










机器学习中的导数和梯度(学习笔记)
博主将会在本文中把对于导数和梯度在机器学习中的意义和应用的理解做一个整理并供大家参考,欢迎批评指正!文章总体结构: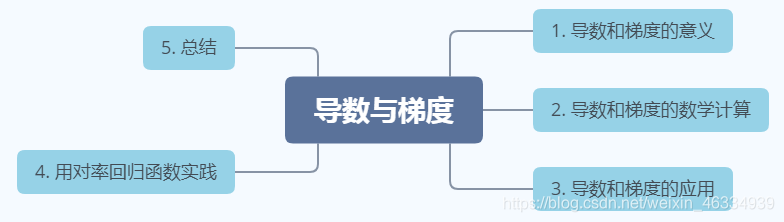
传播搞机的快乐,分享计算机知识!—TCJ
1.导数和梯度的意义
1.1导数:
导数(derivative)是微积分的重要概念,设函数 y = f(x) 在点 x0 的某个领域内有定义,当自变量 x 在 x0 的某个邻域内有定义 ,当自变量 x 在 x0 的处取得增量 △x 时,相应的函数 y 将取得增量 △y ;如果 △y 与 △x 之比在 △x → 0 时存在极限,则称函数 y = f(x) 在点 x0 处可导,并称这个极限为函数 y = f(x) 在点 x0 的导数。
这个定义是不是有点像在物理上求瞬时速度?
v = s / t ;当 t → 0 时, v 可看作在某一时刻的瞬时速度。
在几何上,导数可看作是函数在某一点的切线的斜率。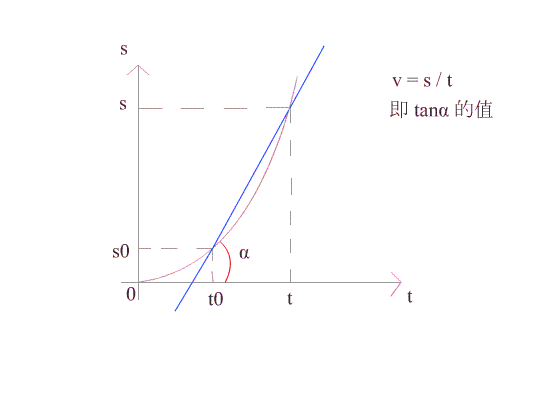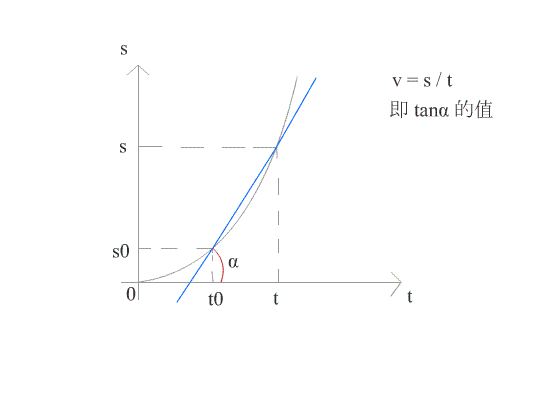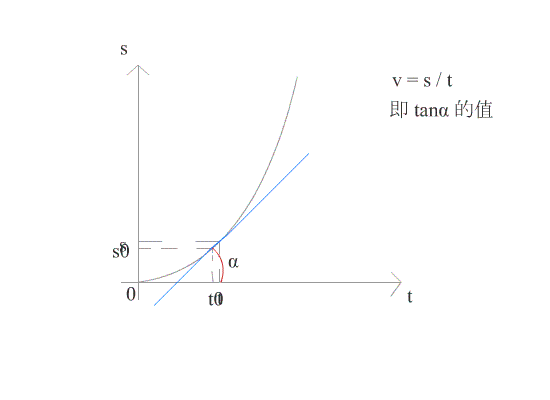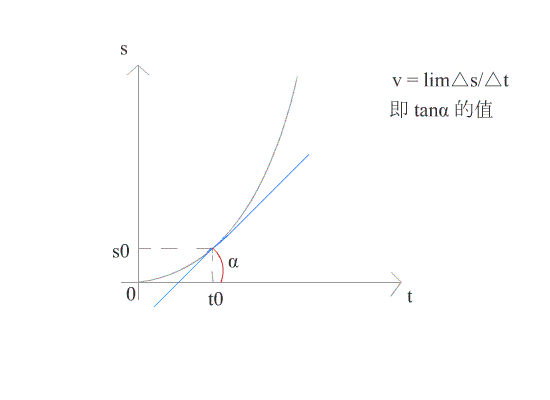
如图所示,当 △t 趋近于 0 时,导数就是函数 f(x) 在 t0 点的切线。此时可求得在时刻 t0 时的瞬时速度。
1.2梯度:
梯度(gradient)是一个向量,它既有方向又有大小,它的方向是某一函数在某点处变化率最大的方向,此时它的大小就是变化率。
我们假设一个场景:现在有一个宝箱,放在山顶最高处,山下有三队人马同时开始上山,向宝箱进发
注明:我们假设此处最快到达最高处的队伍获胜,而不去考虑实际的路程等。也就是和宝箱处于同一高度即可,不去管他们之间的水平距离。
显然,他们需要对当前所处位置做一个判断,找出走最少的路上升最大的高度的方向。然后沿着这个方向走几步,再判断方向,再走几步,以此类推,直到走到最高处。
类似的,梯度就是这个方向,山就是某个函数,宝箱所处位置就是函数的最高点,三队人马是除最高点外的其它任意三个函数上的点。可以看出,梯度的方向就是函数在某点变化率最大的方向,有了它的帮助,可找到函数的最高点或最低点。
1.3小结:
导数在几何上可看作某一函数上在某一点的切线的斜率,
对于单个自变量的函数,
导数就是该点的梯度。
对于多个自变量的函数,
我们对每个自变量都进行求导,
梯度就是每个导数所组成的向量。
梯度方向是某一函数在某一点上的变化率最大的方向,由此进行迭代计算可找到函数的最值。
2.导数和梯度的数学计算
了解了导数的基本概念后,我们需要对它进行计算才能运用到实际。
从它的定义可知,
若我们已知某一物体的行进路程和时间可由图中的函数描述(此处近似看作函数 y = x*x , 方便讨论),
显然,t >= 0 ;且当 t = 0 时;函数值为 0 ,是该函数的最低点。
现在我们任取一时间点 t0 = 100,
用梯度下降的方法找到 路程的最小值 和 此时的时间 t1 ,
对于任一 t ( t>=0 ),求导得到:f ’(t) = 2t;过程如下
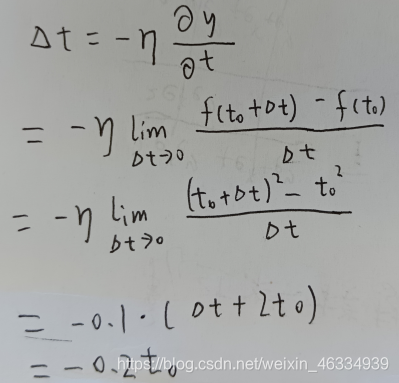
此处 μ 为每次更新的步长,取值 0.1,前面添加“ — ”号表示沿着负梯度方向(μ 若过大,可能会错过最低点;若过小,可能会迟迟找不到最低点)
我们让计算机来帮忙算一下
public class sec {
public static void main(String[] args) {
double rate = 0.1;
double t0 = 100;
int i = 0;
while (true){
i++;//记录迭代次数
double s = t0*t0;
t0 = t0 -2*rate*t0;
System.out.println("第"+i+"次迭代");
System.out.println("时间 : "+t0);
System.out.println("路程 : "+s);
}
}
}
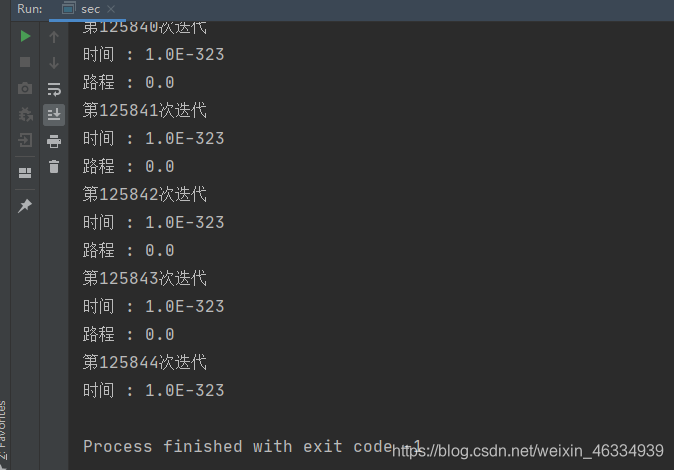
计算机瞬间就找到了最小路程为 0 ,时间为 1.0E-323(这里不是 0 是因为计算精度造成的,但可近似看作是 0)
当然,用梯度下降来求解此函数的最小值是没有现实意义的,更一般的,机器学习任务中的特征空间大多是多维的(即拥有多个自变量),下面让我们来讨论一下它在机器学习中的具体应用。
2.1知识点小结:
求导公式: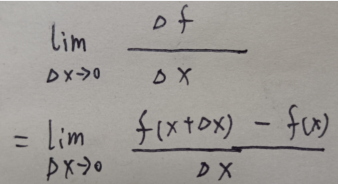
3.导数和梯度的应用
在机器学习任务中,我们一般会选择一个代价函数来描述学得的模型的输出与真实值之间的差距(即误差),并通过不断减小代价函数的值来优化模型。
例如:
常用的线性回归模型,
y = w * x + b,
用合适的代价函数描述误差,
E = (1/2)*Σ(f(x) – y)^2,(1/2 是为了抵销平方后的 2,对结果无影响)
试着减小它的误差,
对此进行求导,
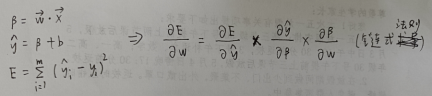
链式法则可有效降低求导复杂度
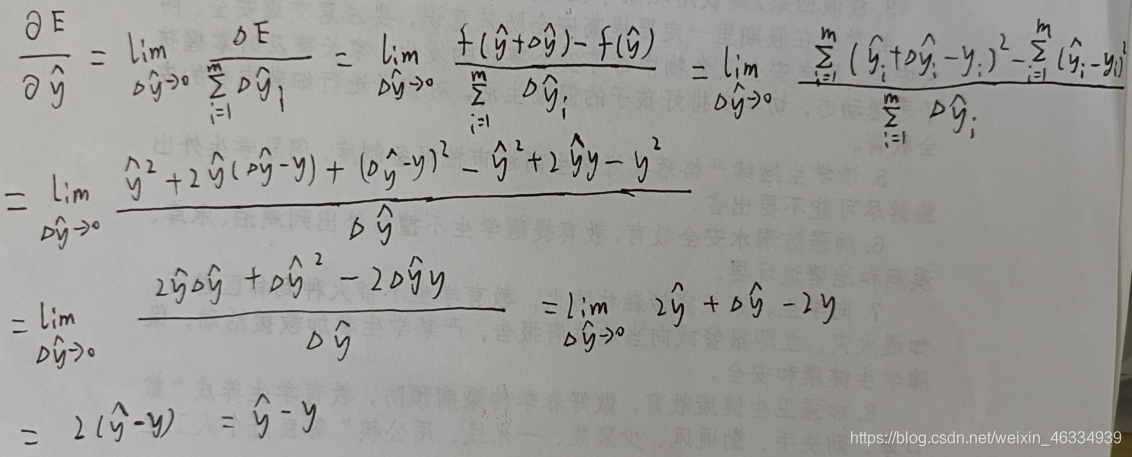

往梯度的反方向上适当前进,
△wi = – μ * xi * ( Y – y ) ,(Y 是模型的输出,y 是真实值,x 是输入的特征,μ是学习率)
同理可得,
△b = – μ * ( Yi – yi )
3.1小结:
导数和梯度在机器学习中有重要的应用,可以说是智能原理的核心。
常见的神经网络模型就是基于此的。
4.用对率回归函数实践
有了第三节的讨论,
我们可类似的对对率回归函数进行学习规则的推导,
y = 1/(1+e^-z ),
省略过程,
对 f(x) 求导得到,
f’(x) = f(x)*(1–f(x)),
仍用均方误差描述,
最终对于 z = w * x + b 中的 w 和 b,
其更新式为,
△wi = –μ * xi * Y * (1–Y) * (Y–y)
△b = –μ * Y * (1–Y) * (Y–y)
要进行机器学习,首先得要有数据,这里使用一个西瓜数据集(来源《机器学习》侵权即删),我们构造一个能分类西瓜好坏的学习模型。
并用留出法对原始数据进行处理,分为训练集和测试集
最后用错误率来评估模型性能
import java.util.ArrayList;
import java.util.List;
public class sigmoid {
/**
* 训练集:
* (正例,都是好瓜①密度 0.697 含糖率 0.460 ②密度 0.774 含糖率0.376 ③密度 0.634 含糖率 0.264
* ④密度 0.608 含糖率 0.318 ⑤密度 0.556 含糖率 0.215)
* (反例①密度 0.666 含糖率 0.091 ②密度 0.243 含糖率 0.267 ③密度 0.245 含糖率 0.057
* ④密度 0.343 含糖率 0.099 ⑤密度 0.639 含糖率 0.161 ⑥密度 0.657 含糖率 0.198
* )
* 测试集:
* (正例①密度 0.481 含糖率 0.149 ②密度 0.437 含糖率 0.211 ③密度 0.403 含糖率 0.237)
* (反例①密度 0.593 含糖率 0.042 ②密度 0.719 含糖率 0.103 ④密度 0.360 含糖率 0.370)
*/
public static void main(String[] args) throws InterruptedException {
List traindatas = new ArrayList();
List traindatass = new ArrayList();
List zresult = new ArrayList();
traindatas.add(0.697);
traindatass.add(0.460);
traindatas.add(0.774);
traindatass.add(0.376);
traindatas.add(0.634);
traindatass.add(0.264);
traindatas.add(0.608);
traindatass.add(0.318);
traindatas.add(0.556);
traindatass.add(0.215);
//正例↑
traindatas.add(0.666);
traindatass.add(0.091);
traindatas.add(0.243);
traindatass.add(0.267);
traindatas.add(0.245);
traindatass.add(0.057);
traindatas.add(0.343);
traindatass.add(0.099);
traindatas.add(0.639);
traindatass.add(0.161);
traindatas.add(0.657);
traindatass.add(0.198);
zresult.add(1);
zresult.add(1);
zresult.add(1);
zresult.add(1);
zresult.add(1);
zresult.add(0);
zresult.add(0);
zresult.add(0);
zresult.add(0);
zresult.add(0);
zresult.add(0);
List ftraindatas = new ArrayList();
List ftraindatass = new ArrayList();
List fzresult = new ArrayList();
ftraindatas.add(0.481);
ftraindatass.add(0.149);
ftraindatas.add(0.437);
ftraindatass.add(0.211);
ftraindatas.add(0.593);
ftraindatass.add(0.042);
ftraindatas.add(0.719);
ftraindatass.add(0.103);
ftraindatas.add(0.403);
ftraindatass.add(0.237);
ftraindatas.add(0.360);
ftraindatass.add(0.370);
fzresult.add(1);
fzresult.add(1);
fzresult.add(1);
fzresult.add(0);
fzresult.add(0);
fzresult.add(0);
float f = (float) ftraindatas.size() / (traindatas.size() + ftraindatas.size());
System.out.println("训练集数据比例:" + (1 - f));//此处为0.64
List ws = new ArrayList();
ws.add(0.8);//初始化权重
ws.add(0.1);
double b = 1;//初始化偏置项
double rate = 0.1;//学习率
for (int i = 0; i < 1000; i++) {//进行1000轮学习
int ii = i + 1;
System.out.println("第" + ii + "轮学习");
for (int j = 0; j < 11; j++) {
double x1 = Double.valueOf(traindatas.get(j).toString());
double x2 = Double.valueOf(traindatass.get(j).toString());
double y = Double.valueOf(zresult.get(j).toString());
double Y = 1 / (1 + Math.pow(Math.E, -(Double.valueOf(ws.get(0).toString()) * x1 + Double.valueOf(ws.get(1).toString()) * x2 + b)));
ws.set(0, Double.valueOf(ws.get(0).toString()) - rate * x1 * Y * (1 - Y) * (Y - y));
ws.set(1, Double.valueOf(ws.get(1).toString()) - rate * x2 * Y * (1 - Y) * (Y - y));
b = b - rate * Y * (1 - Y) * (Y - y);
System.out.println("w1:" + ws.get(0));
}
int c = 0;//记录错误个数
for (int k = 0; k < 6; k++) {//测试
double x1 = Double.valueOf(ftraindatas.get(k).toString());
double x2 = Double.valueOf(ftraindatass.get(k).toString());
double y = Double.valueOf(fzresult.get(k).toString());
double Y = 1 / (1 + Math.pow(Math.E, Double.valueOf(ws.get(0).toString()) * x1 + Double.valueOf(ws.get(1).toString()) * x2 + b));
if (Y > 0.5 & y == 1.0) {
} else if (Y < 0.5 & y == 0.0) {
} else {
c++;
System.out.println("第" + k + "个示例分类错误");
}
}
System.out.println("错误率" + c / 6.0);
}
}
}
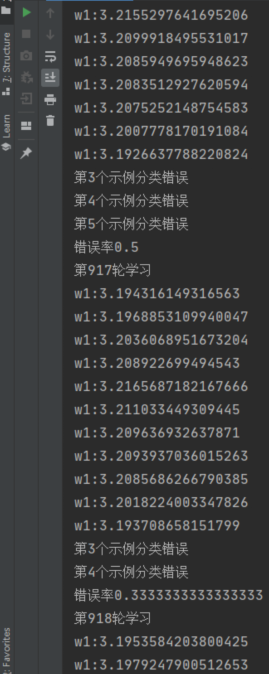
在进行了917次学习后,模型错误率从 0.5 降到了 0.33 ,有趣的是在第26轮学习后,错误率从0.5上升到了0.83,实际上,生活中的机器学习任务要比这复杂得多,往往还要考虑 过拟合、最优解 等。这也就是为什么此处错误率会上升的原因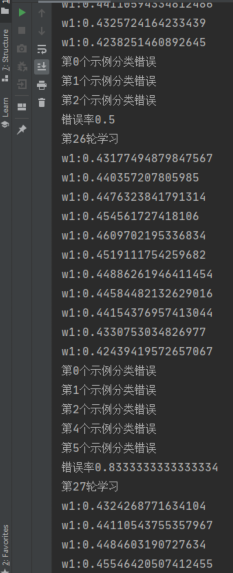
拿 w1 举例,w1 每次更新的值很小,只有多次训练才能找到一个局部最优解。
这里只是简单构建了一个分类模型,为了说明导数和梯度在机器学习中确实具有重要意义。
4.1小结:
对于一个学习模型,我们可用代价函数描述它的误差,通过求导找到此函数变化率最大的方向,让自变量(即要学习的参数)往此方向的反方向适当改变值即可优化模型的性能。这就是基于梯度下降法的学习。
5.总结
导数在几何上可看作函数在某一点的切线斜率(也是梯度),
该方向是变化率最大的方向,
导数计算公式为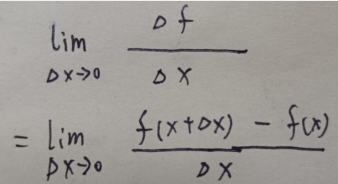 ,
,
基于此进行学习可得到最优参数,
这就是梯度下降法。
最后感谢优快云上同学分享的知识,谢谢!
笔记第二部分完成时间—2021/5/3 10:06
已同步更新至个人博客:田超杰的个人网站-一个传播计算机知识和人生哲理的博客


















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











