







 本文详细介绍了Apache Flume的基础概念、执行流程,以及各类Source组件如AVROSource、ExecSource等的配置与应用实例。涵盖安装、多级流动和自定义Source的开发。
本文详细介绍了Apache Flume的基础概念、执行流程,以及各类Source组件如AVROSource、ExecSource等的配置与应用实例。涵盖安装、多级流动和自定义Source的开发。
目录
一、Flume的简介

1、概述
①、Flume原本是由Cloudera公司开发的后来贡献给了Apache的一套分布式的、可靠的、针对日志数据进行收集(collecting)、汇聚(aggregating)和传输(moving)的机制
②、在大数据中,实际开发中有超过70%的数据来源于日志,日志是大数据的基石
③、Flume针对日志提供了非常简单且灵活的流式传输机制
④、版本
Flume0.X:又称之为Flume-og。依赖于Zookeeper,结构配置相对复杂,现在市面上已经停用这个版本
Flume1.X:又称之为Flume-ng。不依赖于Zookeeper,结构配置相对简单,是市面上常用的版本
2、基本概念
①、Event
在Flume中,会将收集到的每一条日志封装成一个Event对象 - 在Flume中,一个Event就对应了一条日志
Event本质上是一个json串,固定的包含两部分:headers和body - Flume将收集到的日志封装成一个json,而这个json就是Event。Event的结构是{"headers":{},"body":""}
②、Agent:是Flume流动模型的基本组成结构,固定的包含了三个部分:
Source:从数据源采集数据的 - collecting
Channel:临时存储数据 - aggregating
Sink:将数据写往目的地 - moving
3、流动模型/拓扑结构
①、单级流动
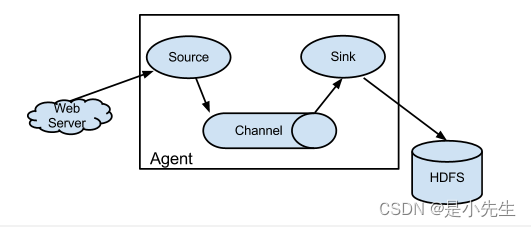
②、多级流动
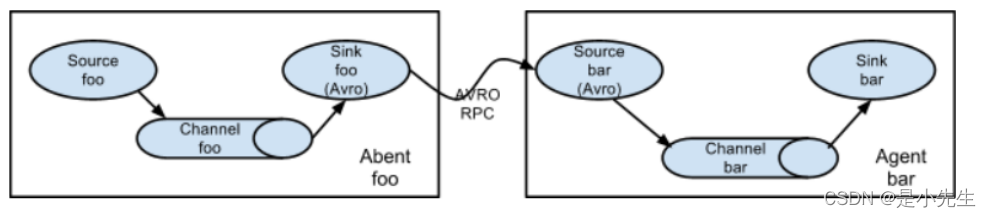 理解:就像城市中从小河取水,为了防止雨天城市被水淹,我们将城市与小河相隔较远,但是取水如何方便,我们可以建立蓄水此,建立一个实际上就是三个阶段,从小河引水,蓄水池蓄水,送到城市。一个蓄水池,可以理解为单极流动,多个就可以理解为多级流动。
理解:就像城市中从小河取水,为了防止雨天城市被水淹,我们将城市与小河相隔较远,但是取水如何方便,我们可以建立蓄水此,建立一个实际上就是三个阶段,从小河引水,蓄水池蓄水,送到城市。一个蓄水池,可以理解为单极流动,多个就可以理解为多级流动。
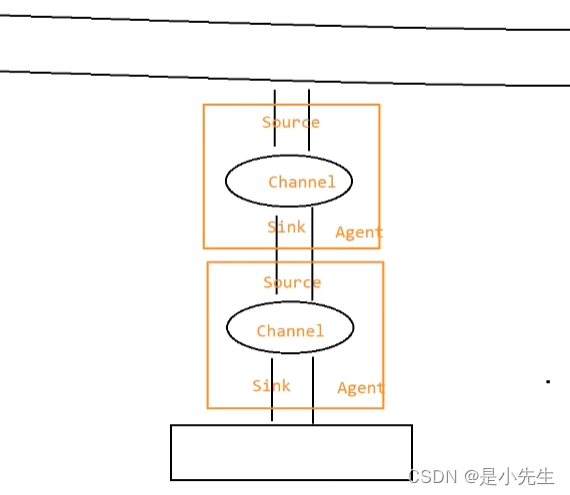
③、扇入流动
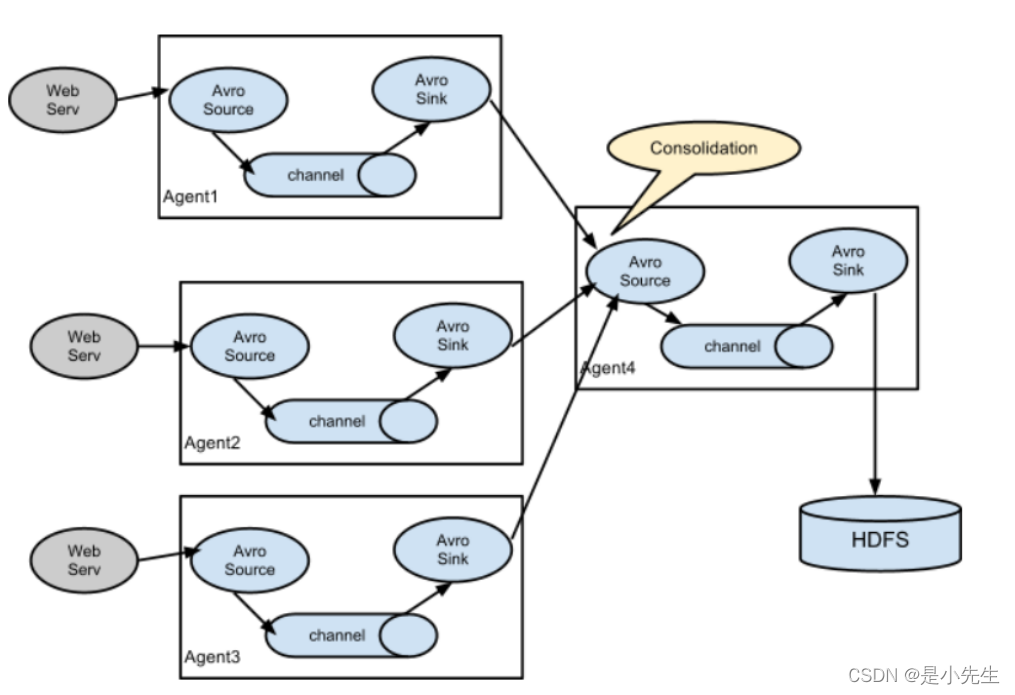
理解:可以看成多个水源的合并过程。
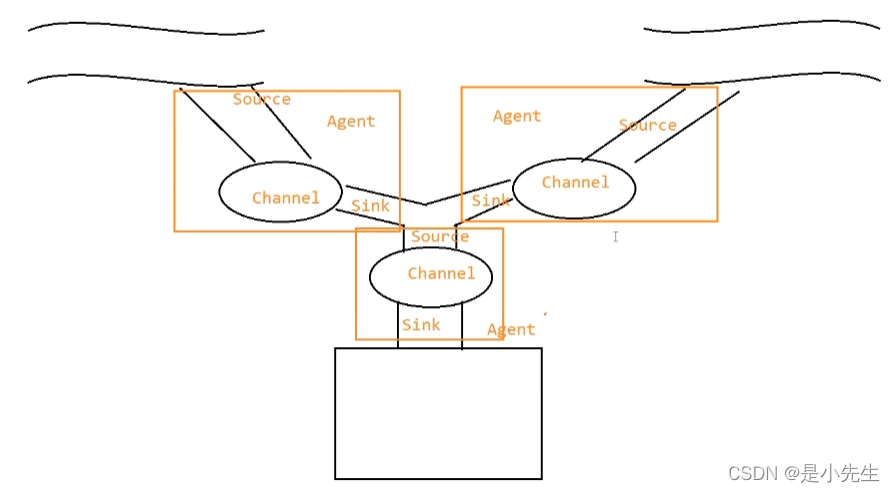
④、扇出流动
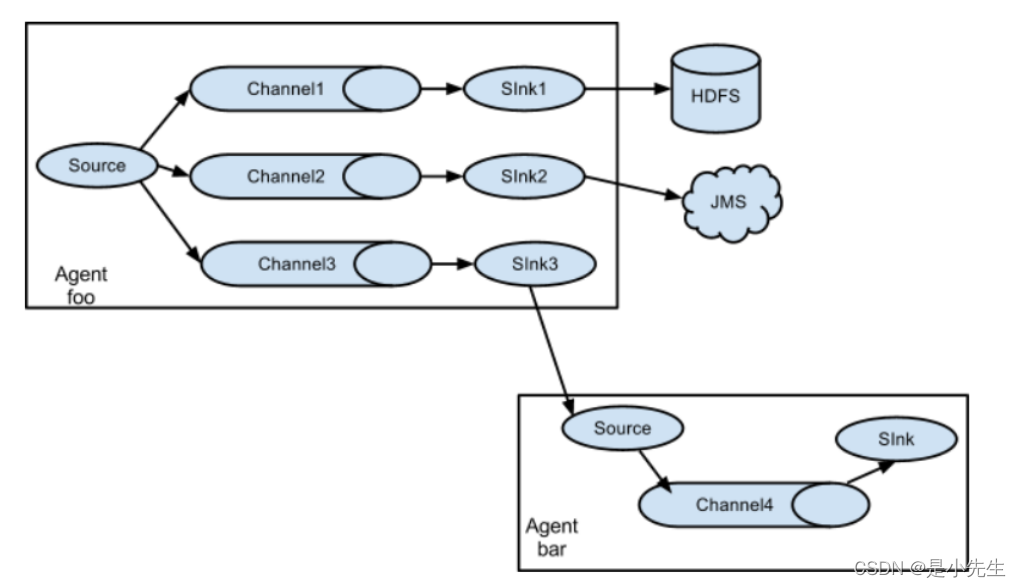
⑤、复杂流动
复杂流动:实际过程中,根据不同的需求来将上述的流动模型进行组合,就构成了复杂流动结构
二、执行流程
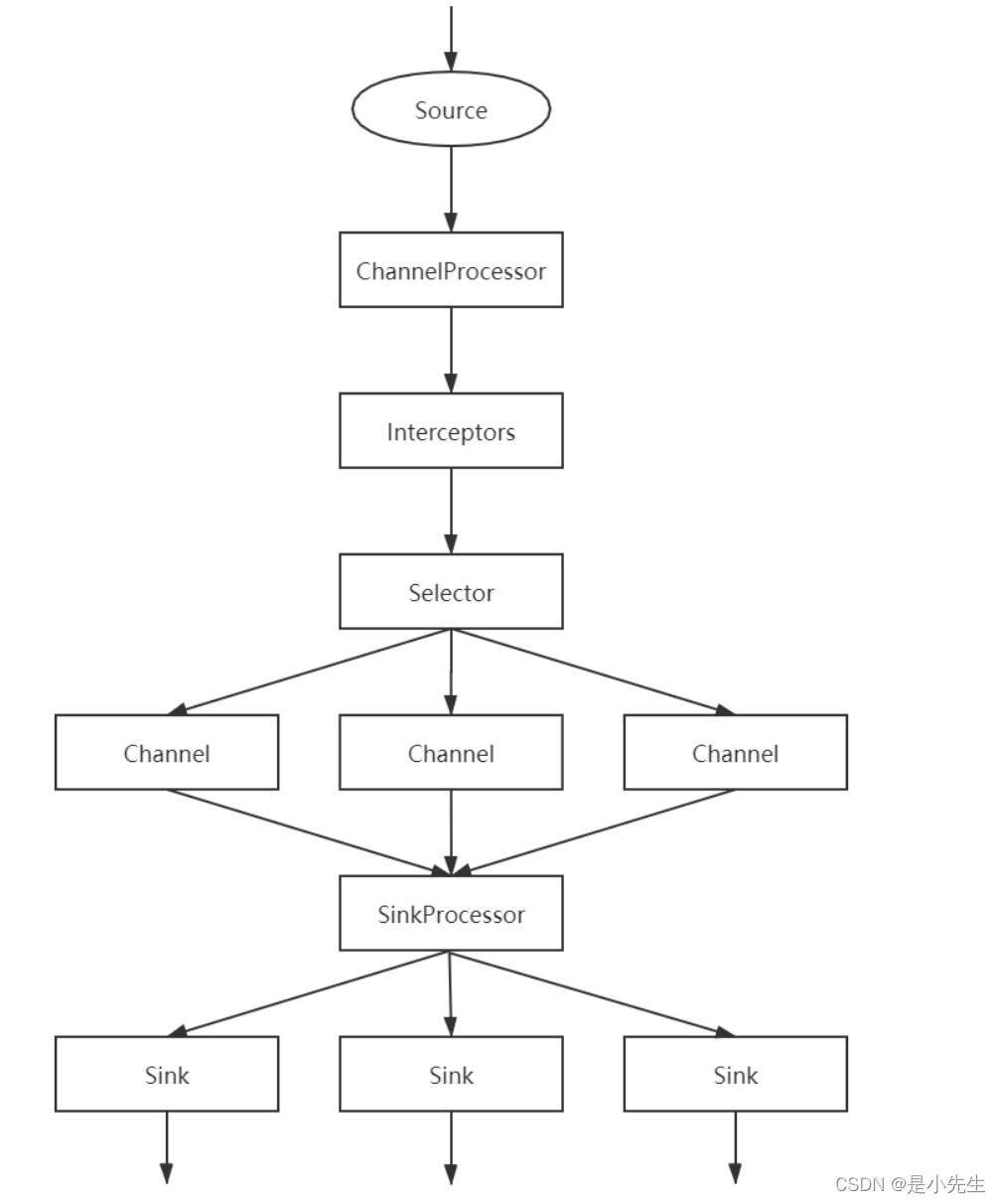
1、Source会先采集数据,然后将数据发送给ChannelProcessor进行处理
2、ChannelProcessor处理之后,会将数据交给Interceptor来处理,注意,在Flume允许存在多个Interceptor来构成拦截器链
3、Interceptor处理完成之后,会交给Selector处理,Selector存在两种模式:replicating和multiplexing。Selector收到数据之后会根据对应的模式将数据交给对应的Channel来处理
4、Channel处理之后会交给SinkProcessor。SinkProcessor本质上是一个Sinkgroup,包含了三种方式:Default,Failover和Load Balance。SinkProcessor收到数据之后会根据对应的方式将数据交给Sink来处理
5、Sink收到数据之后,会将数据写到指定的目的地
三、安装Flume
1、要求虚拟机或者云主机上必须安装JDK1.8,最好安装Hadoop
2、进入/home/software目录下,上传apache-flume-1.9.0-bin.tar.gz
cd /home/software/
3、解压Flume的安装包
tar -xvf apache-flume-1.9.0-bin.tar.gz
4、让Flume和Hadoop兼容(如果没有安装Hadoop,那么这一步不需要执行)
cd apache-flume-1.9.0-bin/lib
rm -rf guava-11.0.2.jar
5、新建目录用于存储Flume的格式文件
cd ..
mkdir data
cd data
6、编辑格式文件
vim basic.conf
添加格式文件内容
# 给Agent起名 # 给Source起名 a1.sources = s1 # 给Channel起名 a1.channels = c1 # 给Sink起名 a1.sinks = k1 # 配置Source a1.sources.s1.type = netcat a1.sources.s1.bind = 0.0.0.0 a1.sources.s1.port = 8090 # 配置Channel a1.channels.c1.type = memory # 配置Sink a1.sinks.k1.type = logger # 将Source和Channel绑定 a1.sources.s1.channels = c1 # 将Sink和Channel绑定 a1.sinks.k1.channel = c1
7、启动Flume
../bin/flume-ng agent -n a1 -c ../conf -f basic.conf -Dflume.root.logger=INFO,console
参数解释:
| 参数 | 解释 |
| -n,--name | 指定要运行的Agent的名字 |
| -c,--conf | 指定Flume运行的原生配置 |
| -f,--conf-file | 指定要运行的文件 |
| -Dflume.root.logger | 指定Flume本身运行日志的打印级别及打印方式 |
四、Source
1、AVRO Source
①、概述
AVRO Source监听指定的端口,接收其他节点发送来的被AVRO序列化的数据
AVRO Source结合AVRO Sink可以实现更多的流动模型,包括多级流动、扇入流动以及扇出流动
②、配置属性
| 属性 | 解释 |
| type | 必须是avro |
| bind | 要监听的主机的主机名或者IP |
| port | 要监听的端口 |
③、案例
编辑格式文件vim avrosource.conf,在格式文件添加指定的内容
a1.sources = s1
a1.channels = c1
a1.sinks = k1
# 配置AVRO Source
# 必须是avro
a1.sources.s1.type = avro
# 指定要监听的主机
a1.sources.s1.bind = hadoop01
# 指定要监听的端口
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1启动Flume
../bin/flume-ng agent -n a1 -c ../conf -f avrosource.conf -Dflume.root.logger=INFO,console
在另一个窗口中,进入指定目录,编辑文件
cd /home/software/apache-flume-1.9.0-bin/data
vim a.txt
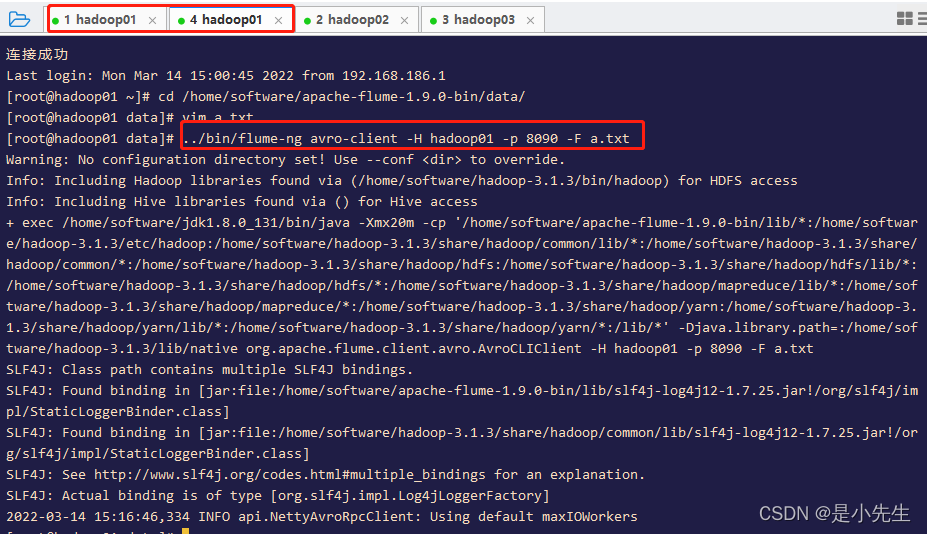
运行AVRO客户端
../bin/flume-ng avro-client -H hadoop01 -p 8090 -F a.txt
在flume窗口可以看到监听内容
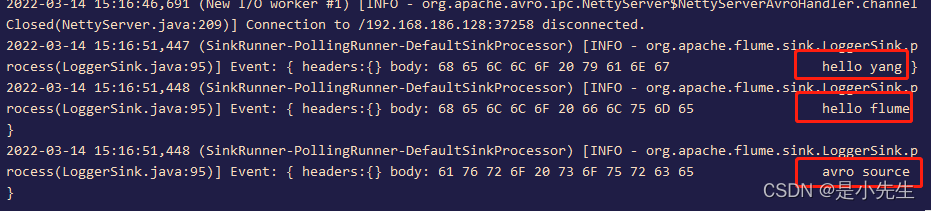
2、Exec Source
①、概述
Exec Source会运行指定的命令,然后将命令的执行结果作为日志进行收集
利用这个Source可以实现对文件或者其他操作的实时监听
②、配置属性
| 属性 | 解释 |
| type | 必须是exec |
| command | 要执行和监听的命令 |
| shell | 最好指定这个属性,表示指定Shell的运行方式 |
③、案例
需求:实时监听/home/a.txt文件的变化
编辑vim execsource.conf格式文件,添加如下内容
a1.sources = s1
a1.channels = c1
a1.sinks = k1
# 配置Exec Source
# 必须是exec
a1.sources.s1.type = exec
# 指定要运行的命令
a1.sources.s1.command = tail -F /home/a.txt
# 指定Shell的运行方式/类型
a1.sources.s1.shell = /bin/bash -c
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1启动Flume
../bin/flume-ng agent -n a1 -c ../conf -f execsource.conf -Dflume.root.logger=INFO,console
修改文件内容
echo "hello java" >> a.txt
在一个窗口执行操作
flume窗口就会监听到文件变化


3、Spooling Directory Source
①、概述
Spooling Directory Source是监听指定的目录,自动将目录中出现的新文件的内容进行收集
如果不指定,默认情况下,一个文件被收集之后,会自动添加一个后缀.COMPLETED,通过通过属性fileSuffix来修改
②、配置属性
| 属性 | 解释 |
| type | 必须是spooldir |
| spoolDir | 要监听的目录 |
| fileSuffix | 收集之后添加的文件后缀,默认是.COMPLETED |
③、案例
编辑vim spoolingdirsource.conf格式文件,添加如下内容
a1.sources = s1
a1.channels = c1
a1.sinks = k1
# 配置Spooling Directory Source
# 必须是spooldir
a1.sources.s1.type = spooldir
# 指定要监听的目录
a1.sources.s1.spoolDir = /home/flumedata
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1启动flume
../bin/flume-ng agent -n a1 -c ../conf -f spoolingdirsource.conf -Dflume.root.logger=INFO,console
在另一个窗口操作
我们会发现,监听窗口将a.txt的文件内容放到flumedata这个操作日志打印出来了

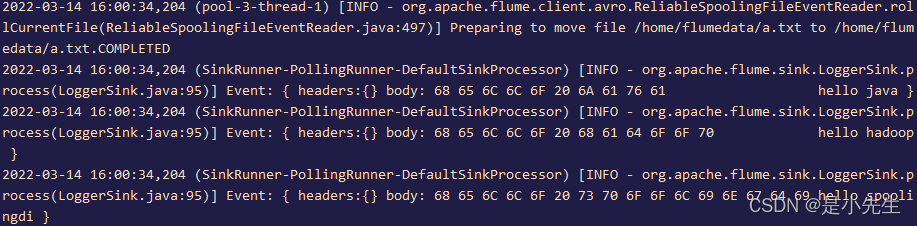
4、Netcat Source
①、概述
Netcat Source在Flume1.9之后分为Netcat TCP Source和Netcat UDP Source
如果不指定,那么Netcat Source监听的是TCP请求
②、配置属性
| 属性 | 解释 |
| type | 如果监听TCP请求,那么使用netcat;如果监听UDP请求,那么使用netcatudp |
| bind | 要监听的主机的主机名或者IP |
| port | 要监听的端口 |
③、案例
上面入门案例监听的是TCP请求。
现在我们编辑vim netcatudpsource.conf格式文件,添加如下内容(以UDP为例):
a1.sources = s1
a1.channels = c1
a1.sinks = k1
# 配置Netcat UDP Source
# 必须是netcatudp
a1.sources.s1.type = netcatudp
# 指定要监听的主机
a1.sources.s1.bind = 0.0.0.0
# 指定要监听的端口
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1启动Flume
../bin/flume-ng agent -n a1 -c ../conf -f netcatudpsource.conf -Dflume.root.logger=INFO,console
启动nc
nc -u hadoop01 8090


5、Sequence Generator Source
①、概述
Sequence Generator Source本质上就是一个序列产生器,会从0开始每次递增1个单位
如果不指定,默认情况下递增到Long.MAX_VALUE
②、配置属性
| 属性 | 解释 |
| type | 必须是seq |
| totalEvents | 递增的结束范围 |
③、案例
编辑vim seqsource.conf格式文件,添加如下内容
a1.sources = s1
a1.channels = c1
a1.sinks = k1
# 配置Sequence Generator Source
# 必须是seq
a1.sources.s1.type = seq
# 指定结束范围
a1.sources.s1.totalEvents = 10
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1启动flume
../bin/flume-ng agent -n a1 -c ../conf -f seqsource.conf -Dflume.root.logger=INFO,console
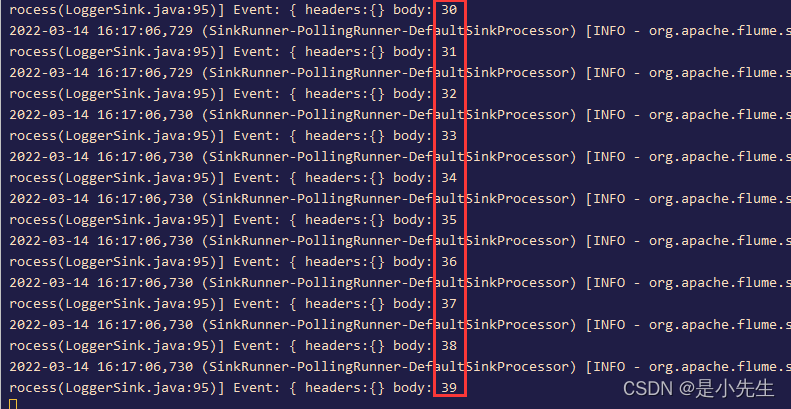
6、HTTP Source
①、概述
HTTP Source用于监听HTTP请求,但是只能监听POST和GET请求
GET请求只用于试验阶段,所以实际过程中只用这个Source来监听POST请求
②、配置属性
| 属性 | 解释 |
| type | 必须是http |
| port | 要监听的端口 |
③、案例
编辑vim httpsource.conf格式文件,添加如下内容
a1.sources = s1
a1.channels = c1
a1.sinks = k1
# 配置HTTP Source
# 必须是http
a1.sources.s1.type = http
# 指定要监听的端口
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1启动flume
../bin/flume-ng agent -n a1 -c ../conf -f httpsource.conf -Dflume.root.logger=INFO,console
发送POST请求
curl -X POST -d '[{"headers":{"kind":"test","class":"bigdata"},"body":"testing"}]' http://hadoop01:8090
http://hadoop01:8090
http://hadoop01:8090
五、Custom Source
1、概述
①、自定义Source:需要定义一个类实现Source接口的子接口:EventDrivenSource或者PollableSource
EventDrivenSource:事件驱动源 - 被动型Source。需要自己定义线程来获取数据处理数据
PollableSource:拉取源 - 主动型Source。提供了线程来获取数据,只需要考虑怎么处理数据即可
②、除了实现上述两个接口之一,这个自定义的类一般还需要考虑实现Configurable接口,通过接口的方法来获取指定的属性
2、步骤
①、需要构建Maven工程,导入对应的POM依赖
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-sdk</artifactId>
<version>1.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-configuration</artifactId>
<version>1.9.0</version>
</dependency>
</dependencies>②、定义类继承AbstractSource,实现EventDrivenSource和Configurable接口
③、覆盖configure,start和stop方法
package org.example.flume.source;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.EventDrivenSource;
import org.apache.flume.channel.ChannelProcessor;
import org.apache.flume.conf.Configurable;
import org.apache.flume.event.EventBuilder;
import org.apache.flume.source.AbstractSource;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
// 模拟:Sequence Generator Source
public class AuthSource extends AbstractSource implements EventDrivenSource, Configurable {
private ExecutorService es;
private long end;
private long step;
// 启动Source
@Override
public synchronized void start() {
//构建线程池
es = Executors.newFixedThreadPool(5);
// 获取Channel处理器
ChannelProcessor cp = this.getChannelProcessor();
//提交任务
es.submit(new Add(end, step,cp));
}
@Override
public synchronized void stop() {
if (es != null){
es.shutdown();
}
}
//通过这个方法来获取指定的属性值
@Override
public void configure(Context context) {
//获取自增的最大值,如果不指定,默认是Long.MAX_VALUE
end = context.getLong("end", Long.MAX_VALUE);
//获取自增的步长,如果不指定,默认是1
step = context.getLong("step", 1L);
}
}
class Add implements Runnable{
private final long end;
private final long step;
private final ChannelProcessor cp;
Add(long end, long step,ChannelProcessor cp) {
this.end = end;
this.step = step;
this.cp=cp;
}
@Override
public void run() {
for(long i=0;i<end;i+=step){
// 在Flume中,数据都是以Event形式存在的
// 封装body
byte[] body = (i+"").getBytes(StandardCharsets.UTF_8);
// 封装headers
Map<String,String> headers = new HashMap<>();
headers.put("time",System.currentTimeMillis()+"");
// 构建Event对象
Event e = EventBuilder.withBody(body,headers);
// 将Event对象交给Channel处理器处理
cp.processEvent(e);
}
}
}
④、定义完成之后,需要将类打成jar包放到Flume安装目录的lib目录下
![]()
⑤、编写格式文件,例如
a1.sources = s1
a1.channels = c1
a1.sinks = k1
# 配置自定义Source
# 必须是类的全路径名
a1.sources.s1.type =org.example.flume.source.AuthSource
# 指定结束范围
a1.sources.s1.end = 100
# 指定递增的步长
a1.sources.s1.step = 5
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
⑥、启动flume
../bin/flume-ng agent -n a1 -c ../conf -f authsource.conf -Dflume.root.logger=INFO,console
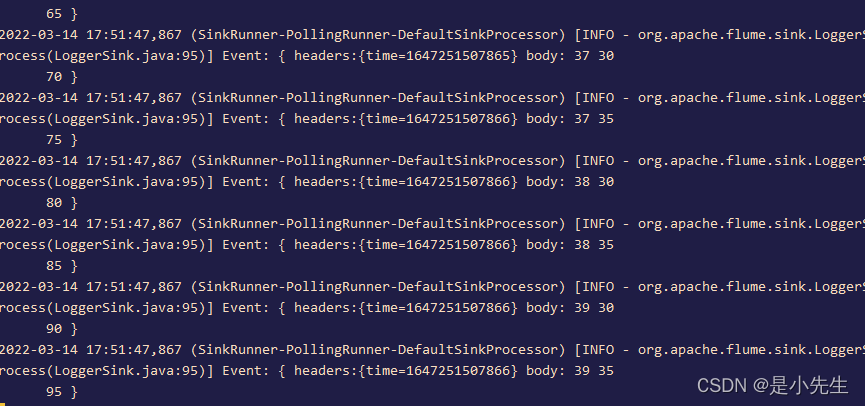


















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











