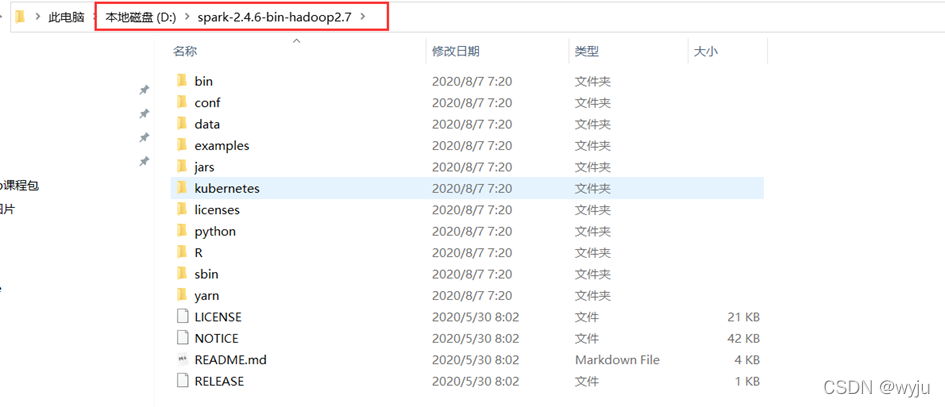
1. 解压Spark压缩包到D盘,如下图所示:
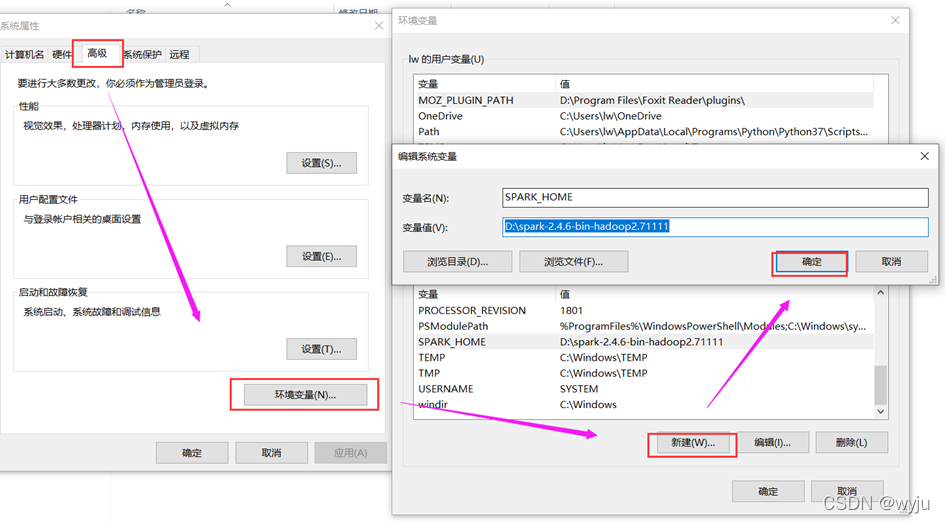
2.在环境变量中配置SPARK_HOME,如下图所示:
SPARK_HOME
自己的路径
D:\axc\spark-2.4.6-bin-hadoop2.7
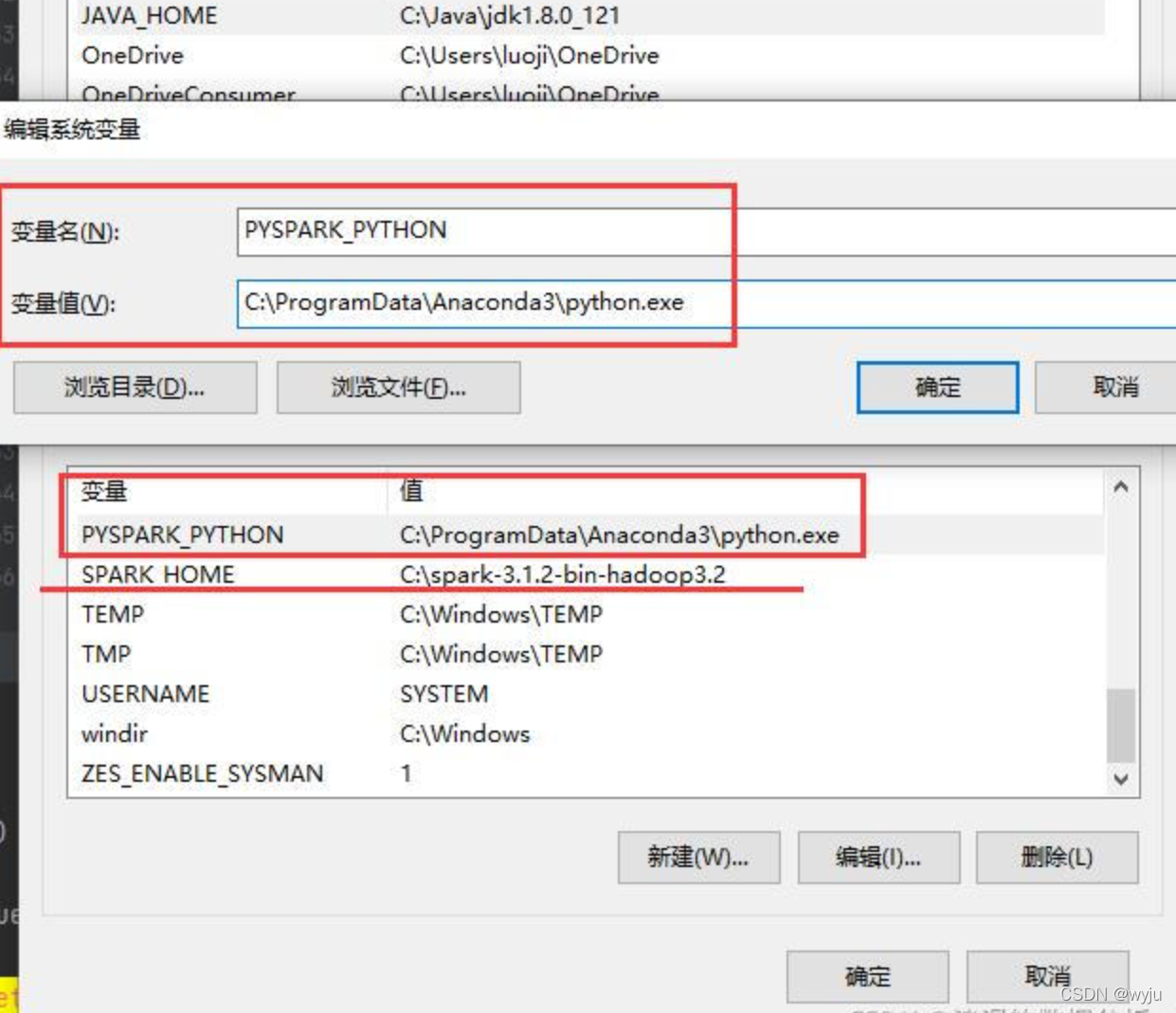
3.把SPARK_HOME 设置为python的exe文件
PYSPARK_PYTHON
自己的路径
C:\Users\wyj\AppData\Local\Programs\Python\Python37\python.exe
4. 复制spark下的pyspark目录到python安装目录下的lib目录,如下图所示:

5. 通过cmd执行pip install py4j命令安装py4j,py4j是一个在python中调用java代码的第三方库。效果如下图所示:

6.在D盘创建spark目录,存储我们的spark代码。
7.打开vscode,打开问哦们创建的存放spark代码的文件夹
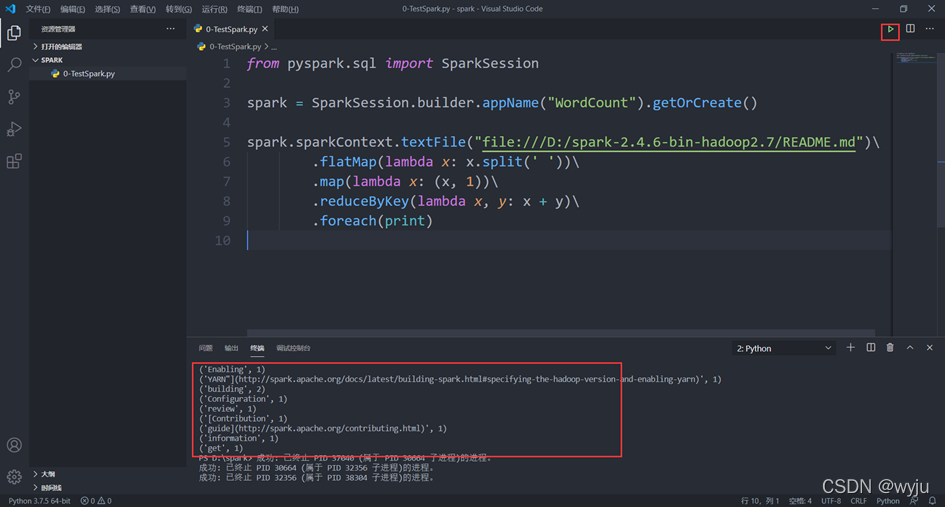
8.在VsCode中创建0-TestSpark.py文件,填入以下内容:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("WordCount").getOrCreate()
spark.sparkContext.textFile("file:///D:/spark-2.4.6-bin-hadoop2.7/README.md")\
.flatMap(lambda x: x.split(' '))\
.map(lambda x: (x, 1))\
.reduceByKey(lambda x, y: x + y)\
.foreach(print)
9.运行该python程序,对README.md文件做wordcount,效果如下图所示:
10.到这里我们配置就完成了,之后只要去写py文件就好,不用启动spark集群







 本文详细介绍了如何在VSCode中配置Spark环境,包括解压Spark、设置环境变量、安装py4j、创建工作目录,以及编写并运行Python Spark程序进行WordCount操作。
本文详细介绍了如何在VSCode中配置Spark环境,包括解压Spark、设置环境变量、安装py4j、创建工作目录,以及编写并运行Python Spark程序进行WordCount操作。

















 5009
5009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









