









写在前面
github上的项目通常代码本身的质量是有保证的,主要难点在于环境配置上,很多时候并不是简单的pip install -r requirement就行了,还要额外解决很多意料之外的报错和环境冲突,本文主要记录复现项目的探索过程以及踩过的坑。
最近在研究隐写,所以找的项目还是隐写相关,项目地址在此,该项目是基于扩散生成的隐写项目,要使用diffuser进行生成,再利用DDIM进行逆变换获取原图。

下载可使用git clone或直接download zip,该项目依赖的库很少,只有下面五个,所以复现起来也相对比较容易,适合作为第一次复现的尝试。
torch
transformers==4.33.2
diffusers==0.21.2
huggingface-hub==0.17.2
safetensors==0.3.3
本次复现最大的收获就是:
按部就班,不要想当然。复现第一步就是要把项目跑起来,完全按照README说的来,运行起来以后再谈改进。本次走的弯路基本都是来自想当然地想替换下模型,使用更新版本的库,导致很多不相干的错,又判断不了错的具体原因,耽误了很多时间。
下面是本次复现的探索过程,正确直接的配置过程可直接跳到环境配置部分。
探索过程
torch的安装稍微复杂,可以参见以前的文章,从零安装pytorch,在安装transformers和safetensors报了下面两个错:
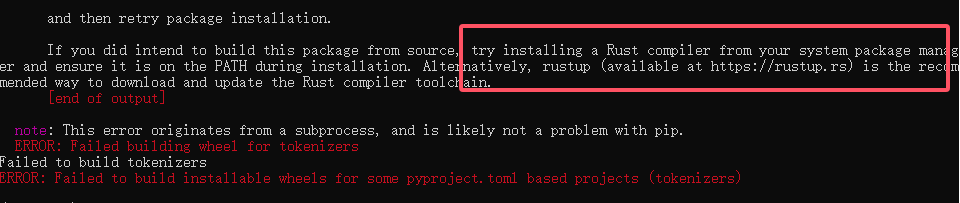

看报错信息加上网查询得知是缺少rust环境,去下载了rust安装又有如下提示:

提示为rust安装又缺少环境,提供了三种方法,最简单的是第一种,用visual studio自动安装,下载visual studio以后要安装十个G的C++环境。
到这里我觉得有点不对了,我只是想装两个库,不至于这么麻烦吧?我是相信奥卡姆剃刀理论的,奥卡姆剃刀就是说若无必要,勿增实体,科学和哲学都应该是简洁优美的,计算机领域也不例外,一个小错要废这么大周章肯定是不对的,所以我转而去找其他解决手段。
最后看网上一个说法,是python版本太高了,因为本机没有显卡,torch环境配了cpu版,所以选择了较高的3.12版本,降到3.9版本后环境就配置成功了。
另外还有如下低级错误,想当然地用更高模型,但不同模型调用的方法也不同,所以吧报了对象缺失错误,失败尝试是想用stable-diffusion 3.5 large

使用3.5 large遇见了提示,该部分涉及硬件问题,large模型完全体跑起来需要24G显存,硬件条件不满足会报错,普通个人用户还是用用medium-turbo版吧,看来GPU上云真是势在必行,同时也是下一波风口了。
torch.outOfMemoryError: CUDA out of memory. Tried to allocate 32.00 MiB.
GPU 0 has a total capacity of 8.00 GiB of which 0 bytes is free.
Of the allocated memory 22.39 GiB is allocated by PyTorch.
不甘心的我还想试试让cpu执行,但最后还是放弃了,直接把cpu占用几乎拉到百分百,跑半天进度条一点不动,现在看来在生成领域没有显卡是肯定不行了。

环境配置
复现项目主要就是配环境,github上的代码质量一般是有保证的,下载后配置一个与代码要求完全一致的环境基本就可以运行,实现简单复现。
python项目的大概复现流程为:
创建虚拟conda环境=>安装requirement中的库=>查看代码中是否有其他依赖=>根据README执行代码,以CRoSS为例的复现步骤如下:
首先使用conda create -n CCRoSS python=3.9创建虚拟环境,然后通过conda activate CRoSS进入到该虚拟环境,前缀发生如下变化说明环境切换成功:

随后去pytorch官网选择合适的torch版本安装,该部分方法详细可见从零安装pytorch

在该项目的README中有现成命令,可直接点击执行,但该步需再次注意当前环境要是解释器的环境,最简单避免混淆的方法就是直接在CCRoSS前缀的命令行中分别输入
pip install transformers==4.33.2
pip install diffusers==0.21.2
pip install huggingface-hub==0.17.2
pip install safetensors==0.3.3
到目前为止如果完全按照本文操作是不会报错的,有错也基本是网络问题,安装好后的环境可使用conda list检验:

可见安装包的版本与requirement完全一致,但该代码依赖于生成模型,

该模型推荐下载后用本地路径替换之,有关该部分操作可见diffuser库使用本地模型生成图像。
最后使用README中的提示进行操作,在conda环境进入到工作目录后,输入python demo.py --image_path ./asserts/1.png --private_key "Effiel tower" --public_key "a tree" --save_path ./output --num_steps 50,代码执行过程的输出提示如下:

执行后可在项目目录下生成一个output文件夹,里面有三个文件,分别是gt密文图像、hide载密图像和reverse恢复的秘密图像,图像分别展示如下:

质量就不评价了,自己在网上找了其他图片,使用如下语句测试python demo.py --image_path ./asserts/cat.png --private_key "cat" --public_key "tiger" --save_path ./test_out --num_steps 80,生成图像与恢复质量分别展示如下:
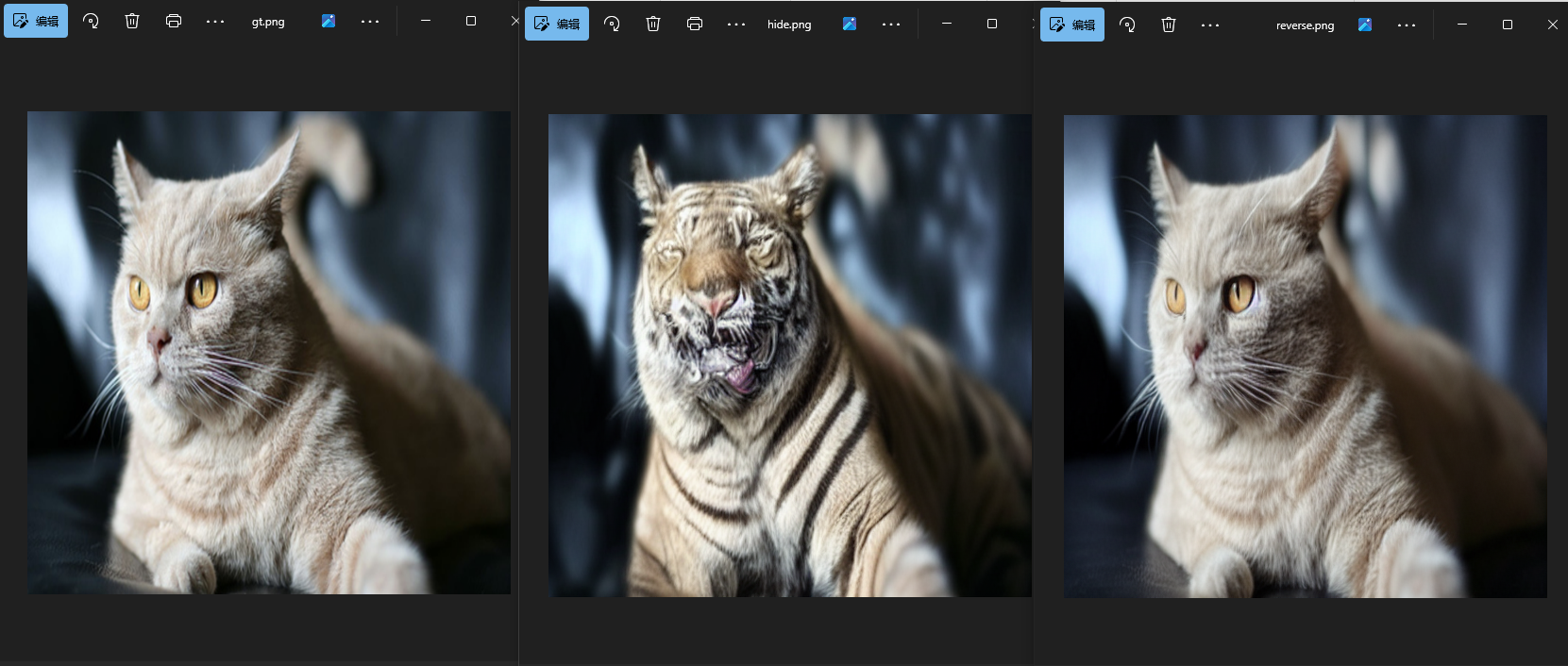
恢复图像的质量没得说,肉眼看来几乎一致,只有虚化的尾部有缺失,但是生成的这老虎图像实在鬼畜,可能是因为生成模型版本的问题,还需要后续继续测试。
可能的报错
直接执行代码可能会报如下错误:
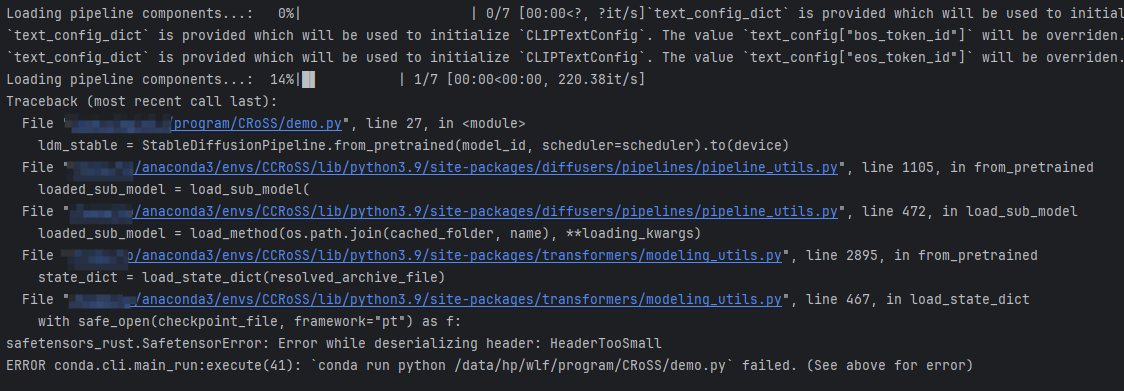
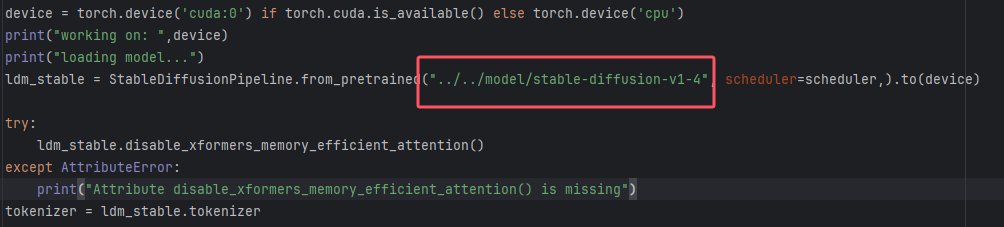
报错提示safetensors HeaderTooSmall,查了下基本是模型有问题,这次模型经历太多次断点续传和移动,所以是可能出问题的,不过模型实在太大,从头再来太费时间,笔者转而使用以前实验过的v1.4版本模型进行生成。
即将模型替换为v1.4,代码上的修改如下:
总结
现在回头看来复现的步骤不难,新建个conda环境,几个库一装,下载个模型就能跑了,但我几乎折腾了四五天。一方面是有的基础环境,比如:
1,python版本并没有在README中说明,报了很多不相干的错导致浪费了很多时间;
2,另一方面是做事不够仔细,步子还迈的大,想一步到位使用最新的模型,却忽视了调用的方法根本都不一样,又浪费了很多时间;
3,最后是模型动辄几十个G,下载上传速度慢,尤其是使用服务器,对网络环境要求高,又耽误了些时间。
不过收获也是有的,就是复现代码先别想太多,按部就班把环境配好代码跑起来才是最主要的,改进方案放到后面。
认识是为了实践,实践又反作用于认识本身,下一步的工作就是对该项目进行改进,比如优化效率,添加新的模块增加功能等。这部分要求我们对原理有更深的认识,还是绕不过学习基础理论。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









