







 本文介绍ELK(Elasticsearch、Logstash、Kibana)日志分析平台的基本概念及其应用场景,详细讲解Elasticsearch的安装配置过程,包括单机与集群部署步骤,并介绍如何使用head插件辅助管理。
本文介绍ELK(Elasticsearch、Logstash、Kibana)日志分析平台的基本概念及其应用场景,详细讲解Elasticsearch的安装配置过程,包括单机与集群部署步骤,并介绍如何使用head插件辅助管理。
一、ELK介绍
1、什么是ELK
ELK 是elastic公司提供的一套完整的日志收集以及展示的解决方案,是三个产品的首字母缩写,分别是ElasticSearch、Logstash 和 Kibana。
1.1、E-ELASTICSEARCH
ElasticSearch简称ES,它是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析,它是一个建立在全文搜索引擎Apache Lucene基础上的搜索引擎,使用Java语言编写。
1.2、L-LOGSTASH
Logstash是一个具有实时传输能力的数据收集引擎,用来进行数据收集(如:读取文本文件)、解析,并将数据发送给ES。
1.3、K-KIBANA
Kibana为 Elasticsearch 提供了分析和可视化的 Web 平台。它可以在 Elasticsearch 的索引中查找,交互数据,并生成各种维度表格、图形。
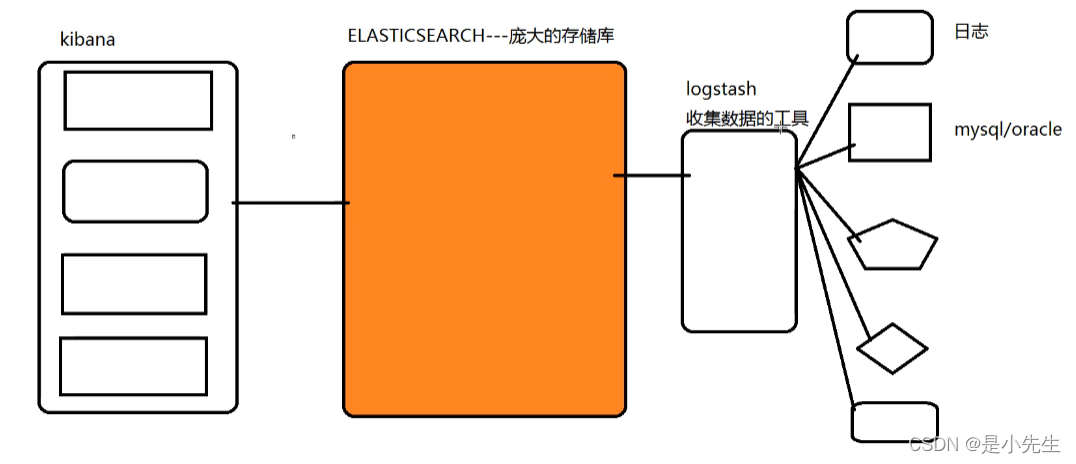
2、为什么要使用ELK
有三个原因:
分布式集群:
数据量庞大:PB级别甚至更高
搜索需求要求高:快,准,多维度全文搜索
ELASTICSEARCH就支持这种场景,也是目前全文搜索功能使用最多的一种技术.
数据源丰富:
数据库数据
日志数据
其他分散存储的数据.
LOGSTASH可以从多数据源采集数据
数据的价值:
所谓数据保存的越多,数据提现的价值就越多.前提是需要分析展示数据.KIBANA就可以提供数据的仪表分析等功能.
所以基于上述的一些问题,开源实时日志分析 ELK 平台能够完美的解决, ELK 由 ElasticSearch 、 Logstash 和 Kiabana 三个开源工具组成。
二、ELASTICSEARCH概括
1、ES安装和启动
①、安装
截止到现在,最新版本8.1.3,ES的更新速度非常快,我们在学习的时候结合官方文档,查看其改动,官网:Get Started with Elasticsearch, Kibana, and the Elastic Stack | Elastic
这里我们为了方便管理安装包,我们在/home下新建一个文件夹
cd /home
mkdir resource
rz 上传我们的elasticsearch,我用的elasticsearch-7.10.2-linux-x86_64.tar.gz
然后解压到software目录下
tar -zxvf /home/resource/elasticsearch-7.10.2-linux-x86_64.tar.gz -C /home/software/
配置es根目录下的jdk环境
当前版本的es7.10.2,要求最推荐使用jdk11以上的环境,根目录已经准备好了jdk15.
cd /home/software/elasticsearch-7.10.2/
cd jdk/
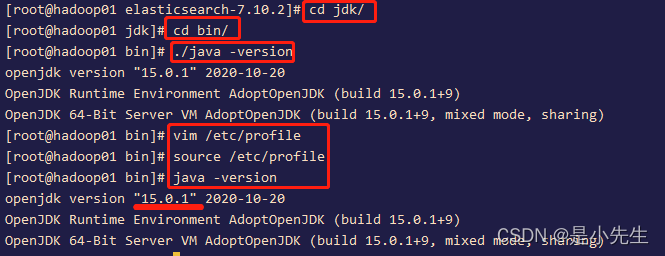
cd bin/./java -version
vim /etc/profile
source /etc/profile
export JAVA_HOME=/home/software/elasticsearch-7.10.2/jdk
export PATH=$JAVA_HOME/bin:$PATH
②、启动
安装完成后,我们可以在服务器启动这个ES软件
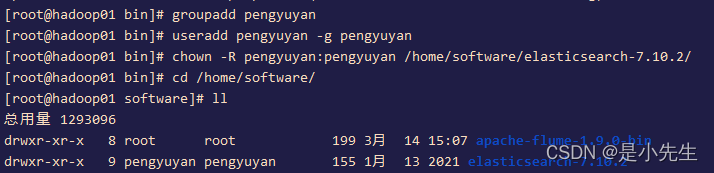
添加用户用户组
ES拒绝root用户直接启动软件,需要创建新用户,并且赋权启动
groupadd pengyuyan
useradd pengyuyan -g pengyuyan赋权:
chown -R pengyuyan:pengyuyan /home/software/elasticsearch-7.10.2/
cd /home/software/
ll
启动ES:
切换用户
su pengyuyan
cd /home/software/elasticsearch-7.10.2/
./bin/elasticsearch
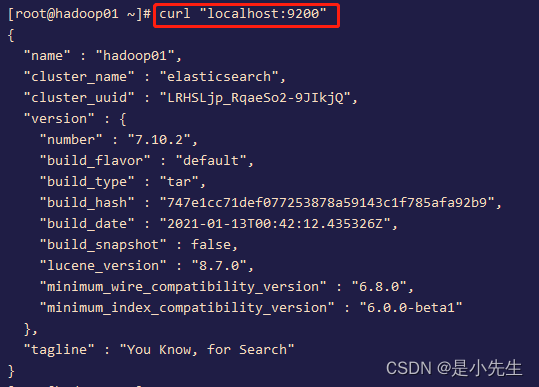
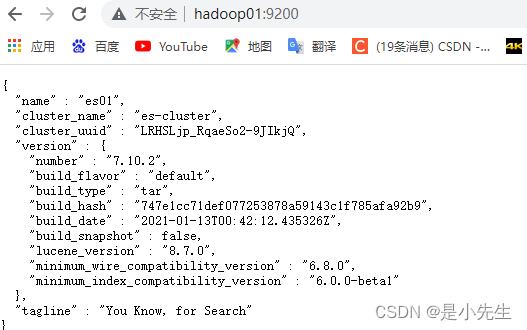
测试es进程:
复制一个窗口,发送一个 http请求,查看es
③、配置集群启动
上面介绍的是一台服务的配置,实际上我们应该配置多个服务器各自启动一个ES进程,想要将他们添加到同一个集群,就需要进行相关的配置
配置文件:ES目录中的config/elasticsearch.yml文件:
将文件拷贝到hadoop02与hadoop03并且做下面操作:
scp -r /home/software/elasticsearch-7.10.2 hadoop02:/home/software/
scp -r /home/software/elasticsearch-7.10.2 hadoop03:/home/software/添加用户用户组
groupadd pengyuyan
useradd pengyuyan -g pengyuyan赋权:
chown -R pengyuyan:pengyuyan /home/software/elasticsearch-7.10.2/
cd /home/software/
ll
首先我们进入ES目录中的config/elasticsearch.yml文件,配置下面的内容:
cd /home/software/elasticsearch-7.10.2/config/
vim elasticsearch.ymlcluster.name: es-cluster node.name: es01 path.data: /home/software/elasticsearch-7.10.2/data path.logs: /home/software/elasticsearch-7.10.2/logs bootstrap.memory_lock: false bootstrap.system_call_filter: false network.host: 0.0.0.0 http.port: 9200 transport.tcp.port: 9300 discovery.seed_hosts: ["192.168.186.128", "192.168.186.129","192.168.186.130"] cluster.initial_master_nodes: ["192.168.186.128"] http.cors.enabled: true http.cors.allow-origin: "*"
- cluster.name 集群名称,同一个服务器集群的节点实例的集群名称要一致.
- node.name 节点名称,也就是你启动的每个es的进程的名字.
- path.data 数据路径,指定当前es进程节点的存储数据的文件夹.注意:如果路径不在启动es用户的权限范围之内,启动会报错
- path.logs es启动的日志文件夹. 注意:如果路径不在启动es用户的权限范围之内,启动会报错
- bootstrap.memory_lock 锁定物理内容,会造成性能降低,将其关闭.
- bootstrap.system_call_filter 系统调用过滤器主要是防止任意代码攻击漏洞的.将其关闭.
- network.host es进程绑定的物理ip可以ipv4 可以ipv6,默认是localhost不允许外界访问.
- http.port es进程绑定占用的http协议访问端口,默认9200.
- transport.tcp.port: es进程绑定单用的tcp协议访问端口,默认9300
- discovery.seed_hosts 配置主机hosts名单,主要可以使用ip:port的方式来配置.有几个节点,就配置几个节点.
- cluster.initial_master_nodes 集群第一次启动初始化时,想要指定的主机节点是谁,一旦配置,初始主机节点就定了,后续可以将这个配置删除.
- http.cors.enabled 是否支持跨域访问,如果支持,有一些代理软件是可以访问es的比如head插件
- http.cors.allow-origin 当设置了支持跨域后,允许的跨域域名都有哪些,默认是*.
三个节点的配置如下:
hadoop01: cluster.name: es-cluster node.name: es01 path.data: /home/software/elasticsearch-7.10.2/data path.logs: /home/software/elasticsearch-7.10.2/logs bootstrap.memory_lock: false bootstrap.system_call_filter: false network.host: 0.0.0.0 http.port: 9200 transport.tcp.port: 9300 discovery.seed_hosts: ["192.168.186.128", "192.168.186.129","192.168.186.130"] cluster.initial_master_nodes: ["192.168.186.128"] http.cors.enabled: true http.cors.allow-origin: "*" hadoop02: cluster.name: es-cluster node.name: es02 path.data: /home/software/elasticsearch-7.10.2/data path.logs: /home/software/elasticsearch-7.10.2/logs bootstrap.memory_lock: false bootstrap.system_call_filter: false network.host: 0.0.0.0 http.port: 9200 transport.tcp.port: 9300 discovery.seed_hosts: ["192.168.186.128", "192.168.186.129","192.168.186.130"] cluster.initial_master_nodes: ["192.168.186.128"] http.cors.enabled: true http.cors.allow-origin: "*" hadoop03: cluster.name: es-cluster node.name: es03 path.data: /home/software/elasticsearch-7.10.2/data path.logs: /home/software/elasticsearch-7.10.2/logs bootstrap.memory_lock: false bootstrap.system_call_filter: false network.host: 0.0.0.0 http.port: 9200 transport.tcp.port: 9300 discovery.seed_hosts: ["192.168.186.128", "192.168.186.129","192.168.186.130"] cluster.initial_master_nodes: ["192.168.186.128"] http.cors.enabled: true http.cors.allow-origin: "*"修改 vim /etc/profile
export JAVA_HOME=/home/software/elasticsearch-7.10.2/jdk
export PATH=$JAVA_HOME/bin:$PATHsource /etc/profile
三台启动:
su pengyuyan
cd /home/software/elasticsearch-7.10.2/
./bin/elasticsearch可能报错:
1 内存不够报错 vi jvm.options es 5.x版本默认启动内存需要4g ,对于一些低内存的虚拟机或者云服务器可能无法启动,需要修改默认内存参数,红色是默认的,黄色是我修改后我自己机器的,大小根据你机器配置修改。 2 can not run es as root 产生这个错误原因是: 这是出于系统安全考虑设置的条件。由于ElasticSearch可以接收用户输入的脚本并且执行,为了系统安全考虑,建议创建一个单独的用户用来运行ElasticSearch 解决办法: 单独创建一个用户来专门启动 es 创建es用户组及es用户 groupadd es useradd es-g es-p es 更改elasticsearch文件夹及内部文件的所属用户及组为es : es chown -R es:es elasticsearch elasticsearch为你elasticsearch的目录名称 切换到es用户再启动 su es #切换账户 cd elasticsearch/bin #进入你的elasticsearch目录下的bin目录 成功启动 3 UnsupportedOperationException: seccomp unavailable: CONFIG_SECCOMP not compiled into kernel, CONFIG_SECCOMP and CONFIG_SECCOMP_FILTER are needed 解决办法: 原因: 因为Centos6不支持SecComp,而ES默认bootstrap.system_call_filter为true进行检测,所以导致检测失败,失败后直接导致ES不能启动解决:修改elasticsearch.yml 添加一下内容 : bootstrap.memory_lock: false bootstrap.system_call_filter: false 4 Caused by: java.net.BindException: Cannot assign requested address 配置外网 进入 config/ elasticsearch.ym 打开配置文件elasticsearch.yml 将 network.host: 192.168.0.1 修改为本机IP 0.0.0.0 5 initial heap size [104857600] not equal to maximum heap size [209715200]; this can cause resize pauses and prevents mlockall from locking the entire heap [2]: max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536] [3]: max number of threads [1024] for user [es] is too low, increase to at least [2048] [4]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] 解决办法: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] 解决:切换到root用户修改配置sysctl.conf vi /etc/sysctl.conf 添加下面配置: vm.max_map_count=655360 并执行命令: sysctl -p max number of threads [1024] for user [es] is too low, increase to at least [2048] 解决:切换到root用户,进入limits.d目录下修改配置文件。 vi /etc/security/limits.d/90-nproc.conf 修改如下内容: soft nproc 1024 #修改为 soft nproc 2048 max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536] 解决:切换到root用户,编辑limits.conf 添加类似如下内容 vi /etc/security/limits.conf 添加如下内容: *soft nofile 65536 *hard nofile 131072 *soft nproc 2048 *hard nproc 4096
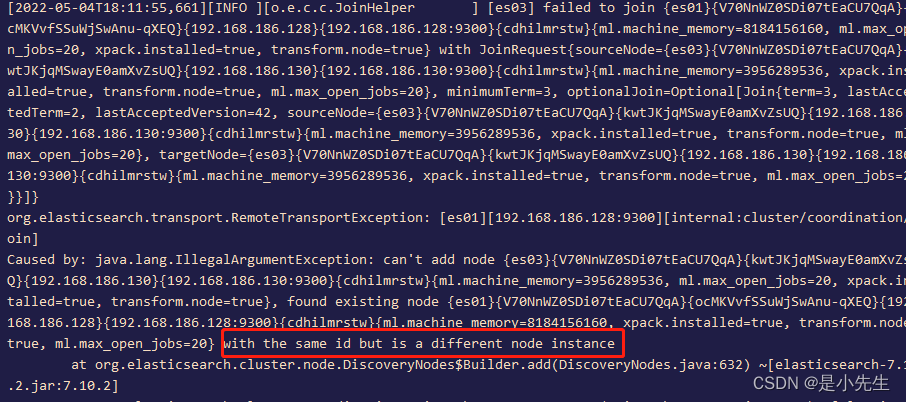
这个错误因为我们拷贝过来的问题:
解决办法:我们进入root用户
exit
然后进入
cd /home/software/elasticsearch-7.10.2/data/
删除data写的nodesrm -rf nodes/
然后新建:mkdir nodes
给定权限: chown -R pengyuyan:pengyuyan /home/software/elasticsearch-7.10.2/data/
再次启动就成功了
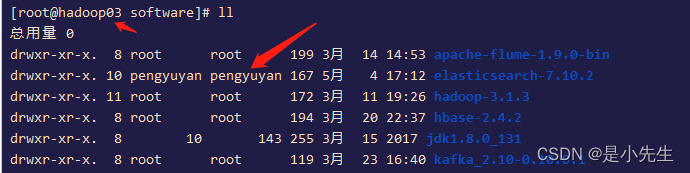
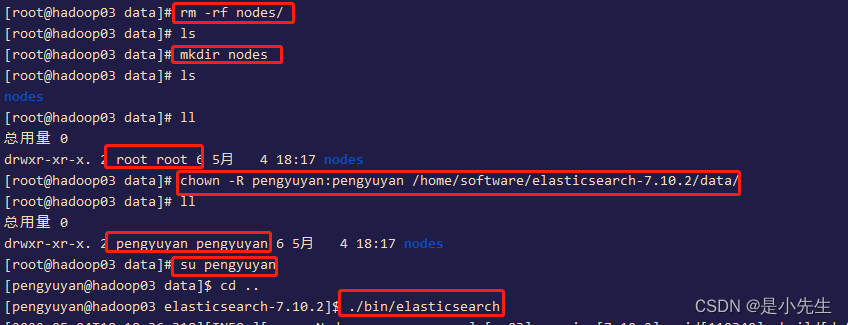
这样我们三台配置就成功了!
2、ES的head插件
head插件是一个可以帮助用户代理访问es的,可以图形界面展示数据的插件,我们配置了es的跨域开启,所以为了方便观察,我们可以安装head插件
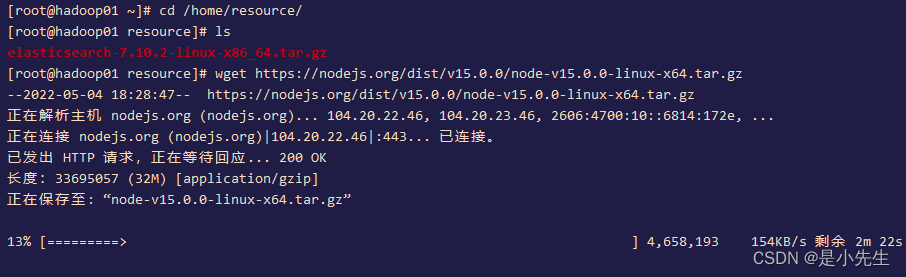
①、node.js安装
head插件成功运行的语言环境就是node,需要提前安装:
wget https://nodejs.org/dist/v15.0.0/node-v15.0.0-linux-x64.tar.gz
解压:
tar -xf node-v15.0.0-linux-x64.tar.gz -C /home/software/
添加环境变量:
export NODE_HOME=/home/software/node-v15.0.0-linux-x64
export PATH=$PATH:$NODE_HOME/bin生效环境变量,然后查看node版本
source /etc/profile
node -v




















 1478
1478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











