示:
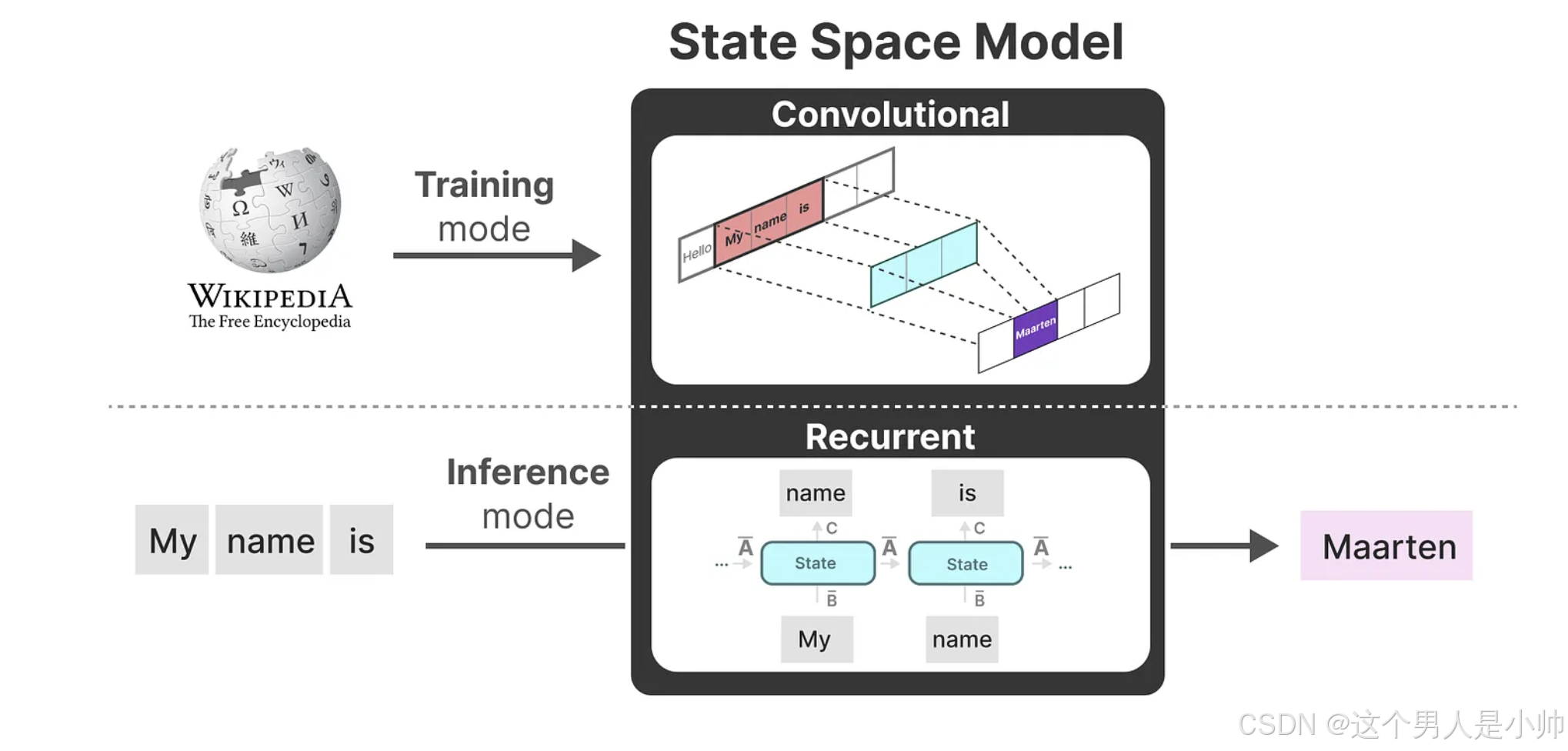
作为从输入信号到输出信号的参数化映射,SSMs可以当做是RNN与CNN的结合即推理用RNN结构,训练用CNN结构,推理用RNN,这类模型可以非常高效地计算为递归或卷积,在序列长度上具有线性或近线性缩放。简简单单的引入下即可,下一节我们将讲解mamba作者的前身科研成果河马🦛HiPPO。一步一步的走入mamba的世界。
这一章节确实复杂我这里参考了七月在线的博文地址如下:
https://blog.youkuaiyun.com/v_JULY_v/article/details/134923301
以及耿直哥的bilibili
【AI大讲堂:革了Transformer的小命?专业拆解【Mamba模型】】https://www.bilibili.com/video/BV1Xn4y1o7TE?vd_source=b7c9754d71e965f7f4e222f89a682d23
当然如果你看过之后发现俺加了很多很多的自己理解,各位自行参考即可。
4. 总结
这仅仅是Mamba详解(2) 【离散SSM和SSM并行化的理解】,我们讲解了连续SSM和离散SSM的不同,以及为什么要对SSM离散化。后续又解释了为什么SSM和RNN如此相似却可以并行化的问题,最后再讲了如何既能使用并行训练能有使用递推进行推理的良好形式的SSM,我相信这两节的学习你一定是对这个SSM又了一个清晰的认识。如果你对这样的讲解方式觉得有趣,喜欢。欢迎催更。如果帮助到你十分荣幸。
对这些内容感兴趣的朋友们,通过点赞、收藏和关注来表达你们的支持是对我的极大鼓励。
如果你感觉还不错的话也可以打赏一杯咖啡钱,非常感谢大家!有任何问题或建议,欢迎随时通过私信评论与我交流。期待你们的反馈。




















 6908
6908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











