




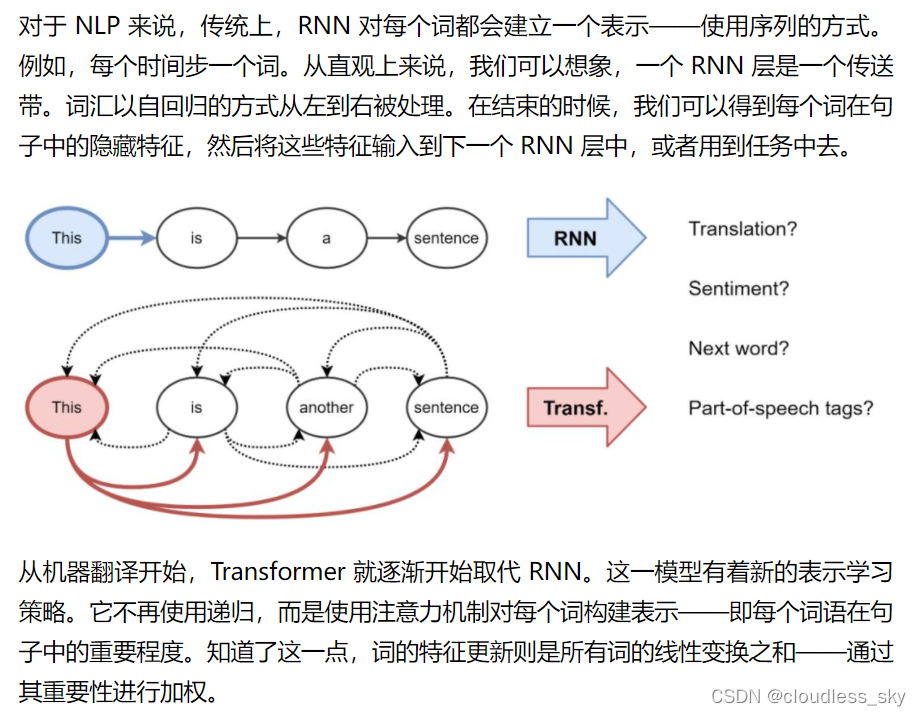
注意力机制能够显著提高神经机器翻译任务的性能。本文将会看一看Transformer—加速训练注意力模型的方法。Transformers在很多特定任务上已经优于Google神经机器翻译模型了。不过其最大的优点在于它的并行化训练。
Transformer模型:

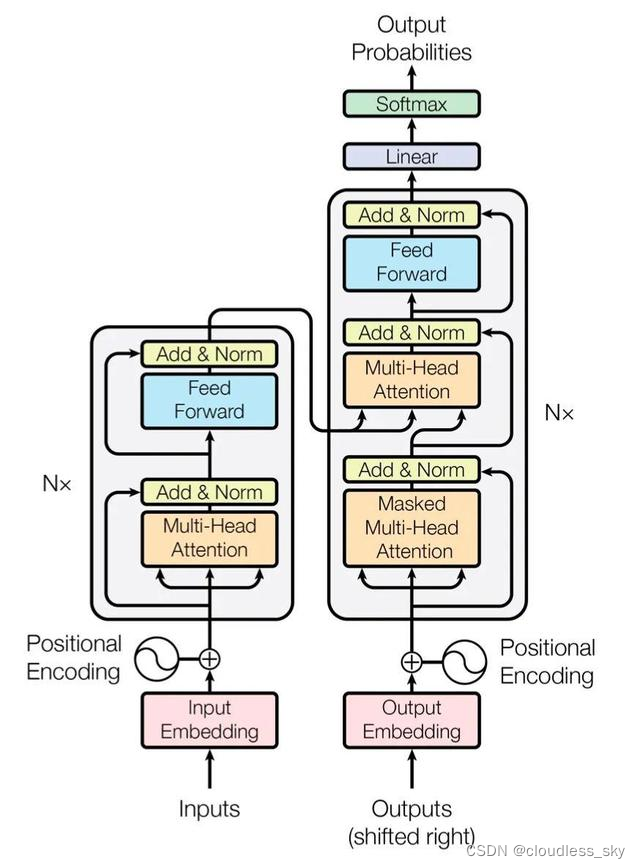
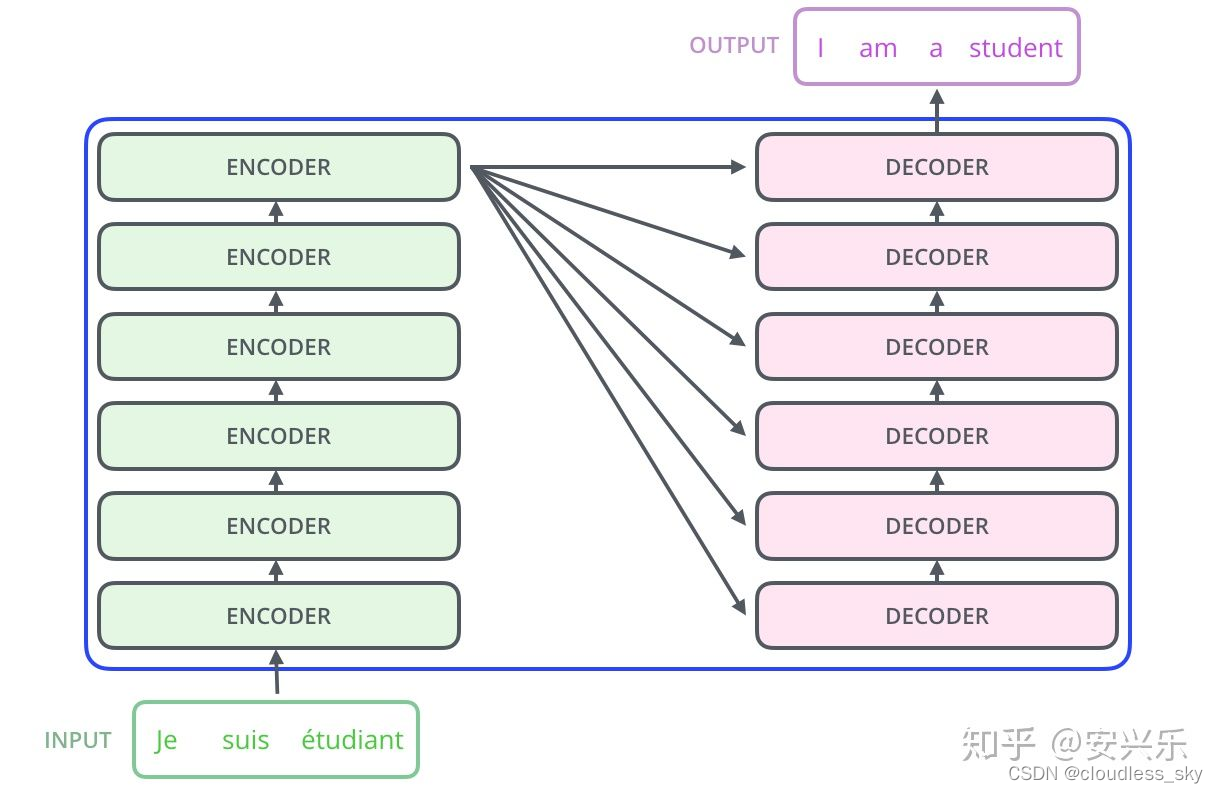
编码组件是一系列编码器的堆叠(文章中是6个编码器的堆叠——没什么特别的,你也可以试试其他的数字)。解码部分也是同样的堆叠数。
编码器在结构上都是一样的(但是它们不共享权重)。每个都可以分解成两个子模块:
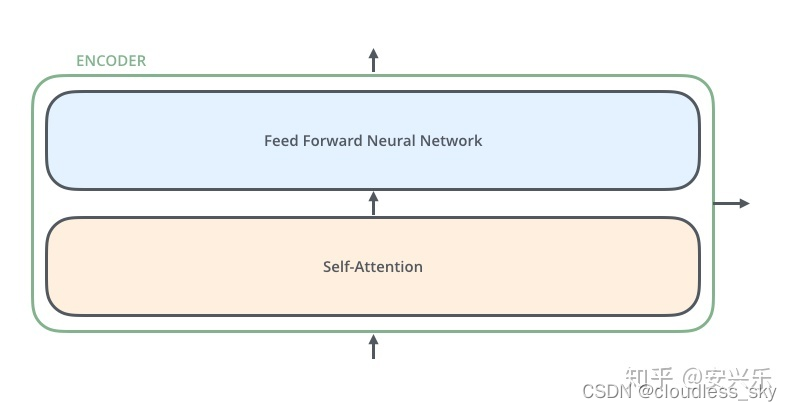
编码器的输入首先流经self-attention层,该层有助于编码器对特定单词编码时查看输入序列的其他单词。本文后面将会详细介绍self-attention。
Self-attention层的输出被送入前馈神经网络。完全相同的前馈神经网络独立应用在每个位置。
解码器也具有这两层,但是这两层中间还插入了attention层,能帮助解码器注意输入句子的相关部分(和seq2seq模型的attention相同)。
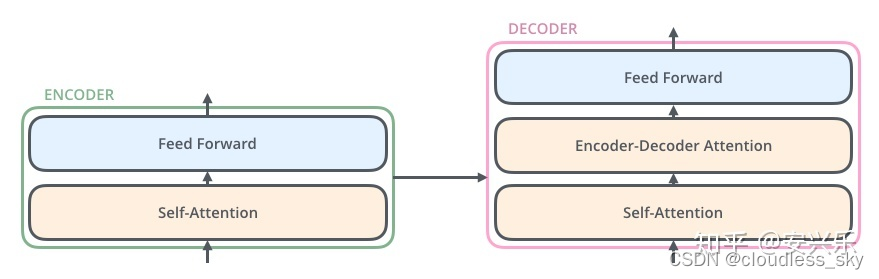
上面我们看到了模型的主要部件,我们现在开始研究各种向量/张量以及他们如何在这些组件中流动来将训练好的模型的输入转换为输出。
和传统NLP任务一样,我们首先使用词嵌入来将每个输入单词转换为向量。

词嵌入仅发生在最底部的编码器中。所有编码器的共同之处是他们接收元素大小为512的向量列表——在最底部的编码器中这恰好是词嵌入后的大小,而在其他的编码器中这恰好是其下面编码器输出的大小。这个列表大小是我们设置的超参数----基本上它就是训练集中最长句子的大小。在输入序列中进行词嵌入后,每一个输入都将会流过编码器的两个层。

这里我们看到Transformer一个重要特性,每个位置的单词在经过编码器时流经自己的路径。self-attention层中这些路径之间有依赖关系。然而前馈层并不具有这些依赖关系,所以各种路径在流经前馈层时可以并行执行。下面我们将例子中句子换为更短的句子来看一下每个编码器中的子层发生了什么。
开始编码
上面提到过,编码器接受向量列表作为输入。编码器将向量列表传入self-attention层,之后进入前馈神经网络,然后再输出到下一个编码器。
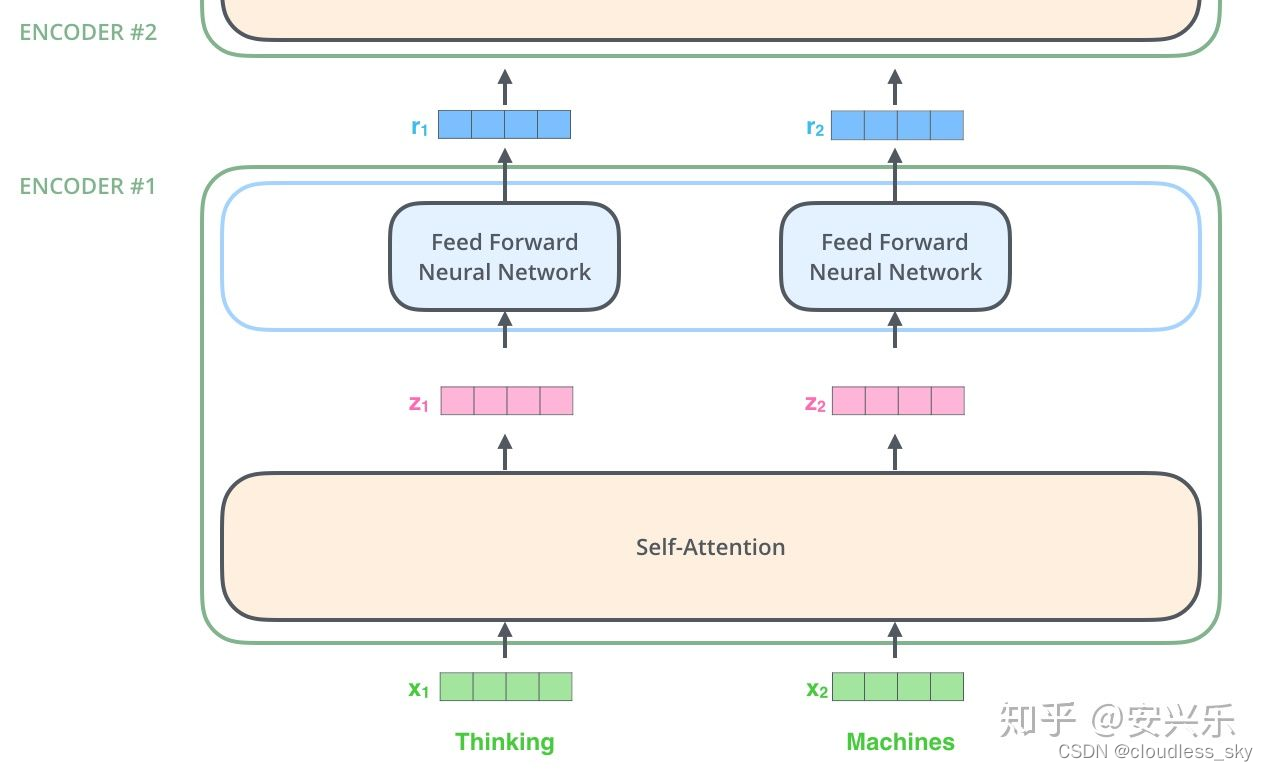
更高的视角看self-attention

句子中“it”指的是什么?指street还是说animal呢?对人来说很简单的问题,对机器却很复杂。
当模型处理单词“it”时,self-attention 就可以使它指代“animal”。
当模型处理每个单词时(输入序列中每个位置),self-attention使得它可以查看输入序列的其他位置以便于更好的编码该单词。
如果你熟悉RNN,考虑一下如何维护隐藏层状态来更好的结合已经处理的先前的单词/向量与目前正在处理的单词/向量。Transformer使用self-attention来将其他相关单词的“理解”融入到目前正在处理的单词。


Self-Attention 细节
首先我们看看如何使用向量计算self-Attention,之后再研究它如何实现的———使用矩阵实现呗。
计算self-attention的 第一步 需要从每个编码器的输入向量(这个例子中是每个词的词嵌入表示)创建三个向量。因此,对于每个单词,我们创建一个Query向量,一个Key向量和一个Value向量。这些向量是通过将词嵌入(embedding)乘以在训练过程中训练的三个矩阵来创建的。
注意,这些新创建的向量的维度小于词嵌入向量(embedding vector)。它们(新创建的向量)的维度是64,而词嵌入和编码器的输入输出向量的维度是512。它们不必更小,这是一种架构选择,可以使多头注意力(multiheaded attention)计算不变。
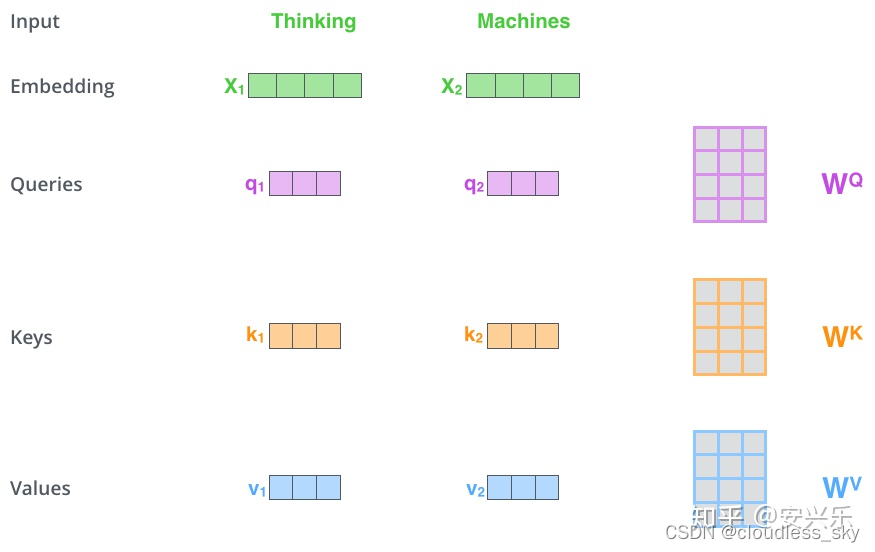
那么,究竟什么是“query”,“key”,“value”向量呢?
计算self-attention的 第二步 是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1169
1169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









