







马尔可夫决策过程
马尔可夫决策过程(Markov Decision Process, MDP)是序贯决策(sequential decision)的数学模型,用于在系统状态具有马尔可夫性质的环境中模拟智能体可实现的随机性策略与回报 。MDP的得名来自于俄国数学家安德雷·马尔可夫(Андрей Андреевич Марков),以纪念其为马尔可夫链所做的研究 。
MDP基于一组交互对象,即智能体和环境进行构建,所具有的要素包括状态、动作、策略和奖励 。在MDP的模拟中,智能体会感知当前的系统状态,按策略对环境实施动作,从而改变环境的状态并得到奖励,奖励随时间的积累被称为回报
表格型方法
MDP四元组(S.A.P.R)
MDP 是序列决策这样一个经典的表达方式。MDP 也是强化学习里面一个非常基本的学习框架。状态、动作、状态转移概率和奖励 (S,A,P,R)(S,A,P,R),这四个合集就构成了强化学习 MDP 的四元组,后面也可能会再加个衰减因子构成五元组。
Model-free
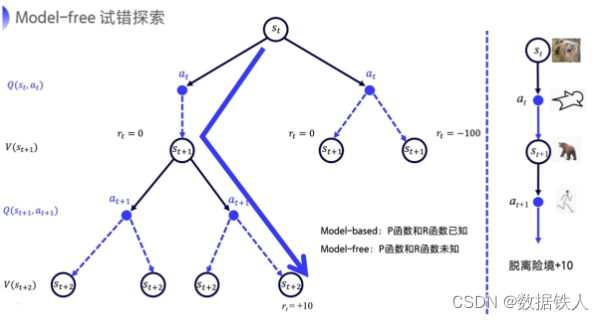
我们是处在一个未知的环境里的,也就是这一系列的决策的概率函数和奖励函数是未知的,这就是 model-based 跟 model-free 的一个最大的区别。
强化学习就是可以用来解决用完全未知的和随机的环境。强化学习要像人类一样去学习,人类学习的话就是一条路一条路地去尝试一下,先走一条路,看看结果到底是什么。多试几次,只要能活命的。我们可以慢慢地了解哪个状态会更好,
我们用价值函数 V(s)V(s) 来代表这个状态是好的还是坏的。
用 Q 函数来判断说在什么状态下做什么动作能够拿到最大奖励,用 Q 函数来表示这个状态-动作值。
Q-table
如果 Q 表格是一张已经训练好的表格的话,那这一张表格就像是一本生活手册。 我们就知道在熊发怒的时候,装死的价值会高一点。在熊离开的时候,我们可能偷偷逃跑的会比较容易获救。
这张表格里面 Q 函数的意义就是我选择了这个动作之后,最后面能不能成功,就是我需要去计算在这个状态下,我选择了这个动作,后续能够一共拿到多少总收益。如果可以预估未来的总收益的大小,我们当然知道在当前的这个状态下选择哪个动作,价值更高。我选择某个动作是因为我未来可以拿到的那个价值会更高一点。所以强化学习的目标导向性很强,环境给出的奖励是一个非常重要的反馈,它就是根据环境的奖励来去做选择。
参考资料
https://linklearner.com/datawhale-homepage/#/learn/detail/91
https://baike.baidu.com/item/%E9%A9%AC%E5%B0%94%E5%8F%AF%E5%A4%AB%E5%86%B3%E7%AD%96%E8%BF%87%E7%A8%8B/5824810?fr=kg_general

















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









