








0. 引言
相信许多阅读本文的朋友都在学习图神经网络(GNN)。本文的目的是探讨GAT(Graph Attention Networks)作者是如何将 Transformer 技术应用到图神经网络中的。换个角度来说,我们将通过 Transformer 的视角来解析 GAT 中的注意力机制的源泉。如果您对 Transformer 还不太了解,欢迎访问我的博客专栏,其中包含了丰富的NLP入门内容。即使您不是NLP领域的学者,这些内容对您深入理解深度学习和神经网络也大有裨益。点击这里学习更多。
此外,如果您对图神经网络的了解还不够深入,我建议您先阅读相关基础知识。点击此处,强化您的学习基础,为理解接下来的内容做好准备。如果你对我上述说的内容都有过一定的了解,那就不要再次回顾了我会在下面小小的引导你回忆下即可。
1. 注意力机制
Transformer闻名于世的原因,就是其将注意力机制的全局应用,先明确下什么是注意力?
请观看下面这张图片:

请关注图片中标注的 “锦江饭店” 四字。当被要求集中注意力于这几个字时,你的视觉焦点便会主要集中在这一区域,对周围环境的关注度自然降低。比如,如果此时有人询问旁边楼梯的具体层数,你可能会觉得这个问题稍显突兀,因为你的大部分注意力已经聚焦在文字所在区域,而忽略了周围的细节。如下图所示:

当人类处理问题时,通常需要将注意力集中在问题本身上,通过深入思考来寻找解决方案,而不是让注意力涣散在其他无关的事物上。换句话说,解决问题的关键在于将努力聚焦于正确的方向上,如果注意力分散,可能会在错误的路径上越走越远,这不仅低效而且可能显得有些荒谬。
2. 注意力机制的实现
在技术的实际落地中,,注意力机制常被以百分比的形式描述,模型通过学习如何在处理输入信息时分配这些百分比,从而优先处理最关键的信息。这种方式不仅帮助模型集中关注最重要的数据,而且还模仿了人类在处理海量信息时筛选关键细节的能力。同样这也比较符合人类的直觉。
2.1 Transformer 的注意力机制
在Transformer,使用了三个权重矩阵来完成这一操作。即再后来广为流传的 Q , K , V Q,K,V Q,K,V三个矩阵。
那么,如何设计注意力机制呢?
简单来说,可以通过描述不同区域的关注程度的百分比来实现。
实际上,这仅仅涉及到了利用三个不同的权重矩阵 W W W 对输入 X X X 进行三次线性变换。具体过程如下:
Q = X W q K = X W k V = X W v Q = XW_q \\ K = XW_k \\ V = XW_v Q=XWqK=XWkV=XWv
这说明,当Transformer模型将输入 X X X 分别通过 W q W_q Wq、 W k W_k Wk、 W v W_v Wv 进行线性变换时,其实是获取了 X X X 经过不同 W W W 的线性映射。这些变化后的形式,无论是经过 W q W_q Wq 还是 W k W_k Wk 的变换,都与输入信息保持一致,每一行代表一个词的嵌入表示,但 W W W 的权重不同,关注了不同的信息重点(或者是其看待相同数据的角度不同而已)。
为了让此过程更加直观,以下图片展示了整体 Q Q Q、 K K K、 V V V 计算的过程:

尚未出现百分比的具体情况。
注意力分数的计算过程
根据论文描述的实际计算流程如下:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
- Q Q Q 代表查询(Query)矩阵;
- K K K 代表键(Key)矩阵;
- V V V 代表值(Value)矩阵;
- d k d_k dk 是键(Key)矩阵的维度,用于缩放点积大小,防止梯度消失;
softmax函数将点积转换为权重分布。
下图直观展示了 (QK^T) 计算注意力矩阵的过程:

通过 softmax 操作后,
Q
K
T
QK^T
QKT 矩阵中的每一行和为1,其中的值表示了第一个单词相对于句子中所有单词的注意力分数,其他行依此类推。现在权重已经找到,只需通过这些权重对线性变换后的
V
V
V 矩阵进行加权求和,就能获得最终的输出
Z
Z
Z 矩阵。下图展示了计算
Z
Z
Z 矩阵第一行的过程,以便读者更好地理解这一机制。

简单总结下,Transformer实现注意力机制的精髓在于通过线性映射和动态加权聚焦机制,提取和处理输入信息中最关键的部分。下面进行一个清晰简洁的总结:
-
三个权重矩阵:Transformer 使用三个不同的权重矩阵 W q W_q Wq、 W k W_k Wk 和 W v W_v Wv 对输入 X X X 进行线性变换,分别得到查询(Query)、键(Key)和值(Value)矩阵:
- Q = X W q Q = XW_q Q=XWq
- K = X W k K = XW_k K=XWk
- V = X W v V = XW_v V=XWv
-
计算注意力得分:注意力得分是通过查询矩阵 Q Q Q 和键矩阵 K K K 的转置乘积来计算的,再通过缩放因子 d k \sqrt{d_k} dk 进行调整,以保证数值稳定性:
Attention Scores = Q K T d k \text{Attention Scores} = \frac{QK^T}{\sqrt{d_k}} Attention Scores=dkQKT -
应用Softmax:将注意力得分通过
softmax函数转换成概率分布形式,这确保了每个输出元素的注意力是根据其重要性自适应调整的,即每行的和为1:
Attention Weights = softmax ( Attention Scores ) \text{Attention Weights} = \text{softmax}(\text{Attention Scores}) Attention Weights=softmax(Attention Scores) -
加权求和:最终输出是通过将注意力权重与值矩阵 V V V 相乘,实现对信息的加权求和,充分融合了各部分的信息重点:
Output = Attention Weights × V \text{Output} = \text{Attention Weights} \times V Output=Attention Weights×V
简而言之,最大的功劳就是这三个权重矩阵 W W W
2.2 GAT 的注意力机制
那么GAT中的注意力机制是如何实现的呢?????
当然有很多同学一定是看过我的GAT论文精讲,GAT的注意力是这样的:

公式是这样的:
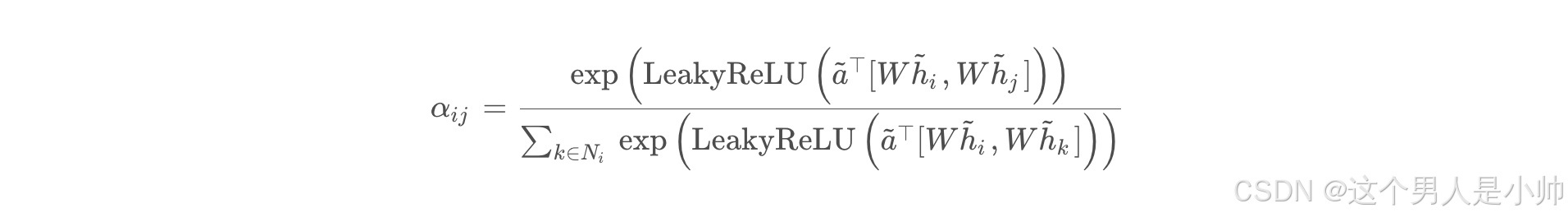
好像是和这个Transformer不是很像啊???
咱们看看代码这个注意力是如何实现的:
class GraphAttentionLayer(nn.Module):
"""
Simple GAT layer, similar to https://arxiv.org/abs/1710.10903
"""
def __init__(self, in_features, out_features, dropout, alpha, concat=True):
super(GraphAttentionLayer, self).__init__()
self.dropout = dropout
self.in_features = in_features
self.out_features = out_features
self.alpha = alpha
self.concat = concat
self.W = nn.Parameter(torch.empty(size=(in_features, out_features)))
nn.init.xavier_uniform_(self.W.data, gain=1.414)
self.a = nn.Parameter(torch.empty(size=(2*out_features, 1)))
nn.init.xavier_uniform_(self.a.data, gain=1.414)
self.leakyrelu = nn.LeakyReLU(self.alpha)
def forward(self, h, adj):
Wh = torch.mm(h, self.W) # h.shape: (N, in_features), Wh.shape: (N, out_features)
e = self._prepare_attentional_mechanism_input(Wh)
zero_vec = -9e15*torch.ones_like(e)
attention = torch.where(adj > 0, e, zero_vec)
attention = F.softmax(attention, dim=1)
attention = F.dropout(attention, self.dropout, training=self.training)
h_prime = torch.matmul(attention, Wh)
return F.elu(h_prime)
def _prepare_attentional_mechanism_input(self, Wh):
# Wh.shape (N, out_feature)
# self.a.shape (2 * out_feature, 1)
# Wh1&2.shape (N, 1)
# e.shape (N, N)
Wh1 = torch.matmul(Wh, self.a[:self.out_features, :])
Wh2 = torch.matmul(Wh, self.a[self.out_features:, :])
# broadcast add
e = Wh1 + Wh2.T
return self.leakyrelu(e)
大家可以看这段代码:
Wh = torch.mm(h, self.W)
在Graph Attention Network (GAT)中的作用和在Transformer中的作用类似。在两者中,这行代码都实现了对输入特征矩阵的线性变换。
-
映射特征空间:通过与权重矩阵 (W) 的乘积,将输入特征 (h)(或 (X) )从原始特征空间映射到一个新的特征空间。这可以被视作是对数据进行一种转换或编码,旨在捕捉不同特征之间的相互作用并增强模型的表达能力。
-
参数化学习:在深度学习模型中,这种线性变换是可学习的,意味着权重矩阵 (W) 会在模型训练过程中更新以最好地完成既定的任务(例如分类、预测等)。这是模型学习如何从数据中提取有用信息的一个基本步骤。
上述代码就是实现了 W X WX WX 的操作过程,但是大家回忆下 Transformer中使用了三次 W W W 才得到了一组 Q Q Q K K K V V V 。
我们继续看看GAT是如如何实现注意力矩阵的计算的 :
Wh1 = torch.matmul(Wh, self.a[:self.out_features, :]) # 可以类比成Q
Wh2 = torch.matmul(Wh, self.a[self.out_features:, :]) # 可以类比成k
# broadcast add
e = Wh1 + Wh2.T # 实现QK操作
作者利用一个 注意力向量 a a a 巧妙的创造了 Q , K Q,K Q,K ,注意我这里用的创造,即使用共享注意力向量 a a a 创造了 Q , K Q,K Q,K 但是这里创造的 Q , K Q,K Q,K 不再是矩阵了而是向量。
继续看代码 :
Wh1 = torch.matmul(Wh, self.a[:self.out_features, :]) # 可以类比成Q
Wh2 = torch.matmul(Wh, self.a[self.out_features:, :]) # 可以类比成k
这里将被线性映射的节点特征矩阵,利用注意力向量 a a a 的一半,将每一个节点映射成一个数值。再次利用用注意力向量 a a a 的另一半实现了得到了一个向量 Wh2 。所以Wh1和Wh2这两个向量,相同位置,表示的都是同样节点被映射成的数值。
e = Wh1 + Wh2.T # 实现QK操作```
然后做了一个向量的广播加法,最终得到 Q , K Q,K Q,K结果,其实不拘泥于形式, Q , K Q,K Q,K不一定是乘积才能得到注意力矩阵,向量加法也能实现同样的操作。同样的 Q , K Q,K Q,K也不一定非要是矩阵
zero_vec = -9e15*torch.ones_like(e)
attention = torch.where(adj > 0, e, zero_vec)
attention = F.softmax(attention, dim=1)
attention = F.dropout(attention, self.dropout, training=self.training)
h_prime = torch.matmul(attention, Wh)
这里有一个细节需要注意了。
e
e
e 是上面计算得到的注意力矩阵,但是其数值形态不是百分比,所以要用softmax这个没什么问题,但是文中使用了邻接矩阵作为mask矩阵,这是为了直接实现邻域聚合,但是这也掩盖不住,实际上计算了和全部节点的注意力情况,所以并不像论文中提到的仅仅依赖于graphsage中的邻域聚合
但是其还是很厉害的,使用了一个 W W W 矩阵将节点特征映射成了 W h Wh Wh 然后又借助于一个注意力向量 a a a 就形成了transformer中需要两个 W W W 才能做到的注意力矩阵 Q K QK QK 的结果。为什么是连个 W W W 呢???对吧还有一个 V V V 没有计算呢!!
attention = torch.where(adj > 0, e, zero_vec)
最终将原始邻接矩阵作为mask矩阵,得到了最终的注意力矩阵。那么问题来了 V V V 矩阵是怎么得到的呢????
在GAT的注意力逻辑下 Q , K Q,K Q,K 都已经是向量了,但是 V V V 仍然是矩阵。这是为什么呢?可以评论下,我看看你是怎么想的????
咱们就是说这个GAT作者是真聪明,人家再次复用了这个参数矩阵 W h Wh Wh 。这样通过一组 W a Wa Wa 就完成了三组 W W W 需要做的工作. 一定程度上这个其 W W W 可以说成是权重共享。
最后最后我再强调一下。
实际上注意力矩阵的计算是要依托于全部节点特征计算得到的。
并不是仅仅依靠邻居的特征计算得到的。
3. 总结
其实最大的启发就是,GAT作者对注意力的理解确实十分强大, 在时间上不是简单的嫁接而是真正的改进了精髓,形神具备。有一个问题就是没实现按照邻接矩阵进行注意力的计算还是进行了全局注意力的计算。这一点也是其性能受限的原因吧,主要是和论文中表述不一致,不过还是很厉害的。好了好了不废话了。
对这些内容感兴趣的朋友们,通过点赞、收藏和关注来表达你们的支持是对我的极大鼓励。
如果你感觉还不错的话也可以打赏一杯咖啡钱,非常感谢大家!有任何问题或建议,欢迎随时通过私信评论与我交流。期待你们的反馈。




















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











