







目录
前言
🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客🍖 原作者:[K同学啊](https://mtyjkh.blog.youkuaiyun.com/)
说在前面
本周学习目标:了解并研究DenseNet与ResNetV的区别(拔高:根据pytorch代码编写相应的Tensflow代码、改进思路是否可以迁移到其它地方呢?)
我的环境:Python3.8、Pycharm2020、torch1.12.1+cu113
数据来源:[K同学啊](https://mtyjkh.blog.youkuaiyun.com/)
一、DenseNet模型介绍
1.1 背景
在计算机视觉领域,卷积神经网络(CNN)已经成为最主流的方法,从CNN的发展史来看(见第11周:ResNet-50算法实战与解析(Pytorch实现)_resnet50原文-优快云博客)RestNet模型的出现是一个里程碑事件,ResNet可以训练出更深的CNN模型,从而实现更高的准确度。
ResNet模型的核心是通过建立前面层与后面层之间的短路连接(shortcuts,skip connection),进而训练出更深的CNN网络;DenseNet模型基本思路和ResNet一致,但其建立的是前面所有层与后面层的密集连接,DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用。对比两者来看,DenseNet在参数和计算成本更少的情境下可以实现比ResNet更优的性能。
DenseNet论文原文——Densely Connected Convolutional Networks
1.2 设计理念
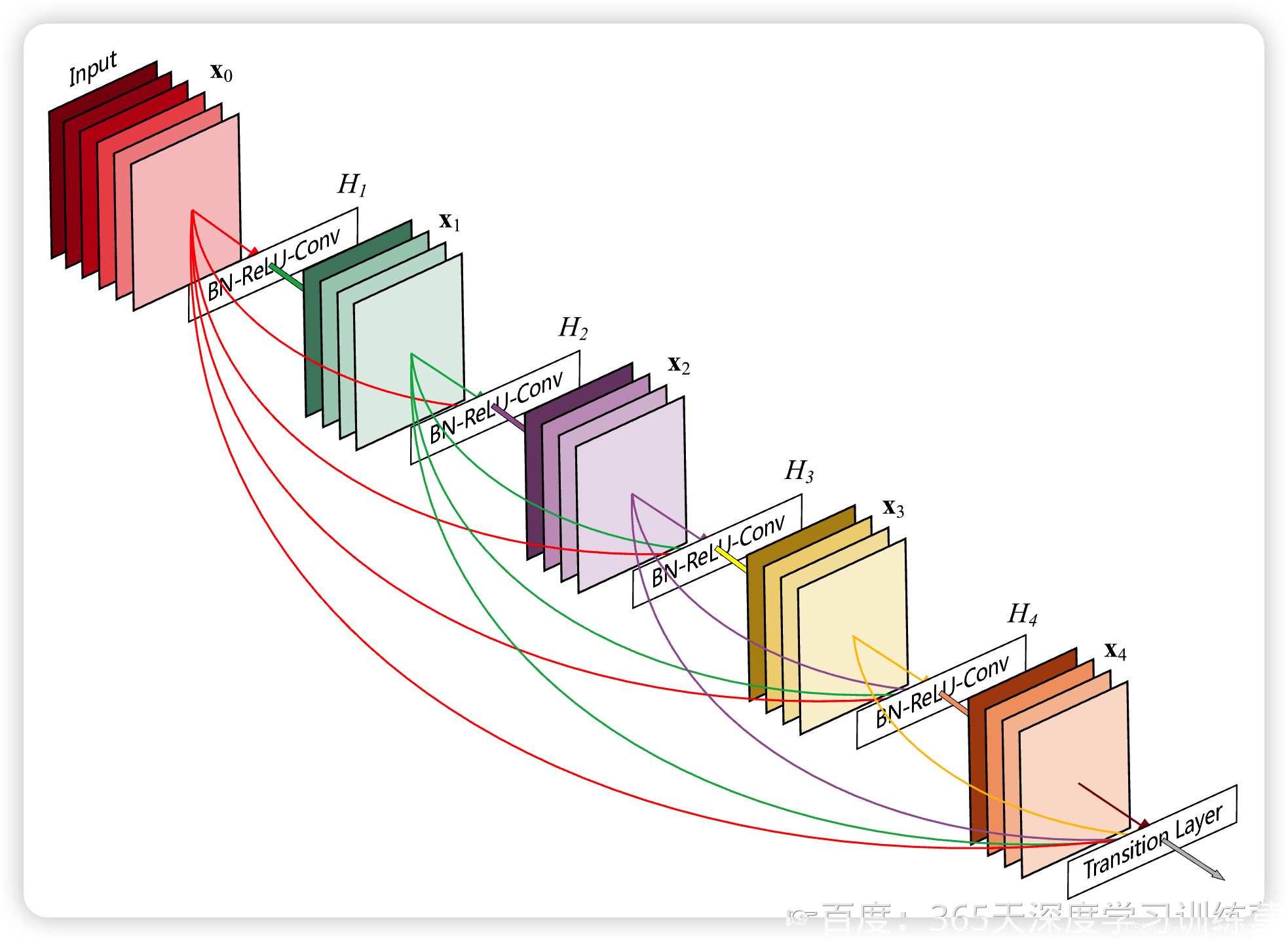
相比于ResNet,DenseNet提出了一个更激进的密集连接机制——互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。
ResNet网络的残差连接机制见图1,对比图2中DenseNet的密集连接机制,可以看出ResNet是每个层与前面的某层(一般是2~4层)短路连接在一起,连接的方式是通过元素相加;但是在DenseNet中,每个层都会与前面所有层在channel维度连接(concat)在一起,是通过元素叠加,并作为下一层的输入。
对于一个L层的网络,DenseNet共包含L(L+1)/2个连接,相比于RestNet,这是一种密集连接,而且DenseNet是直接concat来自不同层的特征图,进而可以实现特征重用,提升效率,这是两者最主要的区别。
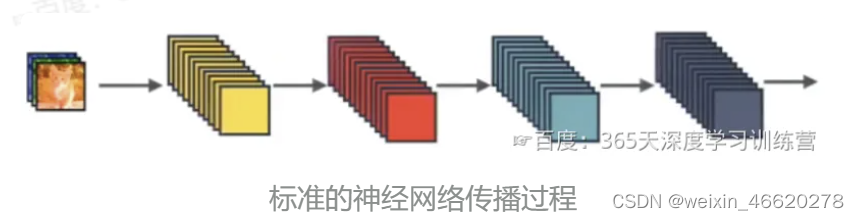
对于标准神经网络的传播过程,输入和输出的公式是,其中
是一个组合函数,通常包括BN、ReLu、Pooling、Conv操作,
是第l层输入的特征图,
是第l层输出的特征图
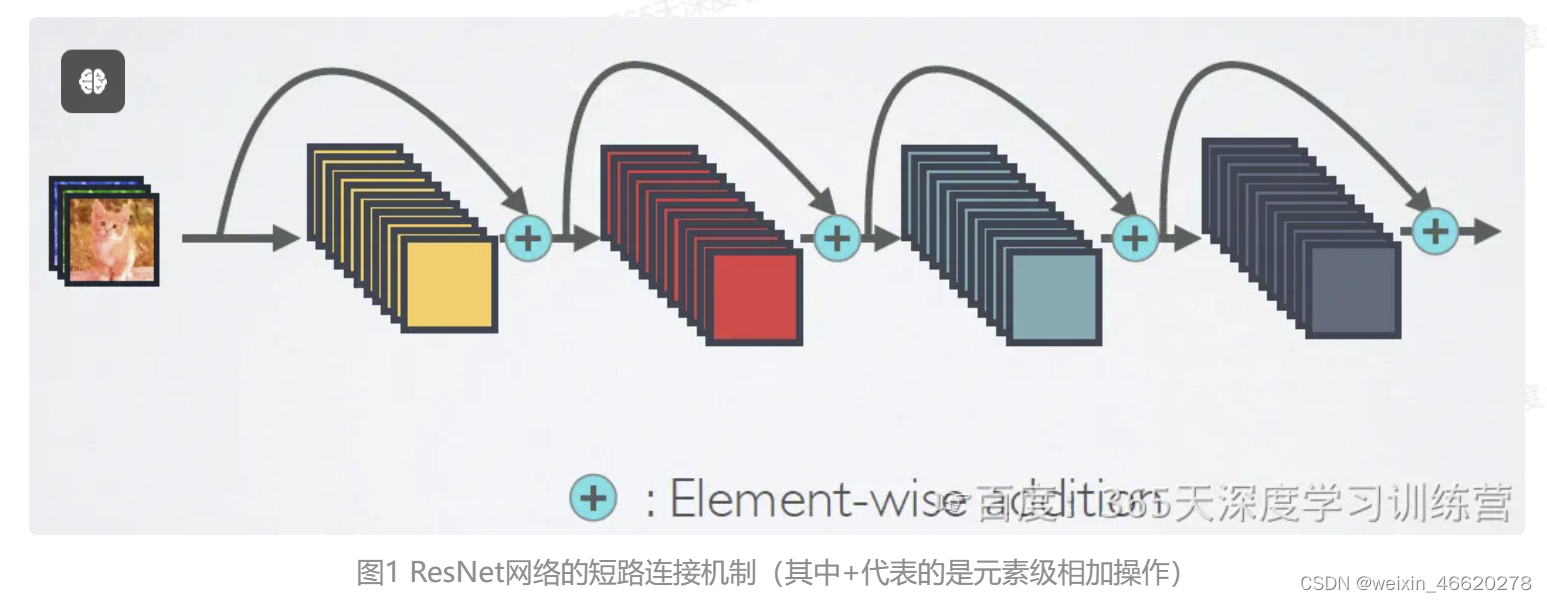
ResNet是跨层相加,输入和输出的公式是
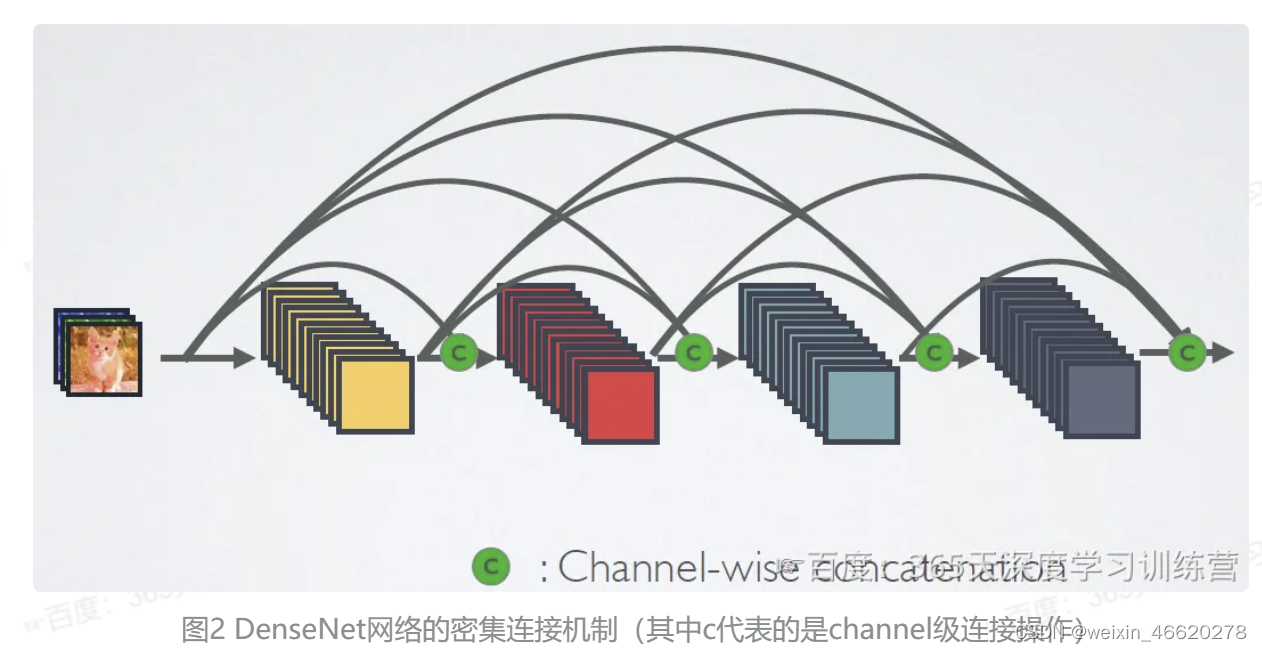
DenseNet采用的跨通道concat的形式来连接,会连接前面所有层作为输入,输入和输出的公式是,要注意的是所有的层的输入都来源于前面所有层在channel维度的concat
1.3 网络结构
DenseNet详细的网络图和实现细节见下图4
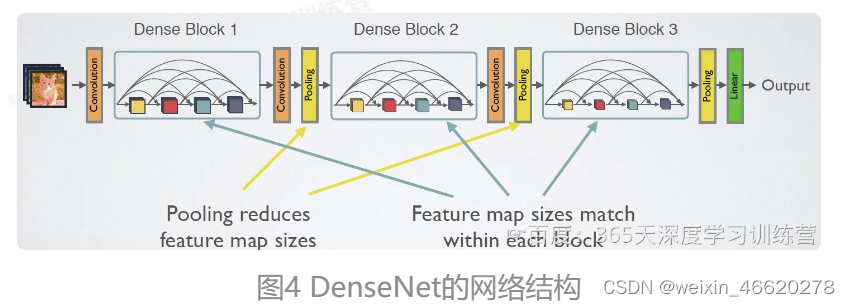
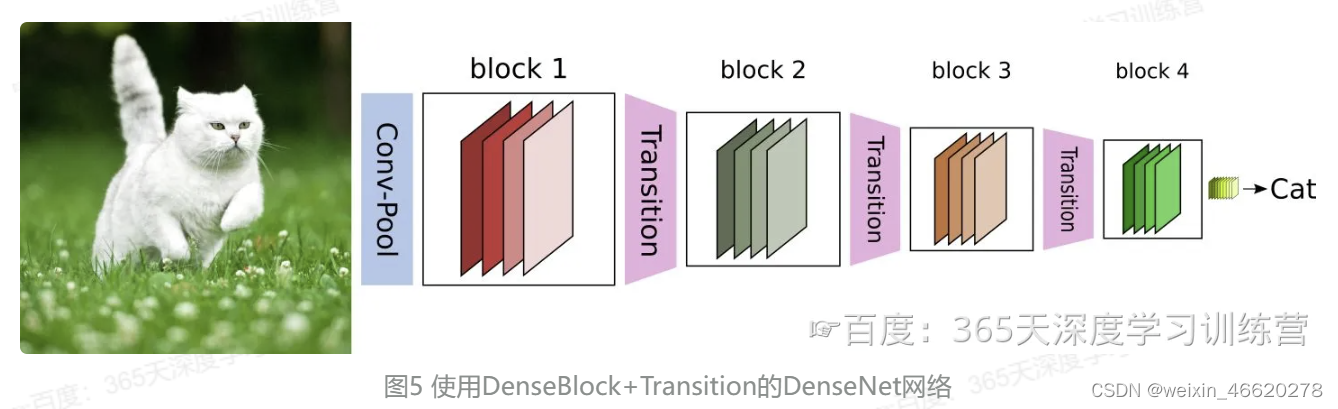
CNN网络一般要经过Pooling或者stride>1的Conv来降低特征图的大小,而DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition层是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。图5给出了DenseNet的网路结构,它共包含4个DenseBlock,各个DenseBlock之间通过Transition层连接在一起。
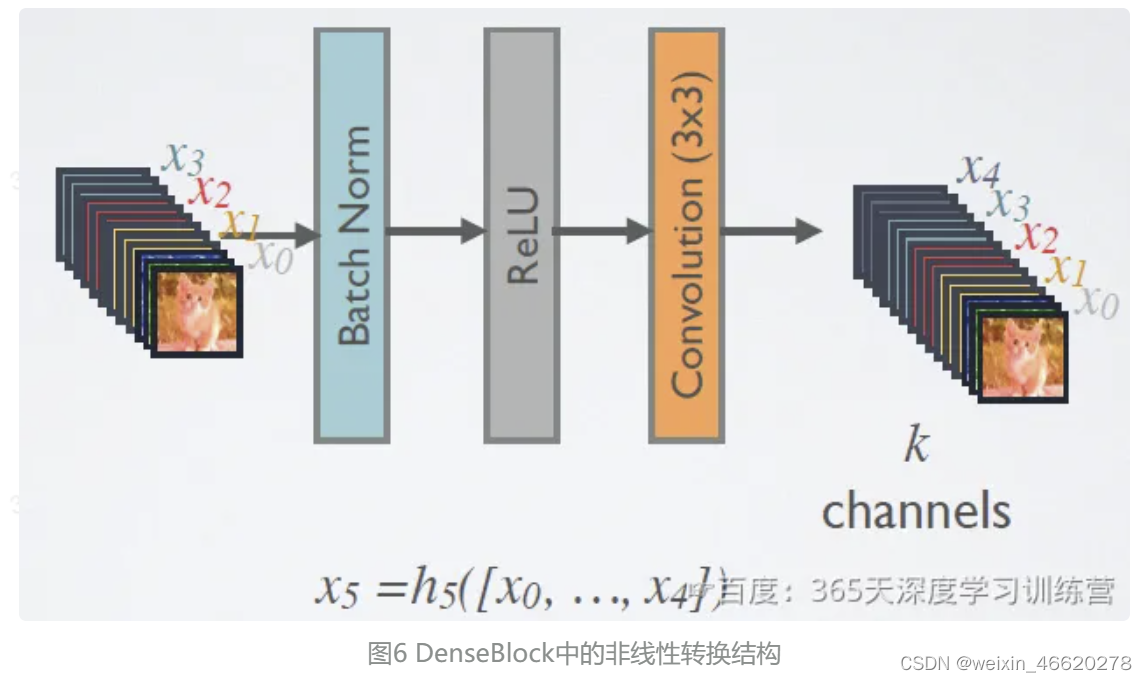
在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。DenseBlock中的非线性组合函数 H(·)的是 BN+ReLU+3x3 Conv 的结构,如图6所示。另外值得注意的一点是,与ResNet不同,所有DenseBlock中各个层卷积之后均输出 k个特征图,即得到的特征图的channel数为 k,或者说采用 k 个卷积核。 k 在DenseNet称为growth rate,这是一个超参数。一般情况下使用较小的 k(比如12),就可以得到较佳的性能。假定输入层的特征图的channel数为 ,那么l层输入的channel数为
,因此随着层数增加,尽管
设定得较小,DenseBlock的输入会非常多,不过这是由于特征重用所造成的,每个层仅有 k个特征是自己独有的。
由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量,主要是原有的结构中增加1x1Conv,如图7所示,即BN+ReLU+1x1Conv+BN+ReLU+3x3Conv,称为DenseNet-B结构。其中1x1 Conv得到 4k 个特征图它起到的作用是降低特征数量,从而提升计算效率。
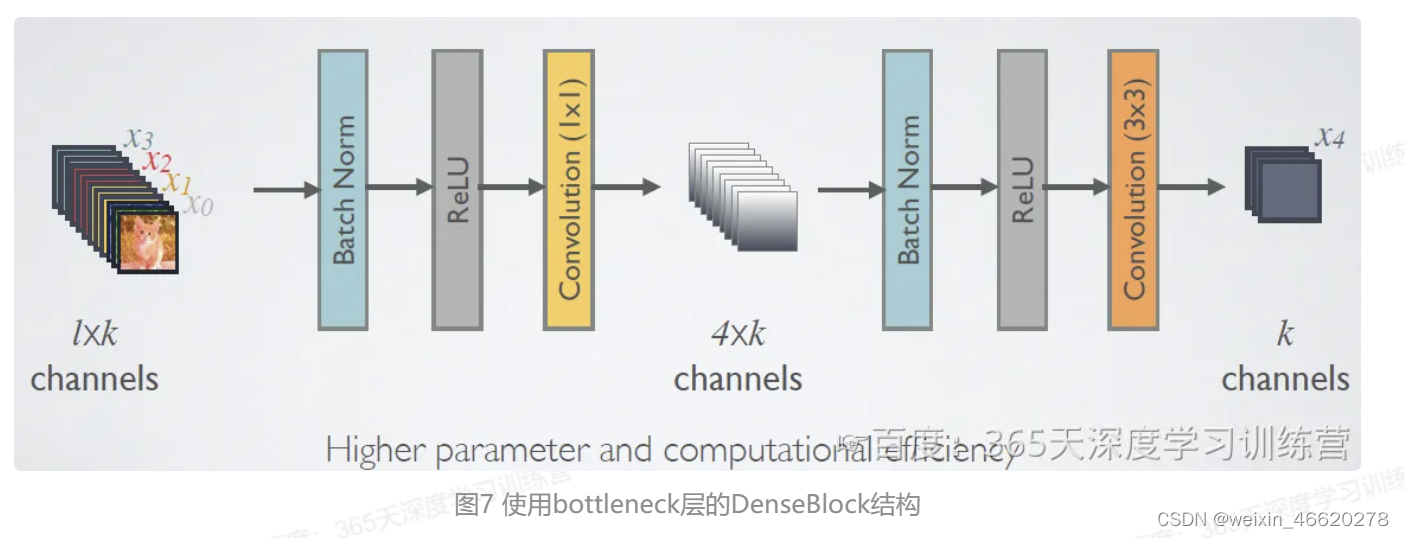
对于Transition层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1Conv&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 29万+
29万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









