




 本文介绍了如何使用VSCode结合Remote-SSH和Scala Metals插件,搭建远程Spark应用开发环境。通过安装相关插件、配置环境变量、创建Scala项目、编写build.sbt文件,以及设置libraryDependencies,实现Spark项目的编译、运行和调试。这种方式特别适合远程环境的开发,提供了轻量化的解决方案。
本文介绍了如何使用VSCode结合Remote-SSH和Scala Metals插件,搭建远程Spark应用开发环境。通过安装相关插件、配置环境变量、创建Scala项目、编写build.sbt文件,以及设置libraryDependencies,实现Spark项目的编译、运行和调试。这种方式特别适合远程环境的开发,提供了轻量化的解决方案。
通常Spark普遍使用Jet Brain的Idea,用Idea建立本地服务器并进行测试开发,使用起来还相对不错,可以借力Idea强大而便捷的功能,使得开发应用相对得心应手。然而最近一直考虑远程服务器的搭建并建立开发环境,发现Idea缺乏远程开发的支持或支持不是十分完美。一段时间使用VSCode,感觉十分不错,轻量化,尤其完美的远程服务器模式,不仅支持WSL,也支持SSH远程模式很适合远程环境配置开发。以下是使用VSCode借力远程服务插件和Scala Metals插件搭建Spark应用开发环境记录心得。
1 VSCode安装远程服务插件
在VSCode扩展搜索安装Remote-SSH和Remote-WSL插件,他们分别支持SSH远程和WSL的环境开发。
2 在VSCode扩展搜索安装Scala语言插件Scala Syntax (official)和Scala (Metals),核心是Scala Metals,该插件是Metals针对VSCode插件,为Scala center维护,可谓具有相当官方地位,具备代码补全、提示、高亮、运行与调试等功能。需要注意,不要同时安装 Scala Language Server 和 Scala (sbt) 插件。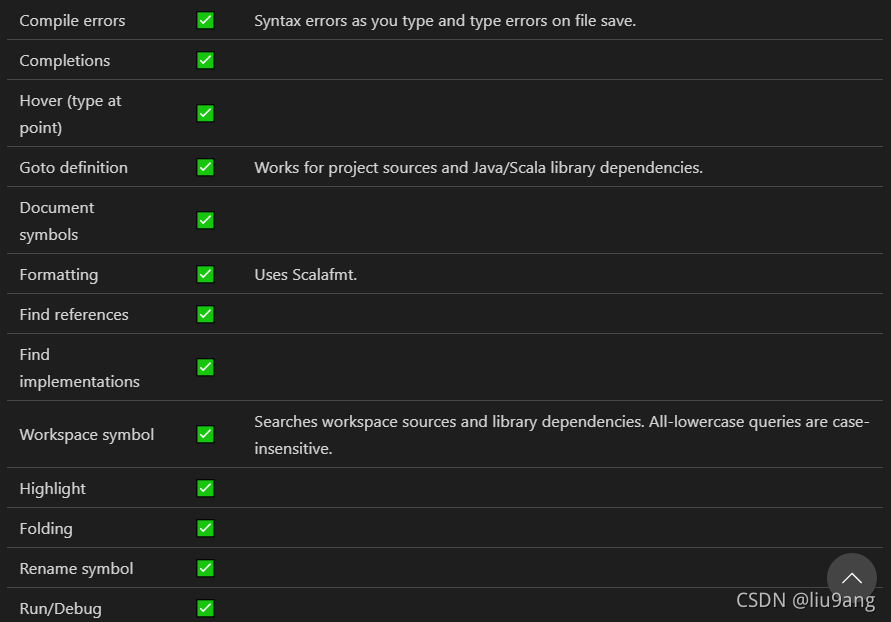
官方网址:Metals | Metals (scalameta.org) https://scalameta.org/metals/3 下载安装配置必要的应用软件,包括JDK、Scala、Sbt、Spark、Hadoop等。如果是本机测试,最小安装包括Spark,相应Hadoop、Scala。应该注意相互的版本匹配,比如spark-3.1.1-bin-hadoop3.2,选择安装hadoop-3.2.1,注意查看spark-3.1.1-bin-hadoop3.2 Scala版本,在Spark安装目录里jars下,可以看到Spark Scala是2.12.10,所以下载安装Scala 2.12.10。Sbt可以下载安装最新版。另需要注意,在Windows系统下,Spark最新版3.2.0安装后无法正常启动,但Spark 3.1.2还有以前的版本基本上能够正常运行。运行本地最小Spark其实并不需要Hadoop的安装,为了避免出错,在Windows系统下下载安装相应版本的Hadoop编译winutils,可以到Github下载。kontext-tech/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows (github.com)https://github.com/kontext-tech/winutils
https://scalameta.org/metals/3 下载安装配置必要的应用软件,包括JDK、Scala、Sbt、Spark、Hadoop等。如果是本机测试,最小安装包括Spark,相应Hadoop、Scala。应该注意相互的版本匹配,比如spark-3.1.1-bin-hadoop3.2,选择安装hadoop-3.2.1,注意查看spark-3.1.1-bin-hadoop3.2 Scala版本,在Spark安装目录里jars下,可以看到Spark Scala是2.12.10,所以下载安装Scala 2.12.10。Sbt可以下载安装最新版。另需要注意,在Windows系统下,Spark最新版3.2.0安装后无法正常启动,但Spark 3.1.2还有以前的版本基本上能够正常运行。运行本地最小Spark其实并不需要Hadoop的安装,为了避免出错,在Windows系统下下载安装相应版本的Hadoop编译winutils,可以到Github下载。kontext-tech/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows (github.com)https://github.com/kontext-tech/winutils
JKD安装1.8版本,更高版本很多时候会出现各种各样的问题,适配性较差。软件安装需要完成一系列的设置,比如各环境变量JAVA_HOME、HADOOP_HOME、SPARK_HOME、SCALA_HOME、SBT_HOME,指向相应的软件安装目录,设置PATH路径。
4 创建Scala项目。创建项目目录比如spark-test,在内创建目录结构src/main/scala。在项目目录中启动VSCode。这是在我机器的WSL下状态。
wslu@LAPTOP-Q1FQOTCB:~/devz$ mkdir spark-test
wslu@LAPTOP-Q1FQOTCB:~/devz$ cd spark-test
wslu@LAPTOP-Q1FQOTCB:~/devz/spark-test$ mkdir -p src/main/scala
wslu@LAPTOP-Q1FQOTCB:~/devz/spark-test$ code .
在项目下新建文件build.sbt。
scalaVersion := "2.12.10"
name := "spark-test"
version := "1.0"
libraryDependencies += "org.scala-sbt" %% "zinc" % "1.5.7"
libraryDependencies += "org.scala-lang.modules" %% "scala-parser-combinators" % "1.1.2"修改scalaVersion和name适合你的设置,保存,此时会弹出Import the build,选Import build,此时Metals监测到项目的变化,识别项目是Scala项目,会开始进行一系列的项目设置,并下载相关依赖。当项目中有.sbt或.scala文件发生变化,Metals都会识别,做相应的Import build或编译等动作。
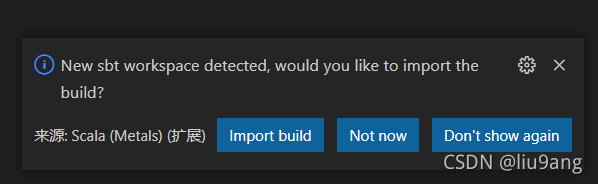
可以看到项目结构产生了变化,在项目下新产生一些"."开头的文件目录和project、target目录。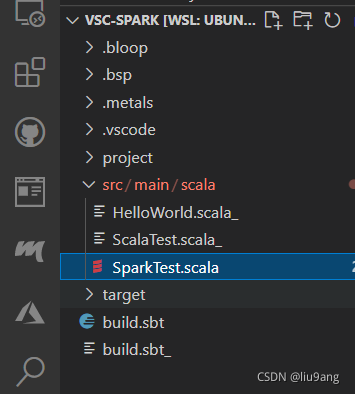
注意 libraryDependencies += "org.scala-sbt" %% "zinc" % "1.5.7" 是Metals项目需要的。以下可以编写代码。
首先在build.sbt中添加依赖:
libraryDependencies +="org.apache.spark"%%"spark-core"%"3.1.1"
libraryDependencies +="org.apache.spark"%%"spark-sql"%"3.1.1"注意 ”3.2.0“ 是Spark版本,要适合你的Spark版本号。
创建Scala文件,比如Spark Test.scala,输入代码,保存。
import org.apache.spark.sql.SparkSession
object SparkTest {
def main(args: Array[String]) = {
println("hello scala!")
val ss = SparkSession.builder
.appName("SparkTest")
.master("local[*]")
.getOrCreate()
import ss.implicits._
ss.createDataset(1 to 10).show()
ss.close()
}
}Matels会识别变化,进行一些动作,然后可以运行程序。
在VSCode开启终端,用SBT编译、打包和运行程序。
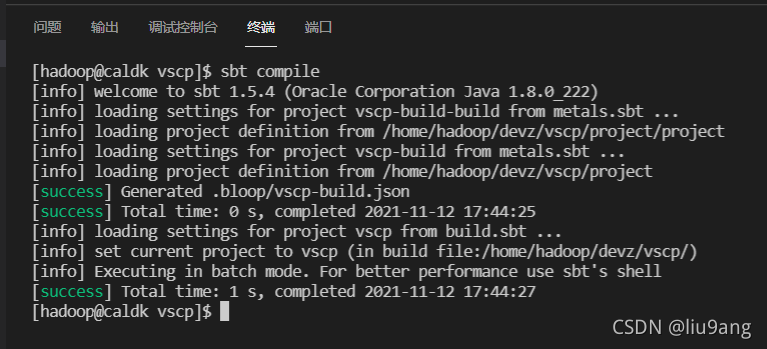
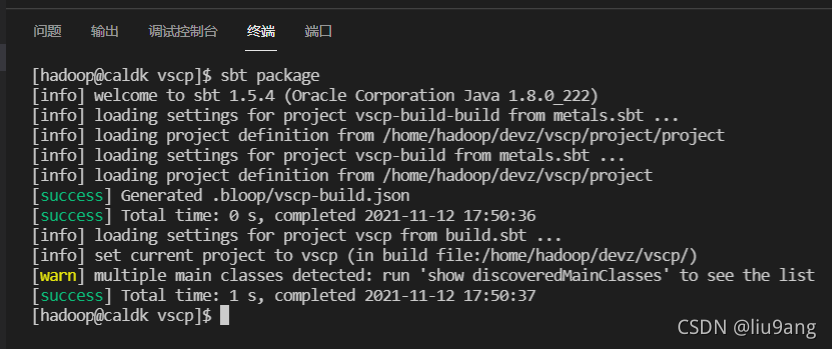
点击编辑窗口 run | debug,可以借助Metals直接进行程序的运行和调试。

这后几个截图都是SSH远程运行的结果。
哈!不错呦。

















 2466
2466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









