







 本文详细介绍了Python pandas库中用于统计特征的累积计算(cum系列函数)和滚动计算(rolling系列函数)。通过实例展示了如何计算累计和、乘积、最大值和最小值,以及如何进行滚动求和、平均值、方差、标准差等操作。对于滚动计算时出现的Nan值问题,给出了使用`min_periods`参数解决的方案。
本文详细介绍了Python pandas库中用于统计特征的累积计算(cum系列函数)和滚动计算(rolling系列函数)。通过实例展示了如何计算累计和、乘积、最大值和最小值,以及如何进行滚动求和、平均值、方差、标准差等操作。对于滚动计算时出现的Nan值问题,给出了使用`min_periods`参数解决的方案。
Python pandas 的统计特征函数主要包括累积计算函数(cum系列函数)和滚动计算函数(pd.rolling_系列函数)
1. 累积计算统计特征函数
1.1累计函数的种类:
- cumsum(): 依次计算前1, 2, …, n 个数的和
- cumprod(): 依次计算前1, 2, …, n 个数的乘积
- cummax(): 依次找到前1, 2, …, n 个数的最大值
- cummin(): 依次找到前1, 2, …, n 个数的最小值
1.2 基本使用方法:
import numpy as np
import pandas as pd
# 1. 累计和与累计乘积
x = pd.Series(range(1, 10))
print("累计和:\n", x.cumsum())
print("累计乘积:\n", x.cumprod())

# 2. 求累计的最大值与最小值
x = pd.Series([3, 2, 6, 1, 7, 4, 8])
print("输出累计最大值:\n", x.cummax())
print("输出累计最小值:\n", x.cummin())

2. 滚动计算统计特征函数
2.1 累计函数的种类:
- rolling_sum(): 计算数据样本的总和(按列进行计算)
- rolling_mean(): 计算数据样本的算术平均值
- rolling_var(): 计算数据样本的方差
- rolling_std(): 计算数据样本的标准差
- rolling_corr(): 计算数据样本的相关系数矩阵(pearson/spearman)
- rolling_cov(): 计算数据样本的协方差矩阵
- rolling_skew(): 计算数据样本的偏度(三阶矩)
- rolling_kurt():计算数据样本的方差(四阶矩)
2.2基本使用方法:
# 1. rolling_滚动函数的基本使用
x = pd.Series(range(1, 10))
print("每相邻2个数据相加的结果:\n", x.rolling(2).sum())
print(30*"-")
print("每相邻3个数据相加的结果:\n", x.rolling(3).sum())

# 2. DataFrame中的使用:
x = pd.DataFrame([range(1, 10), range(10, 100, 10), range(2, 20, 2)]).T
x.rolling(2).mean()
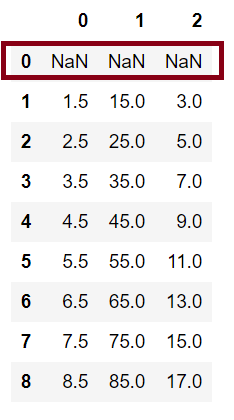
小结:发现第1行有“Nan”值,可使用参数min_periods来消除
# 3. 消除滚动计算在第1行产生的"Nan"值
x = pd.DataFrame([range(1, 10), range(10, 100, 10), range(2, 20, 2)]).T
x.rolling(2, min_periods=1).mean()
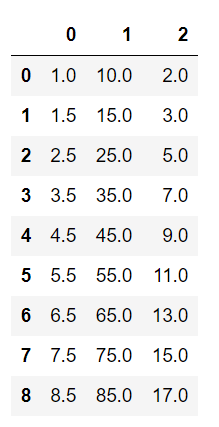
这样,第1行存在"Nan"的问题就解决了!

















 158
158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









