



本次上机,先声明了一个类,一个类也就是一种数据类型,每一种数据类型都是对一类数据的抽象。声明了类之后,需要定义对象来进行使用,可以通过对象名和对象选择来访问对象中的成员。声明类的方法与声明结构体类型的方法相似第一行“class Coordinate”是类头,其后花括号内的内容是类体。在声明类的同时,可直接定义对象,也可以在使用时定义对象,程序中的“Coordinate x”即为定义的对象。
构造函数是一个特殊的公共成员函数,它在创建类对象时会自动被调用,用于构造类对象。当两个或多个函数共享相同的名称时,就为函数重载。只要其形参列表不同, 程序中可能存在具有相同名称的多个函数。程序中,也对构造函数进行了重载,第一个构造函数没有形参,第二个构造函数有一个形参。析构函数是具有与类相同名称的公共成员函数,前面带有波浪符号,当对象被销毁时,会自动调用析构函数。在创建对象时,构造函数使用某种方式来进行设置,那么当对象停止存在时,析构函数也会使用同样的方式来执行关闭过程。
本次上机,使用了类和对象进行编制c++程序,通过实验结果,显示出构造函数和析构函数的执行顺序,在调用时,最先被调用的构造函数,其对应的(同一对象中的)析构函数最后被调用,而最后被调用的构造函数,其对应的析构函数最先被调用。调用析构函数的次序正好与调用构造函数的次序相反。理解了构造函数和析构函数的使用方法,并能正确进行应用。
上机过程中,整体是顺利的,能够完成任务。但还存在一些具体细节问题,程序有语法错误导致编译出错,cin后应是输入的内容,应使用>>来衔接cin,而使用<<来衔接cout,
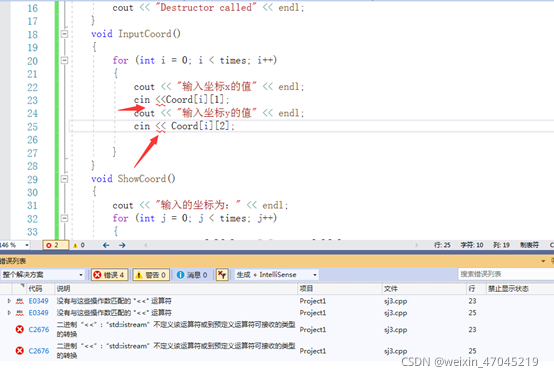
不可取反,否则就会发生错误。有些地方的程序是有相同之处的,我直接将其复制粘贴过来,然而忘记修改,或者是修改不全,都会使程序运行错误,能成功编译,但结果确实偏离的。如下图,输出的x,y的坐标是相同的,所以在编程时要仔细认真编写,有些错误难免发现不了,系统也不会报错,所以这种问题是非常重要的。我也是重新阅读的一遍程序,梳理了一下逻辑才将其进行改正。
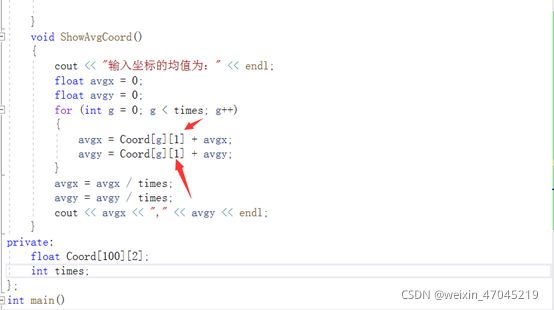
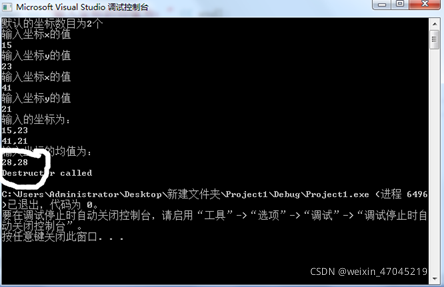
此次上机,我掌握了声明类和对象的方法,参照声明结构体类型,能够正确声明出类,并定义出对象,同时也理解了构造函数和析构函数的实现方法,先调用构造函数,撤销对象时,调用析构函数,最先调用的构造函数,最后调用其相对应的析构函数。明白了其执行的顺序。在main函数加入“Coordinate y(5)“时,则输入的的坐标数目为5,然后就是输入5 个坐标,求其平均值,此时坐标数目就不是默认值2。以此类推可以求得多个坐标平均值。

















 5211
5211




 到【灌水乐园】发言
到【灌水乐园】发言







