







0. 原理
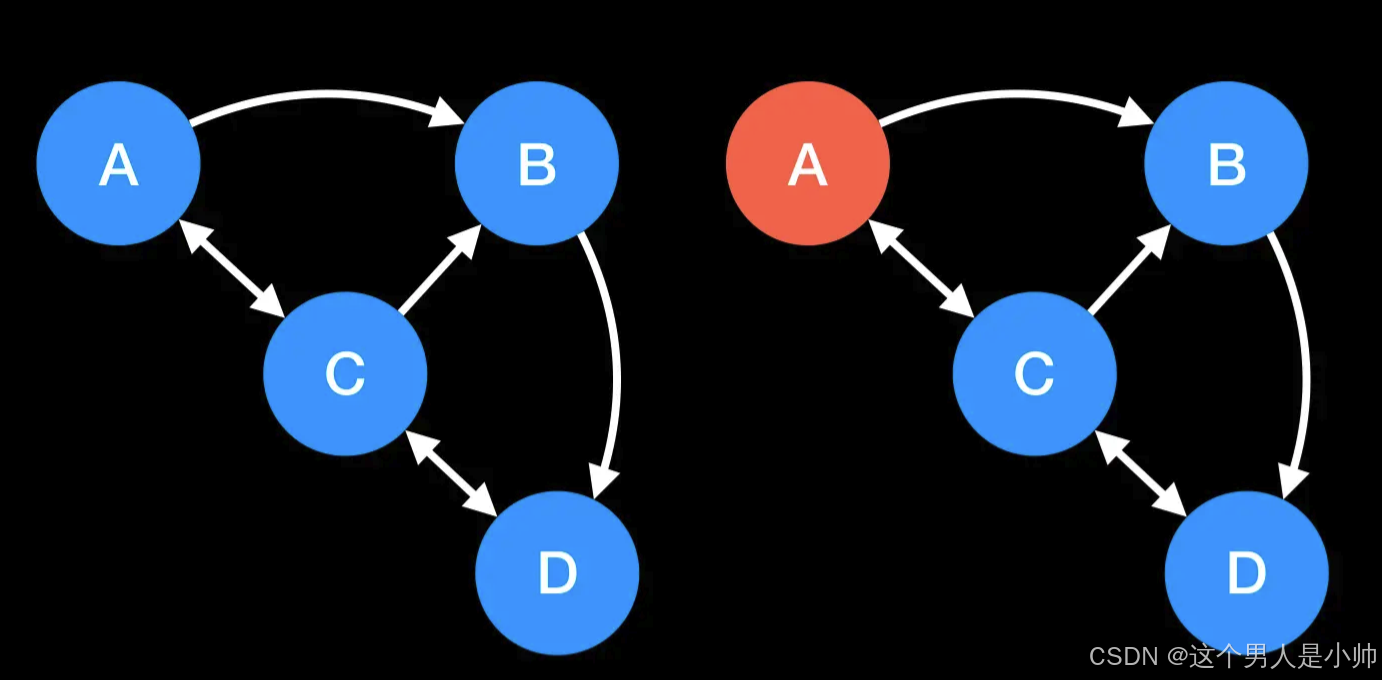
PageRank通过分析互联网上庞大的超链接关系网来确定一个网页的等级。理论上,A页面到B页面的链接被视为A页面对B页面的一票支持。Google 根据这些投票的来源(以及来源的来源,即链接到A页面的页面)以及这些页面的等级来确定新的等级。简而言之,一个高等级的页面通过其链接能够提升其他页面的等级。

1. 算法示例

考虑一个包括四个页面的小网络:A、B、C 和 D。如果所有页面都链接到A,那么A的PageRank值将是B、C 和 D的PageRank值之和。同时假设B链接到C,D链接到包括A在内的三个页面,但一个页面的所有出链的影响是平均分配的。因此,如果B对每个页面投半票,而D对每个页面只投三分之一票,则A
的PageRank计算公式如下:
R ( A ) = R ( B ) 2 + R ( C ) + R ( D ) 3 R(A) = \frac{R(B)}{2} + R(C) + \frac{R(D)}{3} R(A)=2R(B)+R(C)+3R(D)
或者用另一种形式表示为:
R ( A ) = R ( B ) L n ( B ) + R ( C ) L n ( C ) + R ( D ) L n ( D ) R(A) = \frac{R(B)}{L_n(B)} + \frac{R(C)}{L_n(C)} + \frac{R(D)}{L_n(D)} R(A)=Ln(B)R(B)+Ln(C)R(C)+Ln(D)R(D)
其中 L n ( X ) L_n(X) Ln(X) 表示页面X的出链接数量。
2. PageRank 的计算
对于任一页面 p i p_i pi,其PageRank值计算公式为:
R ( p i ) = 1 − d N + d ∑ p j ∈ M ( p i ) R ( p j ) L n ( p j ) R(p_i) = \frac{1-d}{N} + d\sum_{p_j\in M(p_i)}\frac{R(p_j)}{L_n(p_j)} R(pi)=N1−d+dpj∈M(pi)∑Ln(pj)R(pj)
这里 d d d 是阻尼系数,
大家可能不是很懂这个阻尼系数,我在这里简单的解释下。就是如果单纯的按照上述公式中 R ( A ) = R ( B ) L n ( B ) + R ( C ) L n ( C ) + R ( D ) L n ( D ) R(A) = \frac{R(B)}{L_n(B)} + \frac{R(C)}{L_n(C)} + \frac{R(D)}{L_n(D)} R(A)=Ln(B)R(B)+Ln(C)R(C)+Ln(D)R(D) 这样定义一个网站好坏是不是过于片面了呢。仅仅是其他网站的设置的超链接过多就可以定义这个网站很好,显然过于片面。所以引入这个一个 d d d 控制一个网页的好坏和其被其他网页的超链接多少有关系,但是并不是百分百的,是可控的从而让数值更接近于真实的情况。这里仅仅是引入下一节详细讲讲这个d
对所有页面 N N N,PageRank分配的形式为矩阵:
R = [ 1 − d N ⋮ 1 − d N ] + d [ l 1 , 1 ⋯ l 1 , n ⋮ ⋱ ⋮ l n , 1 ⋯ l n , n ] R \mathbf{R}=\left[\begin{array}{c} \frac{1-d}{N} \\ \vdots \\ \frac{1-d}{N} \end{array}\right]+d\left[\begin{array}{cccc} l_{1,1} & \cdots & l_{1,n} \\ \vdots & \ddots & \vdots \\ l_{n,1} & \cdots & l_{n,n} \end{array}\right]\mathbf{R} R= N1−d⋮N1−d +d l1,1⋮ln,1⋯⋱⋯l1,n⋮ln,n R
其中,如果 p j p_j pj 不链接到 p i p_i pi,则 l i , j = 0 l_{i,j} = 0 li,j=0。对于任意页面 j j j,有 ∑ i = 1 N l i , j = 1 \sum_{i=1}^N l_{i,j} = 1 ∑i=1Nli,j=1。
3. 阻尼系数的理解
我们这么理解网页的入度,就是其他网站放了另外一个网站的超链接,这可以理解成这个网站被推荐了一次。如果入度很多就是表示这个网站被很多网站推荐了。但是这能用来衡量一个网站的好坏或者是重要性吗显然不够全面,可能一个新网站最初没那么多人推荐但是他内容质量很高呢??或者是大家做成了浏览器书签每次都是直接访问不需要搜索呢。这就是阻尼系数
3.1PageRank 算法的解释与组成:
-
通过链接的重要性:
- 此部分由公式表示: d ∑ p j ∈ M ( p i ) P R ( p j ) L ( p j ) d \sum_{p_j \in M(p_i)} \frac{PR(p_j)}{L(p_j)} dpj∈M(pi)∑L(pj)PR(pj)
- 这意味着网页 p i p_i pi的 PageRank 值依赖于指向它的其他网页的数量和这些网页自身的重要性(即它们自己的 PageRank 值)。这形成了一种“互推机制”,即一个网页被多个重要的网页指向,它自身也会被认为重要。
-
随机跳转的概率:
- 表示为: 1 − d N \frac{1-d}{N} N1−d
- 其中 d d d 通常设为 0.85,因此 1 − d 1-d 1−d是 0.15。这部分代表了用户有时不是通过链接点击进入某个页面,而是通过直接输入网址、使用书签等随机方式访问的概率。
3.2 阻尼系数 d d d 的作用:
- 阻尼系数 d d d 帮助平衡通过链接传达的“推荐信任度”和用户可能的随机访问行为,使整个系统更加贴近实际的网页访问模式。
- 如果没有随机访问部分( 1 − d 1-d 1−d),所有网页的 PageRank 值将完全依赖于链接结构,可能导致那些虽然内容丰富但链接较少的页面得分较低。引入 1 − d 1-d 1−d 使每个页面都有被发现的机会,不论其链接数量。
4. 总结
PageRank技术的主要限制之一是对新页面不够友好。由于新页面通常没有太多外链,它们的初始等级较低,难以与旧页面竞争,即使它们的内容非常优质。这是因为PageRank重视历史链接的积累。其实这个博文主要是为了记录我对 阻尼系数 d d d的理解,先这样吧,如果您感觉还不错麻烦点赞推荐下。


















 2708
2708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











