




目录
关于Ubuntu系统中.config文件夹如何找到
Ubuntu中QT项目使用了setting保存配置,但是找不到配置文件保存了在哪里,找了一下:
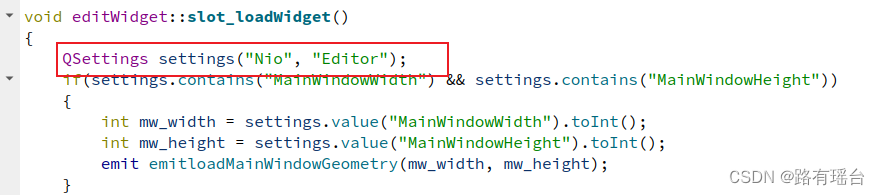
因为QT里取的名字是:
于是下载everything搜索Nio,发现目录为/home/nio/.config
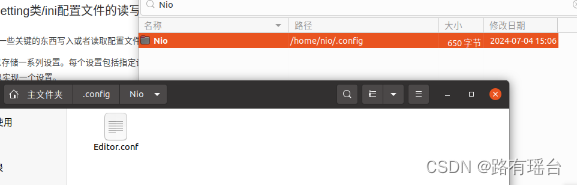
虽然已经下载了everything找到了,但是发现在文件夹下还是看不见。
来到 看不见.config那个文件夹的目录下,按ctrl+H就看见了!
补充一下看到的别的OS系统可能会存放的路径,以我的命名方式举例,
在 Windows 系统上,默认配置文件位置为:
%APPDATA%\Nio\Editor.ini
在 Linux 系统上,默认配置文件位置为:
~/.config/Nio/Editor.ini
在 macOS 系统上,默认配置文件位置为:
~/Library/Application Support/Nio/Editor.ini
在代码中,配置文件的读取和写入使用以下代码:
QSettings settings("Nio", "Editor");
Nio 是组织名称,Editor 是应用程序名称。配置文件的名称为 Editor.ini。
在Ubuntu上安装deb软件两种方式
dpkg
用于在基于 Debian 的 Linux 发行版(如 Ubuntu)上安装 Debian 软件包(.deb 文件)的命令。这里的 dpkg 是 Debian Package Manager 的缩写,它是用于处理 Debian 软件包的主要工具。
简记:打跑考官(绝对因为不是面试的太多
sudo dpkg -i xxxx.deb # 以 root 用户的权限使用 dpkg 安装指定的 .deb 软件包文件。
dpkg -i package.deb # 安装一个 Debian 软件包,如手动下载的文件。
dpkg -c package.deb # 列出 package.deb 的内容。
dpkg -I package.deb # 从 package.deb 中提取包信息。
dpkg -r package # 移除一个已安装的包。
dpkg -P package # 完全清除一个已安装的包。和 remove 不同的是,remove 只是删掉数据和可执行文件,purge 另外还删除所有的配制文件。
dpkg -L package # 列出 package 安装的所有文件清单。
dpkg -s package # 显示已安装包的信息。
dpkg -reconfigure package # 重新配制一个已经安装的包,如果它使用的是 debconf (debconf 为包安装提供了一个统一的配置界面)。
dpkg -S package # 查看软件在哪个包里
具体来说:
sudo:这是一个命令,允许授权用户以超级用户(或称为 root 用户)的权限执行命令。这是必要的,因为安装软件包通常需要写入系统目录,这些目录通常只有 root 用户才能写入。dpkg:这是 Debian 的软件包管理工具。-i:这是dpkg命令的一个选项,代表“install”或“安装”。
apt
Advanced Packaging Tool(apt)是Linux下的一款安装包管理工具,是一个客户/服务器系统。
与dpkg的区别就是,dpkg用于下载本地的deb包,而apt可以在线下载
sudo apt-get install # package 安装包
sudo apt-get reinstall # package - - reinstall 重新安装包
sudo apt-get remove # package 删除包
sudo apt-get remove --purge # package 删除包,包括删除配置文件等
sudo apt-get autoremove --purge # package 删除包及其依赖的软件包配置文件等
sudo apt-get update # 更新源
sudo apt-get upgrade # 更新已安装的包
sudo apt-get dist-upgrade # 升级系统
apt和apt-get命令的区别
apt 命令的引入就是为了解决命令过于分散的问题,它包括了 apt-get 命令出现以来使用最广泛的功能选项,以及 apt-cache 和 apt-config 命令中很少用到的功能。
在使用 apt 命令时,用户不必再由 apt-get 转到 apt-cache 或 apt-config,而且 apt 更加结构化,并为用户提供了管理软件包所需的必要选项。
简单来说就是:apt = apt-get、apt-cache 和 apt-config 中最常用命令选项的集合。
虽然 apt 与 apt-get 有一些类似的命令选项,但它并不能完全向下兼容 apt-get 命令。也就是说,可以用 apt 替换部分 apt-get 系列命令,但不是全部。
| apt 命令 | 取代的命令 | 命令的功能 |
| apt install | apt-get install | 安装软件包 |
| apt remove | apt-get remove | 移除软件包 |
| apt purge | apt-get purge | 移除软件包及配置文件 |
| apt update | apt-get update | 刷新存储库索引 |
| apt upgrade | apt-get upgrade | 升级所有可升级的软件包 |
| apt autoremove | apt-get autoremove | 自动删除不需要的包 |
| apt full-upgrade | apt-get dist-upgrade | 在升级软件包时自动处理依赖关系 |
| apt search | apt-cache search | 搜索应用程序 |
| apt show | apt-cache show | 显示装细节 |
关于Ubuntu如何使用docker
以下是近期下载docker使用到的全部命令:
apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common //获取
sudo apt-get install \
ca-certificates \
curl \
gnupg \
lsb-release
//更新apt镜像
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
//添加阿里云镜像
sudo add-apt-repository \
"deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu \
$(lsb_release -cs) \
stable"
//设置阿里云镜像源仓库
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
//更新apt源
//安装 Docker 引擎
sudo systemctl status docker
//检查docker是否正在运行
sudo systemctl start docker
//如果没有运行,启动
//也可以重启,重新加载某个服务的配置文件
sudo systemctl daemon-reload
sudo systemctl restart docker
//加入docker组,允许特定用户在不使用 sudo 密码的情况下运行 Docker 命令
sudo usermod -aG docker your_username
//username改成自己
whoami
//查看是否加入docker组
groups
docker version
//查看版本看是否正常
//在/etc/docker文件夹下执行:
sudo touch daemon.json
//修改/etc/docker/daemon.json 文件权限
chmod 777 daemon.json
//修改/etc/docker/daemon.json文件
sudo vim /etc/docker/daemon.json
//添加国内源,按insert
{
"registry-mirrors": ["https://alzgoonw.mirror.aliyuncs.com"]
}
//按esc,输入:wq!返回
systemctl restart docker
systemctl status docker
//输入hellowolrd验证
docker run hello-world
如何查看ubuntu下的环境变量
1.查看所有环境变量:printenv / env
2.查看特定的环境变量,例如PATH:echo $PATH
下载QT5.8安装包-bestswinger课程
最近在看UP的QT开发课,真的找了巨久这个安装包,谁都不想在安装上花太多时间。。出一版小小教程吧~
首先打开qt download官网,5.8好像在镜像网站上没有看到,所以我最后还是老老实实官网了,而且5.8会小一点
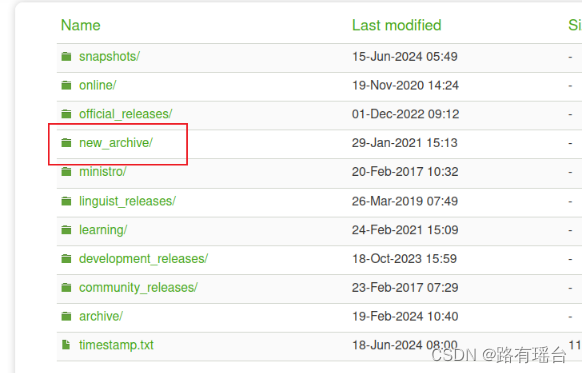
选择new_archive/
点击qt
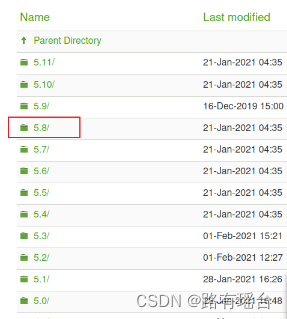
选择5.8
找到linux-5.8.0.run,这个才766M,不大不大,大概一个小时妥妥完事

然后打开终端,进入.run文件所在目录。
第一步,赋权限:
sudo chmod -R 777 qt-opensource-linux-5.8.0.run
第二步,安装QT:
./qt-opensource-linux-5.8.0.run
第三步,根据弹窗安装。
弹窗后续安装方法,跳转ubuntu 安装 QT 【亲测有效】_ubuntu安装qt-优快云博客
如果不注重版本可以参考最新QT下载和安装 指南教程 - 程序员大本营,这里介绍了使用镜像和迅雷下载方法。
在Ubuntu上面运行QT打包程序,出现一些问题报错
ERROR:ldd outputLine:“libprotobuf.so.28 => not found“
想要在Ubuntu上面运行QT打包程序,出现一些问题报错:
ERROR:ldd outputLine:"libprotobuf.so.28 => not found"
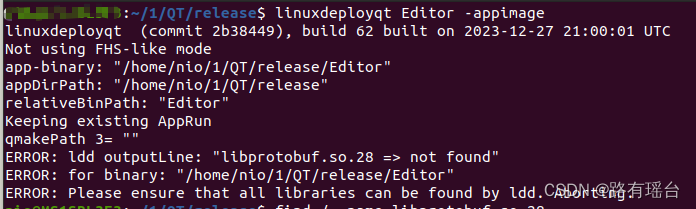
首先确定一下libprotobuf.so.28的位置:

然后建立一个软链接:
ln -s /xxx/xxx/xx.so /usr/lib/xx.so
# /xxx/xxx/xx.so即上图确定的so地址,软链接到/usr/lib/xx.so

最终没有ldd的错误了


















 8140
8140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









