








abstract:
多模态情感分析旨在从多个数据源提取情感,通常假设所有模态都可用。在实践中,这样一个强有力的假设并不总是成立,当部分模态缺失时,大多数多模态情感分析方法可能会失败。一些现有的作品已经开始解决缺少情态的问题;但是只考虑了单一模态缺失的情况,而忽略了实际更普遍的多模态缺失的情况。为此,在本文中,我们提出了一个TagAssisted Transformer Encoder (TATE)网络来处理不确定模态缺失问题。具体来说,我们设计了一个标签编码模块来覆盖单模态和多模态的缺失情况,从而引导网络关注那些缺失的模态。此外,考虑到每个模态的重要性不同,采用了一种新的空间投影模式对公共向量进行对齐。然后,利用Transformer编码器网络学习缺失的模态特征,提取Transformer编码器的输出用于最终的情感分类。在CMU-MOSI、IEMOCAP和MELD数据集上进行了大量的实验和分析,结果表明,与几种基线相比,该方法可以取得显著的改进。
intro:
近年来,情感分析在提取人类情感和观点方面引起了人们的浓厚兴趣,其中多模态情感分析随着网络内容的海量而成为一个特别热门的研究方向[1],[2],[3]。分析如此大规模的多模态数据对于在线平台理解个人行为或情绪至关重要。传统的单模态分析方法可能无法很好地处理多模态数据。单句“哦,当然!“没有足够的词汇信息,很难读懂情绪,如果有的话,声学形态可能有助于情绪识别。因此,结合不同的模态可以学习互补的特征,从而产生更好的联合多模态表示。
先前大多数关于多模态融合的研究[4],[5]都假设在训练和测试阶段所有模态都是可用的。

然而,在现实中,我们经常遇到可能缺失部分模态的情况。例如,如图1所示,由于相机的未覆盖,视觉特征可能被遮挡;由于环境噪声巨大,可能无法获得声学信息;出于隐私考虑,文本信息可能会缺失。因此,如何处理和恢复缺失模态已成为多模态情感分析中的一个重要课题。
为了处理缺失模态问题,一些研究[6]、[7]、[8]直接丢弃缺失模态或利用矩阵补全方法来进行缺失模态的归算,降低了整体性能。在[8]中,使用缺失数据进行训练时,将视觉模态去除。Zhao等[7]利用不同模态的共同实例完成了模态的核矩阵。由于深度学习具有强大的学习能力,近年来有研究利用深度神经网络来学习可用模态之间的潜在关系。
Tran等[9]首先发现了多模态数据中模态缺失的普遍问题,并提出了一种级联残差自编码器(CRA)网络,从不同模态中学习复杂关系。最近,Zhao等[10]采用循环一致性学习与CRA来恢复缺失的模态。Yuan等[11]设计了一种基于transformer的特征重构网络,用于指导提取器获取缺失模态特征的语义。Wei等[12]提供了一种基于张量融合网络的模态蒸馏策略,旨在从可用的模式中捕获交互。然而,这些现有的工作大多假设只有一种模态缺失,而忽略了实际更普遍的多模态不确定缺失的情况。也就是说,这些方法需要训练一个新的模型来拟合每一个缺失模态的情况,这显然既昂贵又不方便。在实践中,缺失模态的模式也可能是不确定的,例如,一个或两个模态随机缺失。此外,上述工作大多采用具有相同参数的简单前馈神经层对不同模态进行对齐,然后直接将它们连接起来获得联合表征。理想情况下,在融合时应进一步考虑不同模式的重要性。要解决上述问题,需要解决两个挑战:1)多种模式缺失的情况下,如何处理?2)当缺失模态不确定时,如何学习鲁棒联合表示?
在本文中,我们提出了一个标签辅助变压器编码器(TATE)网络来学习模式之间的互补特征。对于第一个挑战,我们设计了一个标签编码模块来标记缺失的模态,旨在引导网络的注意力到缺失的模态上。正如后面所展示的,附加标签不仅可以涵盖单模态和多模态缺失的情况,而且可以帮助联合表征学习。对于第二个挑战,我们首先采用Transformer[13]作为提取器来捕获模态内特征。由于每个模态的重要性可能不同,因此我们根据每个模态的准确性得分来计算关注权重。在这里,我们强调在连接多个模态时添加融合权重,并应用2乘2的投影模式将每个模态映射到公共空间。然后,利用全模态训练的预训练网络对编码向量进行监督。
具体来说,我们设计了一个前向差分损失来指导缺失模态的学习过程,一个后向重构损失来监督联合公共向量重构,一个标签恢复损失来让网络更多地关注添加的标签。最后,Transformer编码器生成的输出被输入到用于情绪预测的分类器中。我们的主要贡献总结如下:
-
针对多模态情感分析中的多模态缺失问题,提出了一种TATE网络。代码是公开的1。
-
我们设计了一个标签编码模块来涵盖单模态和多模态缺失的情况。我们还采用了一个新的公共空间投影模块,它考虑了不同模态对学习联合表示的重要性。
-
与CMU-MOSI, IEMOCAP和MELD数据集的几个基准测试相比,我们提出的模型取得了显着的改进,验证了其优越性。进一步的研究也证明了该方法的有效性
Q:TATE和先前的TFR-Net有什么相似的地方?
A:都用了transformer自注意力机制来处理各模态的特征,尤其是捕捉模态间的依赖关系。这使得两个模型都能学习到模态之间的复杂时序关系,从而提高特征表示的有效性。
related work:
在本节中,我们首先介绍了多模态情感分析的概念,然后讨论了处理缺失模态的方法。
多模态情感分析[15],[16],[17]作为情感分析的核心分支[18],[19],[20],近年来备受关注。与单一情态案例相比,由于处理和分析来自不同情态的数据的复杂性,多情态情感分析更具挑战性。为了学习多模态数据的联合表示,采用了三种多模态融合策略:1)早期融合在分类前直接结合不同模态的特征。Majumder等[21]提出了一种融合声学、视觉和文本模式的分层融合策略,并证明了二乘二融合模式的有效性;2)后期融合采用各模态的平均得分作为最终权重。Guo等[22]采用在线早-晚融合方案探索手语识别的互补关系,后期融合进一步聚合了早期融合所结合的特征;3)中间融合利用共享层来融合特征。Xu等[23]构建了分解和关系网络来表示模态之间的共性和差异。Hazarika等人[24]设计了一个多模态学习框架,通过将每个模态投射到两个不同的子空间,可以学习模态不变和模态特定的表示。需要强调的是,上述多模态融合模型不能处理部分模态缺失的情况。
根据处理情态缺失问题的策略,以往的作品大致可以分为两类
1)生成方法[9],[25],[26],[27],[28];2)联合学习方法[10]、[11]、[29]、[30]。
生成方法学习生成具有相似分布的新数据,以服从观测数据的分布。
由于具有学习潜在表征的能力,Auto-Encoder (AE)[25]得到了广泛的应用。Vincent等人[31]基于使学习到的表征对输入数据的部分损坏具有鲁棒性的思想,使用AE提取特征。Kingma等[32]设计了一种变分自编码器(Variational Auto-Encoder, VAE),通过简单的祖先采样来推断和学习特征。此外,受残差连接网络[33]的启发,Tran等[9]提出了一种级联残差自编码器(cascading residual Auto-encoder, CRA),将一系列残差ae组合成一个级联架构,以学习不同模态之间的关系。依靠生成对抗网络(GAN) [34], Shang等人[27]将每个视图视为一个单独的域,并使用每个视图的随机采样数据通过GAN识别域到域的映射。此外,还采用了域映射技术对缺失数据进行补全。沿着这条思路,Cai等[35]将缺失模态问题表述为一个条件图像生成任务,并设计了一个三维编码器-解码器网络来捕获模态关系。他们还在训练过程中纳入了可用的类别信息,以增强模型的鲁棒性。
此外,Zhao等人[28]开发了一个跨部分多视图网络来模拟不同视图之间的复杂相关性,其中使用多个鉴别器来生成缺失数据。
另一方面,联合学习方法试图基于不同模态之间的关系来学习联合表征[29],[36],[37]。基于循环一致性损失可以保留所有模态的最大信息的想法,Pham等人[29]研究了通过从源模态到目标模态的循环转换来学习鲁棒表征。结果表明,从源语态到目标语态的翻译有助于联合表征的学习。Zhao等[10]也将循环一致性学习应用于缺失模态的输入,并基于成对的多模态数据设计了基于ra的跨模态想象模块。然后,他们提出了一个缺失情态网络来处理不确定的缺失情况,从而提高情绪识别的性能。最近,Yuan等人[11]利用Transformer提取模态内和模态间的关系,并设计了一个基于Transformer的特征重建网络来重现缺失模态的语义。
我们想指出的是,以上大部分工作只能处理单个模态缺失的场景,而不能令人满意地处理多个模态缺失的情况(因为他们需要为每个模态缺失的情况训练一个新的模型)。很快就会清楚,我们开发的方案在几个方面不同于上述工作:1)设计了一个标签编码模块,以统一的方式覆盖所有不确定的丢失情况;2)采用一种考虑各模态融合权值的映射方法,在公共空间投影模块中学习更好的联合表示
method:
在本节中,我们首先给出问题定义和相关符号。然后,给出了该体系结构的总体工作流程和具体模块。
problem definition:
给定一个包含三个模态的多模态视频片段: ,其中
,其中![]() 分别表示视觉,声学和文本模态。在不损失一般性的前提下,我们用
分别表示视觉,声学和文本模态。在不损失一般性的前提下,我们用![]() 来表示缺失模态,其中m∈{v, a, t}。例如,假设视觉模态和声学模态都不存在,则多模态表示可以表示为
来表示缺失模态,其中m∈{v, a, t}。例如,假设视觉模态和声学模态都不存在,则多模态表示可以表示为![]() 。形式上,我们的问题定义如下:对于给定的三元组(Xv, Xa, Xt),一个或两个模态随机丢失。主要任务是根据可用的模式对整体情绪(积极,中立或消极)进行分类。
。形式上,我们的问题定义如下:对于给定的三元组(Xv, Xa, Xt),一个或两个模态随机丢失。主要任务是根据可用的模式对整体情绪(积极,中立或消极)进行分类。
overall:
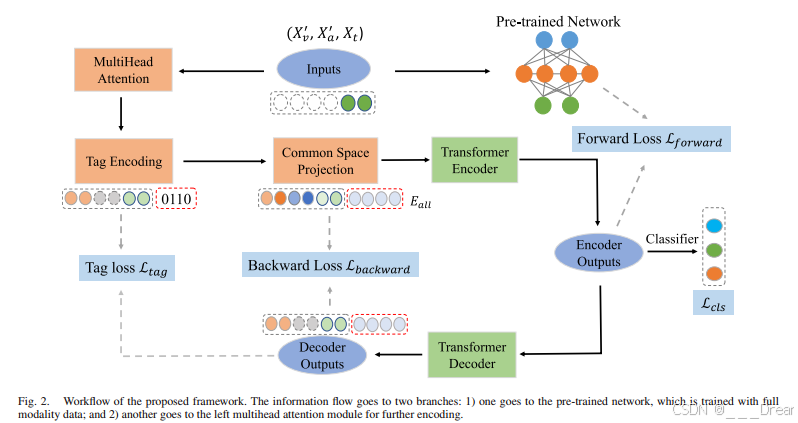
如图2所示,主要工作流程如下:对于给定的视频片段,假设缺失视觉模态和声学模态,我们首先将缺失的模态掩码为0,然后提取剩余的原始特征。然后,掩模多模态表示经过两个分支:1)一个分支由预训练模型编码,该模型使用所有全模态数据进行训练;2)另一个通过标签编码模块和公共空间投影模块获得对齐的特征向量。此外,更新的表示由Transformer编码器处理,并计算预训练向量与编码器输出之间的前向相似性损失。同时,将编码后的输出输入分类器进行情感预测。最后,我们计算了后向重构损失和标签恢复损失来监督联合表示学习。在下面的小节中,我们将介绍每个模块的详细信息。
Q:TFR-Net和TATE有什么区别?
A:
1. 架构设计与模态缺失处理方式
TFR-Net更偏向于对缺失模态特征的重建。使用 Transformer 编码器对其他模态进行学习,并生成缺失模态的特征。这些生成的特征并不直接参与最终情感分类,而是用于改进模型特征提取器在训练时的表现,使模型能更好地处理缺失模态。
TATE 使用 标签编码,对输入样本中缺失的模态进行标记,这个标记信息用于告知模型哪些模态缺失。该模型有一个 预训练网络分支,用于提供缺失模态的参考。此外,通过 前向和后向损失 对模型的输出进行监督,促使它在应对模态缺失时,依然能够学习到有效的特征表示。
2. 模态缺失标记
TFR-Net有M'
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









