







随机森林
1 概述
1.1 集成算法概述
集成学习(ensemble learning)是时下非常流行的机器学习算法,它本身不是一个单独的机器学习算法,而是通过在数据上构建多个模型,集成所有模型的建模结果。基本上所有的机器学习领域都可以看到集成学习的身影,在
现实中集成学习也有相当大的作用,它可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预测疾病的风险和病患者的易感性。在现在的各种算法竞赛中,随机森林,梯度提升树(GBDT),Xgboost等集成算法的身影也随处可见,可见其效果之好,应用之广。
集成算法的目标
集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合的结果,以此来获取比单个模型更好的回归或分类表现。
集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合的结果,以此来获取比单个模型更好的回归或 分类表现。
多个模型集成成为的模型叫做集成评估器(ensemble estimator),组成集成评估器的每个模型都叫做基评估器(base estimator)。通常来说,有三类集成算法:装袋法(Bagging),提升法(Boosting)和stacking。
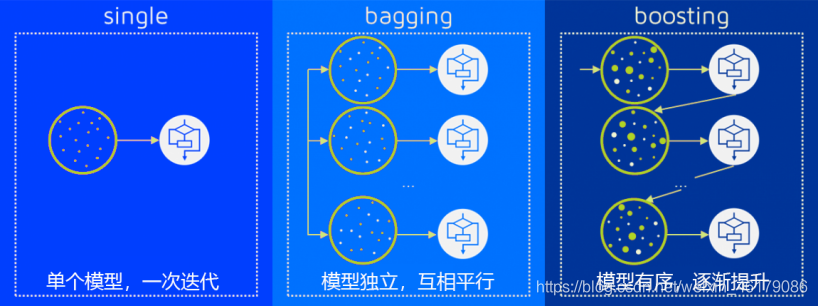
装袋法的核心思想是构建多个相互独立的评估器,然后对其预测进行平均或多数表决原则来决定集成评估器的结 果。装袋法的代表模型就是随机森林。
提升法中,基评估器是相关的,是按顺序一一构建的。其核心思想是结合弱评估器的力量一次次对难以评估的样本 进行预测,从而构成一个强评估器。提升法的代表模型有Adaboost和梯度提升树。
1.2 sklearn中的集成算法
1.2.1 集成算法模块ensemble
| 类 | Value |
|---|---|
| ensemble.AdaBoostClassifier AdaBoost | 分类 |
| ensemble.AdaBoostRegressor Adaboost | 回归 |
| ensemble.BaggingClassifier | 装袋分类器 |
| ensemble.BaggingRegressor | 装袋回归器 |
| ensemble.ExtraTreesClassifier Extra-trees分类( | 超树,极端随机树) |
| ensemble.ExtraTreesRegressor Extra-trees | 回归 |
| ensemble.GradientBoostingClassifier | 梯度提升分类 |
| ensemble.GradientBoostingRegressor | 梯度提升回归 |
| ensemble.IsolationForest | 隔离森林 |
| ensemble.RandomForestClassifier | 随机森林分类 |
| ensemble.RandomForestRegressor | 随机森林回归 |
| ensemble.RandomTreesEmbedding | 完全随机树的集成 |
| ensemble.VotingClassifier | 用于不合适估算器的软投票/多数规则分类器 |
集成算法中,有一半以上都是树的集成模型,可以想见决策树在集成中必定是有很好的效果。
1.2.2 sklearn的基本建模流程
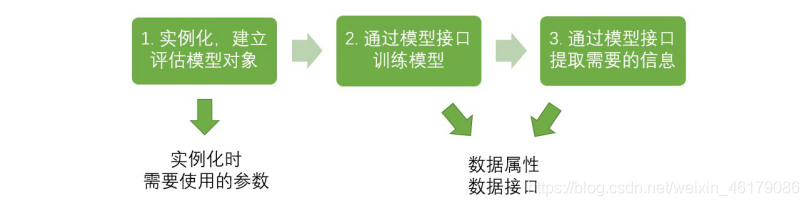
from sklearn.tree import RandomForestClassifier #导入需要的模块
rfc = RandomForestClassifier() #实例化
rfc = rfc.fit(X_train,y_train) #用训练集数据训练模型
result = rfc.score(X_test,y_test) #导入测试集,从接口中调用需要的信息
2 RandomForestClassifier
参数列表:class sklearn.ensemble.RandomForestClassifier (n_estimators=’10’, criterion=’gini’, max_depth=None,min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’,max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False,n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None)
随机森林是非常具有代表性的Bagging集成算法,它的所有基评估器都是决策树,分类树组成的森林
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1064
1064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









