







1、过拟合和欠拟合
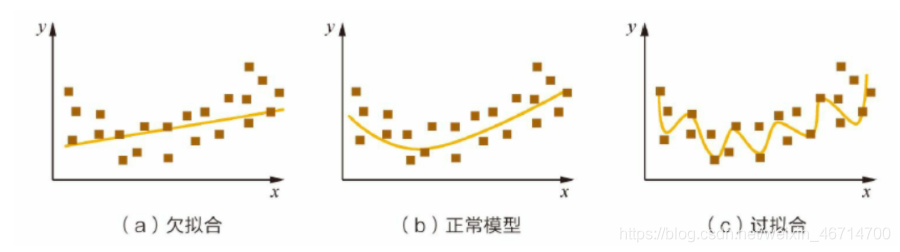
可以看出,图(a)是欠拟合的情况,拟合的黄线没有很好地捕捉到数据的特征,不能够很好地拟合数据。图(c)则是过拟合的情况,模型过于复杂,把噪声数据的特征也学习到模型中,导致模型泛化能力下降,在后期应用过程中很容易输出错误的预测结果。
过拟合是指模型对于训练数据拟合呈过当的情况,反映到评估指标上,就是模型在训练集上的表现很好,但在测试集和新数据上的表现较差。欠拟合指的是模型在训练和预测时表现都不好的情况。
2、泛化误差、偏差和方差
模型调优,第一步是要找准目标:我们要做什么?一般来说,这个目标是提升某个模型评估指标,比如对于随机森林来说,我们想要提升的是模型在未知数据上的准确率(由score或oob_score_来衡量)。找准了这个目标,我们就需要思考:模型在未知数据上的准确率受什么因素影响?常用来衡量模型在未知数据上的准确率的指标,叫做泛化误差(Genelization error)。
泛化误差
当模型在未知数据(测试集或者袋外数据)上表现糟糕时,我们说模型的泛化程度不够,泛化误差大,模型的效果不好。泛化误差受到模型的结构(复杂度)影响
有四点需要注意的: 1)模型太复杂或者太简单,都会让泛化误差高,我们追求的是位于中间的平衡点 2)模型太复杂就会过拟合,模型太简单就会欠拟合 3)对树模型和树的集成模型来说,树的深度越深,枝叶越多,模型越复杂 4)树模型和树的集成模型的目标,都是减少模型复杂度,把模型往图像的左边移动
偏差和方差
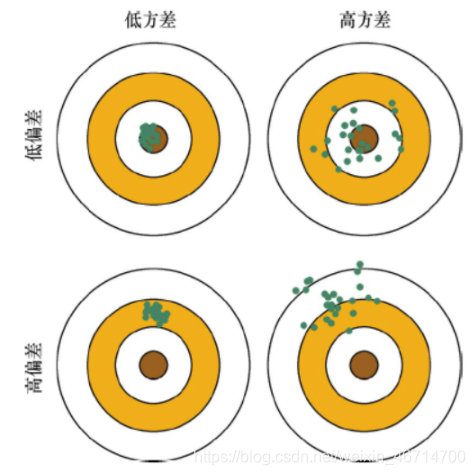
用过拟合、欠拟合来定性地描述模型是否很好地解决了特定的问题。从定量的角度来说,可以用模型的偏差(Bias)与方差(Variance)来描述模型的性能。
为了更清晰的理解偏差和方差,可以用一个射击的例子来进一步描述这二者的区别和联系。假设一次射击就是一个机器学习模型对一个样本进行预测。射中靶心位置代表预测准确,偏离靶心越远代表预测误差越大。 我们通过n次采样得到n个大小为m的训练样本集合,训练出n个模型,对同一个样本做预测,相当于我们做了n次射击,射击结果如下图所示。我们最期望的结果就是左上角的结果,射击结果又准确又集中,说明模型的偏差和方差都很小;右上图虽然射击结果的中心在靶心周围,但分布比较分散,说明模型的偏差较小但方差较大;同理,左下图说明模型方差较小,偏差较大;右下图说明模型方差较大,偏差也较大。
3、模型评估
在机器学习中,我们通常把样本分为训练集和测试集,训练集用于训练模型,测试集用于评估模型。在样本划分和模型验证的过程中,存在着不同的抽样方法和验证方法。我们应当熟知这些方法及其优缺点、以便能够在不同问题中挑选合适的评估方法。
Holdout检验
Holdout 检验是最简单也是最直接的验证方法,它将原始的样本集合随机划分成训练集和验证集两部分。比方说,对于一个预测模型,我们把样本按照70%~30% 的比例分成两部分,70% 的样本用于模型训练;30% 的样本用于模型验证,包括绘制ROC曲线、计算精确率和召回率等指标来评估模型性能。
交叉检验
k-fold交叉验证
k-fold交叉验证:首先将全部样本划分成k个大小相等的样本子集;依次遍历这k个子集,每次把当前子集作为验证集,其余所有子集作为训练集,进行模型的训练和评估;最后把k次评估指标的平均值作为最终的评估指标。在实际实验中,k经常取10。
留一验证
每次留下1个样本作为验证集,其余所有样本作为测试集。样本总数为n,依次对n个样本进行遍历,进行n次验证,再将评估指标求平均值得到最终的评估指标。在样本总数较多的情况下,留一验证法的时间开销极大。事实上,留一验证是留p验证的特例。留p验证是每次留下p个样本作为验证集,而从n个元素中选择p个元素有 C n p C_{n}^{p} Cnp种可能,因此它的时间开销更是远远高于留一验证,故而很少在实际工程中被应用。
自助法
不管是Holdout检验还是交叉检验,都是基于划分训练集和测试集的方法进行模型评估的。然而,当样本规模比较小时,将样本集进行划分会让训练集进一步减小,这可能会影响模型训练效果。有没有能维持训练集样本规模的验证方法呢?自助法可以比较好地解决这个问题。 自助法是基于自助采样法的检验方法。对于总数为n的样本集合,进行n次有放回的随机抽样,得到大小为n的训练集。n次采样过程中,有的样本会被重复采样,有的样本没有被抽出过,将这些没有被抽出的样本作为验集,进行模型验证,这就是自助法的验证过程。
4、集成学习
面对一个机器学习问题,通常有两种策略。一种是研发人员尝试各种模型,选择其中表现最好的模型做重点调参优化。这种策略类似于奥运会比赛,通过强强竞争来选拔最优的运动员,并逐步提高成绩。另一种重要的策略是集各家之长,如同贤明的君主广泛地听取众多谋臣的建议,然后综合考虑,得到最终决策。后一种策略的核心,是将多个分类器的结果统一成一个最终的决策。使用这类策略的机器学习方法统称为集成学习。
Boosting
Boosting方法训练基分类器时采用串行的方式,各个基分类器之间有依赖。它的基本思路是将基分类器层层叠加,每一层在训练的时候,对前一层基分类器分错的样本,给予更高的权重。测试时,根据各层分类器的结果的加权得到最终结果。 Boosting的过程很类似于人类学习的过程,我们学习新知识的过程往往是迭代式的,第一遍学习的时候,我们会记住一部分知识,但往往也会犯一些错误,对于这些错误,我们的印象会很深。第二遍学习的时候,就会针对犯过错误的知识加强学习,以减少类似的错误发生。不断循环往复,直到犯错误的次数减少到很低的程度。
Bagging
Bagging与Boosting的串行训练方式不同,Bagging方法在训练过程中,各基分类器之间无强依赖,可以进行并行训练。其中很著名的算法之一是基于决策树基分类器的随机森林(Random Forest)。为了让基分类器之间互相独立,将训练集分为若干子集(当训练样本数量较少时,子集之间可能有交叠)。Bagging方法更像是一个集体决策的过程,每个个体都进行单独学习,学习的内容可以相同,也可以不同,也可以部分重叠。但由于个体之间存在差异性,最终做出的判断不会完全一致。在最终做决策时,每个个体单独作出判断,再通过投票的方式做出最 后的集体决策。
集成学习的步骤
集成学习一般可分为以下3个步骤。 (1)找到误差互相独立的基分类器。 (2)训练基分类器。 (3)合并基分类器的结果。
从减小方差和偏差的角度解释Boosting和Bagging
Bagging能够提高弱分类器性能的原因是降低了方差,Boosting能够提升弱分类器性能的原因是降低了偏差。首先,Bagging 是 Bootstrap Aggregating 的简称,意思就是再抽样,然后在每个样本上训练出来的模型取平均。
假设有n个随机变量,方差记为 σ 2 σ^2 σ2,两两变量之间的相关性为 ρ ρ ρ,则n个随机变量的均值的方差为。在随机变量完全独立的情况下,n个随机变量的方差为 σ 2 / n σ^2/n σ2/n,也就是说方差减小到了原来的1/n。再从模型的角度理解这个问题,对n个独立不相关的模型的预测结果取平均,方差是原来单个模型的1/n。这个描述不甚严谨,但原理已经讲得很清楚了。当然,模型之间不可能完全独立。为了追求模型的独立性,诸多Bagging的方法做了不同的改进。比如在随机森林算法中,每次选取节点分裂属性时,会随机抽取一个属性子集,而不是从所有属性中选取最优属性,这就是为了避免弱分类器之间过强的相关性。通过训练集的重采样也能够带来弱分类器之间的一定独立性,从 而降低Bagging后模型的方差。再看Boosting,大家应该还记得Boosting的训练过程。在训练好一个弱分类器后,我们需要计算弱分类器的错误或者残差,作为下一个分类器的输入。这个过程本身就是在不断减小损失函数,来使模型不断逼近“靶心”,使得模型偏差不断降低。但Boosting的过程并不会显著降低方差。这是因为Boosting的训练过程使得各弱分类器之间是强相关的,缺乏独立性,所以并不会对降低方差有作用。关于泛化误差、偏差、方差和模型复杂度的关系如下图所示。不难看出,方差和偏差是相辅相成,矛盾又统一的,二者并不能完全独立的存在。对于给定的学习任务和训练数据集,我们需要对模型的复杂度做合理的假设。如果模型复杂度过低,虽然方差很小,但是偏差会很高;如果模型复杂度过高,虽然偏差降低了,但是方差会很高。所以需要综合考虑偏差和方差选择合适复杂度的模型进行训练。
5、反思
实际操作中,是根据实际情况进行调整,同时查相关资料进行优化,根据数据情况再进行调整

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









