







Human-object interaction prediction in videos through gaze following
Abstract
The video-based HOI anticipation task in the third-person view is rarely researched. In this paper, a framework to detect current HOIs and anticipate future HOIs in videos is propose. Since people often fixate on an object before interacting with it, in this model gaze features together with the scene contexts and the visual appearances of human–object pairs are fused through a spatio-temporal transformer. Besides, a set of person-wise multi-label metrics are proposed to evaluate the model in the HOI anticipation task in a multi-person scenario.
Overview of the video-based HOI detection and anticipation framework.
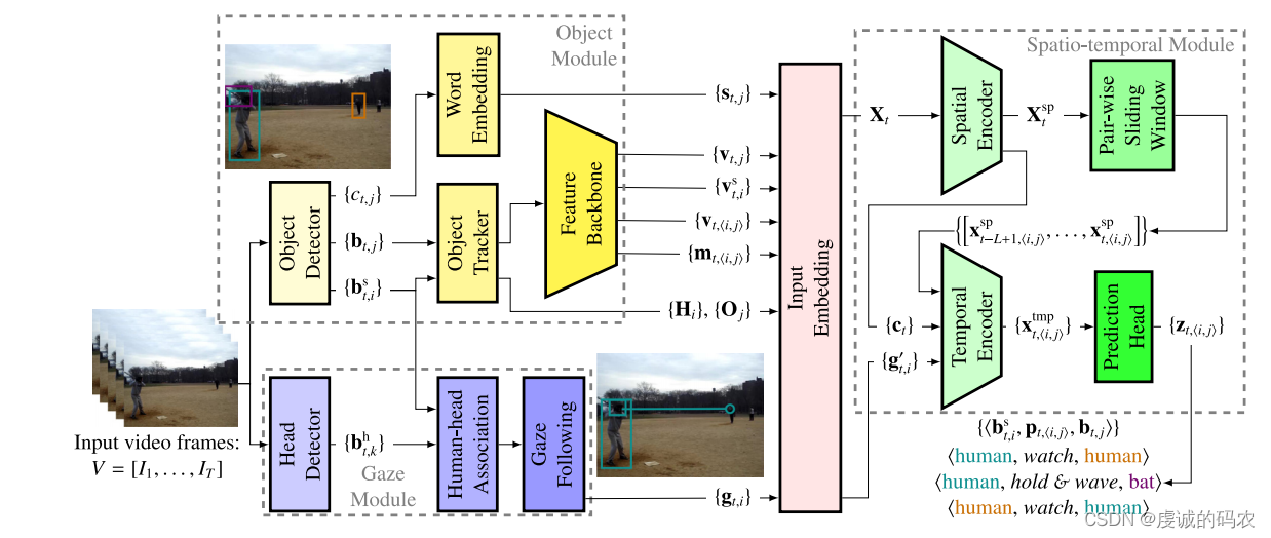
The framework consists of three modules:
- Object Module
- The object module detects bounding boxes of humans { b t , i s } \{b^s_{t,i}\} { bt,is} and objects { b t , j } \{b_{t,j}\} { bt,j}, and recognizes object classes { c t , j } \{c_{t,j}\} { ct,j}. An object tracker obtains human and object trajectories ( { H i } \{\textbf{H}_i\} { Hi} and { O j } \{\textbf{O}_j\} { Oj}in the video. Then, the human visual features { v t , i s } \{v^s_{t,i}\} { vt,is}, object visual features { v t , j } \{v_{t,j}\} { vt,j}, visual relation features { v t , < i , j > } \{v_{t,<i,j>}\} { vt,<i,j>}, and spatial relation features { m t , < i , j > } \{m_{t,<i,j>}\} { m
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1581
1581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









