课程内容
1、Set集合
2、HashSet存储自定义元素保证唯一性的原理
3、Map双列集合的顶层接口
4、HashMap哈希存储
5、Collections工具类
1、set集合是Collection下的一个子接口
2、特点:
无序:没有任何前后的区别,存入的顺序和取出的顺序是不一样的,所有的元素在集合中没有位置上的概念
没有索引
不能重复,没有位置上的区别,相同的元素没有任何区分,所有不能重复
3、Set的实现类:
HashSet:使用哈希表的存储方式来存储元素
4、存储特点:
相同的元素不能存入到set集合中
集合本身不保证顺序的,存入的顺序和取出的顺序是不一样的
package com. ujiuye. demos ;
import java. util. HashSet ;
import java. util. Set ;
public class Demo_1 {
public static void main ( String [ ] args) {
Set < String > = new HashSet < > ( ) ;
set. add ( "赵丽颖" ) ;
set. add ( "赵丽颖" ) ;
set. add ( "迪丽热巴" ) ;
set. add ( "迪丽热巴" ) ;
set. add ( "杨幂" ) ;
set. add ( "杨幂" ) ;
set. add ( "陈乔恩" ) ;
set. add ( "陈乔恩" ) ;
set. add ( "王丽坤" ) ;
System . out. println ( set) ;
Set < String > = new HashSet < > ( ) ;
set1. add ( "a" ) ;
set1. add ( "b" ) ;
set1. add ( "c" ) ;
System . out. println ( set1) ;
}
}
1、没有特有的方法,只能使用Collection接口中定义的方法,只能使用Collection的遍历方式
2、第一种:转成数组toArray(),不带泛型的数组,得到的是Object类型的数组
3、第二种: 转成数组 T[] toArray(T[] t),带泛型的数组,得到的是T类型的数组
(1)自己创建的数组大小,小于集合元素的个数
在方法中,就会创建一个新的数组,用来存储集合中的元素,将数组返回
(2)自己创建的数组大小,等于集合元素的个数
在方法中,就不会创建一个新的数组,使用集合中的元素将传入的数组进行填充,将原数组进行返回
(3)自己创建的数组大小,大于集合元素的个数
在方法中,不会创建一个新的数组,直接将集合中的元素填充到数组中的前面的位置,后面的位置用默认值填充
4、第三种:迭代器
5、第四种:增强for循环(foreach)
格式:for(元素的数据类型 元素名称 :要遍历的集合或者数组){
使用元素名称代表当前访问的元素;
}
说明:
元素的数据类型:指的是要遍历集合中元素的数据类型
元素名称:元素名称虽然是固定的,但是随着循环的执行,每次代表的元素是不同的
要遍历的集合:可以是数组也可以是集合
本质:
底层迭代器,只不过使用这种格式更为简单
注意事项:使用增强for,没有拿到元素的索引,无法修改集合或者数组中的元素值
底层迭代器,所在在遍历集合的时候,使用集合对象添加元素,也会发生并发修改异常
package com. ujiuye. demos ;
import java. util. Arrays ;
import java. util. HashSet ;
import java. util. Iterator ;
import java. util. List ;
import java. util. Set ;
public class Demo_2 {
public static void main ( String [ ] args) {
Set < String > = new HashSet < > ( ) ;
set. add ( "赵丽颖" ) ;
set. add ( "赵丽颖" ) ;
set. add ( "迪丽热巴" ) ;
set. add ( "迪丽热巴" ) ;
set. add ( "杨幂" ) ;
set. add ( "杨幂" ) ;
set. add ( "陈乔恩" ) ;
set. add ( "陈乔恩" ) ;
set. add ( "王丽坤" ) ;
System . out. println ( set) ;
for ( String str : set) {
System . out. println ( str) ;
}
int [ ] arr = { 1 , 2 , 3 , 4 } ;
for ( int i : arr) {
System . out. println ( i) ;
}
}
private static void bianLi_3 ( Set < String > ) {
Iterator < String > = set. iterator ( ) ;
while ( it. hasNext ( ) ) {
System . out. println ( it. next ( ) ) ;
}
}
private static void bianLi_2 ( Set < String > ) {
String [ ] strs1 = new String [ 3 ] ;
String [ ] array1 = set. toArray ( strs1) ;
System . out. println ( strs1 == array1) ;
System . out. println ( Arrays . toString ( array1) ) ;
System . out. println ( "=========自己创建的数组大小,等集合元素的个数========================" ) ;
String [ ] strs2 = new String [ set. size ( ) ] ;
String [ ] array2 = set. toArray ( strs2) ;
System . out. println ( strs2 == array2) ;
System . out. println ( Arrays . toString ( array2) ) ;
System . out. println ( "=========自己创建的数组大小,大于集合元素的个数========================" ) ;
String [ ] strs3 = new String [ set. size ( ) + 3 ] ;
String [ ] array3 = set. toArray ( strs3) ;
System . out. println ( strs3 == array3) ;
System . out. println ( Arrays . toString ( strs3) ) ;
}
private static void bianLi_1 ( Set < String > ) {
Object [ ] objs = set. toArray ( ) ;
for ( int i = 0 ; i < objs. length; i++ ) {
System . out. println ( objs[ i] ) ;
}
}
}
HashSet存储jdk提供的元素的类型,发现直接保证了元素的唯一性,值相同的元素都去掉了
1、HashSet存储自定义类型元素发现并没有保证唯一性
2、实验:猜测没有重写equals方法,没有重写之前比较的地址值,如果地址值一样了就不存储,不一样就存储,但是
重写后equals方法比较的是属性值,发现并没有调用,没有去重成功
3、猜测Hashset集合是哈希实现,有没有可能跟HashCode方法有关,重写HashCode方法
在重写hashcode方法之前,调用的Object中的hashcode方法,不同的对象(对象的地址值不同)生成的hashcode值就是不同的。
重写hashcode方法之后,让Person中hashcode方法生成的值都为0(实现的效果,不同的对象对象的地址值不同的时候)生成的hashCode值一样的,发现确实hashCode方法执行了,equals方法也执行了。
4、发现了,HashSet存储自定义类型元素的时候,确实要调用自定义元素类型中的hashCode方法,根据hashCode方法的值判断是否将自定义元素存入到集合中。发现不同的对象(地址值不同)调用Object类中的hashCode方法生成的是不同的的hashcode值,就直接存储,不能实现去重,equals方法也不调用
重写hashcode方法之后,让Person中hashcode方法生成的值都为0,发现调用equals方法,根据equasl方法比较的结果判断是否添加重复的元素
1、Object类型中的方法
2、根据对象,生成一个整数,就是哈希吗值,生成数字的方法的就是hashCode()
3、生成数字的原则:
(1)同一个对象,多次调用hashCode()方法【必须】返回的是相同的数字(程序多次运行不要求hashCode码值一致)
(2)使用equals(Object) 方法判断相同的两个对象【必须】返回相同的整数(equals是Object类型中的,比较的是地址值)
(3)使用equals(Object) 方法判断不相同的两个对象【尽量】生成不相同的整数(不做强制要求)
(4)Object类型中的HashCode方法,确实会根据不同的对象生成不同的整数。
package com. ujiuye. demos ;
public class Demo_4 {
public static void main ( String [ ] args) {
Object obj = new Object ( ) ;
Object obj2 = new Object ( ) ;
System . out. println ( obj. hashCode ( ) ) ;
System . out. println ( obj. hashCode ( ) ) ;
System . out. println ( obj. hashCode ( ) ) ;
System . out. println ( obj. hashCode ( ) ) ;
System . out. println ( obj2. hashCode ( ) ) ;
Object obj1 = obj;
System . out. println ( obj1. hashCode ( ) ) ;
System . out. println ( obj2. hashCode ( ) ) ;
}
}
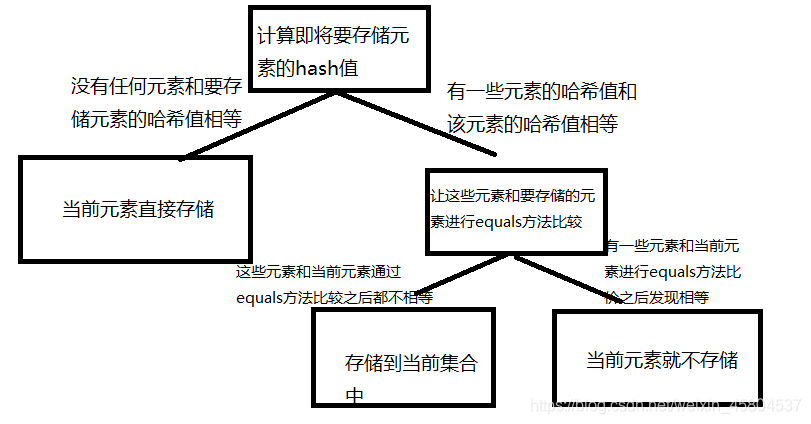
1、HashSet 集合存储一个obj对象的时候,首先计算obj对象的hashcode值
2、在集合中的所有的元素的哈希值,都和obj的hashcode值,说明集合中不存在Obj,可以直接将obj存储到集合中
3、在集合中有若干个元素的哈希值,和obj的哈希值相同,并不能说明obj已经存在于集合中,需要使用equals方法判断obj时候和那些与自己相同的哈希值的元素是否相等
4、如果在equals方法和obj元素比较之后,发现都不相等,那么就说明obj不存在与这个集合,可以将obj存储到hashset中
5、如果在equals方法和obj元素比较之后,发现相等,obj已经存在于集合中,obj就不存储了
1、重写HashCode()方法
根据属性值,生成哈希值
不同的属性值,尽量生成不同的整数
相同的属性值,一定会生成相同的整数
2、重写equals方法
比较的就是属性值
3、操作
alt+shift + s
h
生成hashcode方法和equals方法
package com. ujiuye. demos ;
public class Person {
private String name;
private int age;
public Person ( ) {
}
public Person ( String name, int age) {
super ( ) ;
this . name = name;
this . age = age;
}
@Override
public int hashCode ( ) {
System . out. println ( "hashCode方法执行了" ) ;
final int prime = 31 ;
int result = 1 ;
result = prime * result + age;
result = prime * result + ( ( name == null ) ? 0 : name. hashCode ( ) ) ;
return result;
}
@Override
public boolean equals ( Object obj) {
System . out. println ( "equals方法执行了" ) ;
if ( this == obj)
return true ;
if ( obj == null )
return false ;
if ( getClass ( ) != obj. getClass ( ) )
return false ;
Person other = ( Person ) obj;
if ( age != other. age)
return false ;
if ( name == null ) {
if ( other. name != null )
return false ;
} else if ( ! name. equals ( other. name) )
return false ;
return true ;
}
public String getName ( ) {
return name;
}
public void setName ( String name) {
this . name = name;
}
public int getAge ( ) {
return age;
}
public void setAge ( int age) {
this . age = age;
}
@Override
public String toString ( ) {
return "Person [name=" + name + ", age=" + age + "]" ;
}
}
package com. ujiuye. demos ;
import java. util. HashSet ;
public class Demo_3 {
public static void main ( String [ ] args) {
HashSet < Person > = new HashSet < > ( ) ;
hs. add ( new Person ( "张三丰" , 90 ) ) ;
hs. add ( new Person ( "张三丰" , 90 ) ) ;
hs. add ( new Person ( "张无忌" , 30 ) ) ;
hs. add ( new Person ( "赵敏" , 20 ) ) ;
hs. add ( new Person ( "赵敏" , 20 ) ) ;
hs. add ( new Person ( "灭绝师太" , 190 ) ) ;
System . out. println ( hs) ;
}
}
1、是HashSet的一个子类,和HashSet保证元素唯一性的原理相同
2、将来每个元素在存储的时候,都记录了前后元素的地址
3、效果:
可以根据存储元素的顺序,将元素取出
4、应用:
既需要保证元素的唯一,又需要保证原来的顺序,就可以考虑LinedHashSet
package com. ujiuye. demos ;
import java. util. LinkedHashSet ;
public class Demo_5 {
public static void main ( String [ ] args) {
LinkedHashSet < String > = new LinkedHashSet < String > ( ) ;
lhs. add ( "java" ) ;
lhs. add ( "java" ) ;
lhs. add ( "C" ) ;
lhs. add ( "C++" ) ;
lhs. add ( "C++" ) ;
lhs. add ( "C#" ) ;
System . out. println ( lhs) ;
LinkedHashSet < Person > = new LinkedHashSet < > ( ) ;
lhs1. add ( new Person ( "王思聪" , 31 ) ) ;
lhs1. add ( new Person ( "王健林" , 31 ) ) ;
lhs1. add ( new Person ( "郭美美" , 31 ) ) ;
lhs1. add ( new Person ( "郭美美" , 31 ) ) ;
lhs1. add ( new Person ( "凤姐" , 31 ) ) ;
lhs1. add ( new Person ( "凤姐" , 31 ) ) ;
System . out. println ( lhs1) ;
}
}
1、是双列集合的顶层接口
2、Map:地图
3、Map:映射,描述的就是将一个数据(key)到另一个数据(value)的映射关系(对应关系)
一个数据(key):容易记忆的,有规律的,简单的数据
另一个数据(value):没有规律,不容易记忆的,复杂的数据
大多数都是通过key操作value
4、映射:对应关系
函数:y = x * x 特点:x是不会重复的 key
平方 y会重复的 value
x -----> y
1 1
2 4
3 9
4 16
5、java中map就是使用穷举罗列的方式描述映射关系
6、map的特点
key(键) 是唯一的,不能重复的
value(值)不是唯一的,可以重复
7、Map和Collection的区别
Map是双列集合,Collection单列集合
Map的键是唯一的,Collection中set子接口中的元素是唯一的
Map中大多数方法都是操作键的,Collection中set子接口中的操作对元素有效
1、增加键值对(向map集合中添加数据)
put(K key,V value)
2、删除方法
根据给定的值,删除对应的键值对:remove(k key)
clear(); 清空
3、获取方法
get(k key)获取键所对应的的value值
size()返回map集合中所有的键值对的个数
4、判断方法
containsKey(Object key) 判断集合中是否包含key这个键
containsValue(Object value) 判断集合中是否包含value这个值
5、修改方法
根据给定的键,修改对应的值:put(k key,v value)
如果在集合中已经存在key这个键,那么使用put方法,就是修改这个键对应的value值
如果在集合中不存在key这个键,那么使用put方法,就是向map集合重添加数据
package com. ujiuye. demos ;
import java. util. HashMap ;
import java. util. Map ;
public class Demo_6 {
public static void main ( String [ ] args) {
Map < String , String > = new HashMap < > ( ) ;
map. put ( "瞎子" , "李青" ) ;
map. put ( "瞎子" , "李青" ) ;
map. put ( "盲僧" , "李青" ) ;
map. put ( "托儿索" , "亚索" ) ;
map. put ( "快乐风男" , "亚索" ) ;
map. put ( "望远烬" , "烬" ) ;
map. put ( "望远烬" , "烬" ) ;
System . out. println ( map) ;
map. remove ( "望远烬" ) ;
System . out. println ( map) ;
System . out. println ( map. size ( ) ) ;
System . out. println ( map. get ( "盲僧" ) ) ;
System . out. println ( map. containsKey ( "李青" ) ) ;
System . out. println ( map. containsKey ( "盲僧" ) ) ;
System . out. println ( map. containsValue ( "李青" ) ) ;
map. put ( "奥斑马" , "卢锡安" ) ;
System . out. println ( map) ;
map. put ( "瞎子" , "李青2号" ) ;
System . out. println ( map) ;
}
}
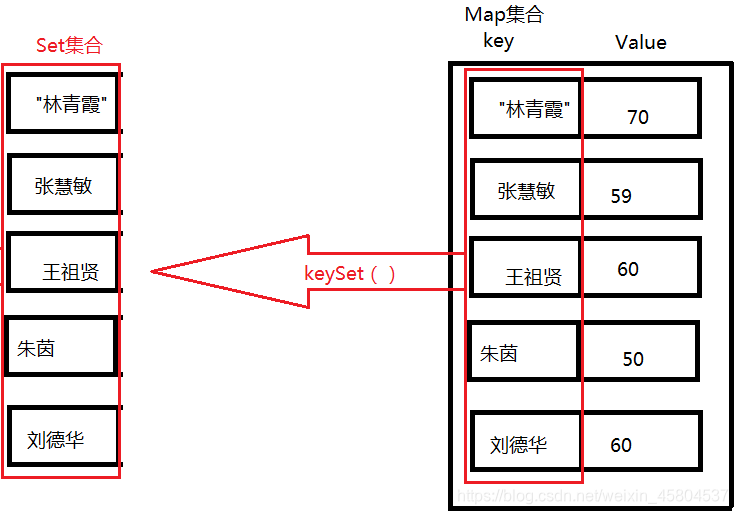
1、获取Map集合中所有的键,放到一个set集合中,遍历set集合,获取每一个键,根据键再来获取对应的值【根据键获取对应的值】
2、获取Map集合中所有的键
keySet()
3、遍历Set集合拿到map集合中所有的键了
遍历Set集合:
增强for
迭代器
4、拿到每个键之后,通过get(K key)获取键对应的值
5、特点;
获取了所有键的set集合后,要依赖于原来的map集合
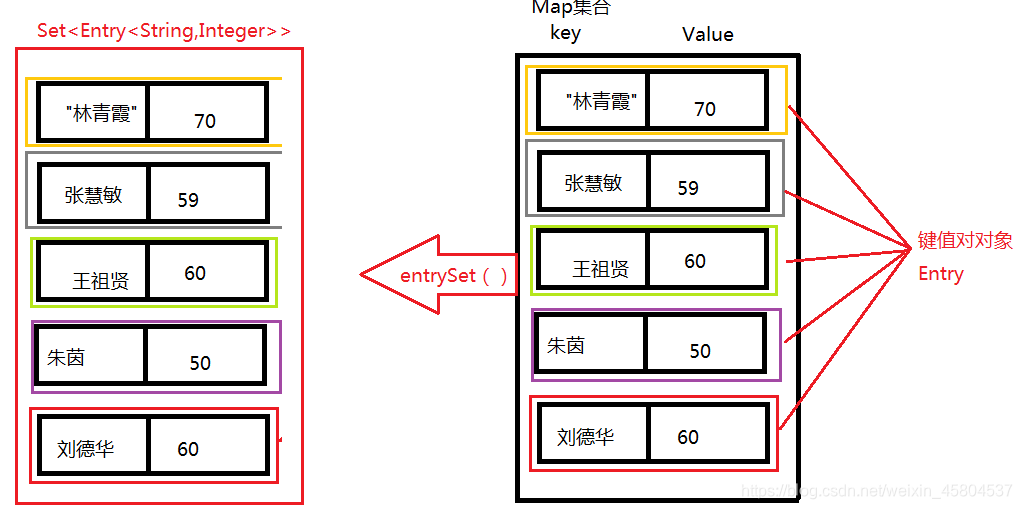
1、获取的是Map集合中所有的键值对对象(Entry), 到set集合中,遍历set集合,拿到的是每一个键值对对象(Entry),从这个对象中获取键和值
2、根据Map集合方法可以获取所有键值对对象到一个Set集合中
Set<Map.Entry<K,V>> entrySet()
3、遍历Set集合
迭代器
增强for
4、获取到的就是一个键值对对象
Entry是Map接口中的内部接口,访问方式:Map.Entry
Entry常用的方法
getKey()获取的是键值对中的键
getValue()获取的是键值对中的值
package com. ujiuye. demos ;
import java. util. HashMap ;
import java. util. Iterator ;
import java. util. Map ;
import java. util. Map. Entry ;
import java. util. Set ;
public class Demo_8 {
public static void main ( String [ ] args) {
Map < String , Integer > = new HashMap < > ( ) ;
map. put ( "林青霞" , 70 ) ;
map. put ( "张慧敏" , 59 ) ;
map. put ( "王祖贤" , 60 ) ;
map. put ( "朱茵" , 50 ) ;
map. put ( "刘德华" , 60 ) ;
System . out. println ( map) ;
Set < Map. Entry < String , Integer > > = map. entrySet ( ) ;
for ( Map. Entry < String , Integer > : entrySet) {
System . out. println ( entry. getKey ( ) + " = " + entry. getValue ( ) ) ;
}
}
}
1、就是Map集合中使用哈希表存储方式的一种实现类
2、HashMap存储jdk中提供的元素类型的键,直接保证元素的唯一性
3、HashMap存储的键值对中的键是自定义类型元素的时候,无法保证元素的唯一性,要保证自定义元素的唯一性也需要重写hashCode和equals方法
保证键的唯一性和HashSet保证元素唯一性的原理是一样的
4、HashMap和HashSet的关系
HashSet是HashMap实现出来的,HashSet就是HashMap键的那一列
将HashMap值的那一列隐藏掉就成HashSet
package com. ujiuye. demos ;
import java. util. HashMap ;
import java. util. HashSet ;
public class Demo_9 {
public static void main ( String [ ] args) {
HashMap < Person , String > = new HashMap < Person , String > ( ) ;
hm. put ( new Person ( "张三" , 13 ) , "成都" ) ;
hm. put ( new Person ( "张三" , 13 ) , "成都" ) ;
hm. put ( new Person ( "李四" , 103 ) , "北京" ) ;
hm. put ( new Person ( "李四" , 103 ) , "北京" ) ;
hm. put ( new Person ( "王五" , 25 ) , "武汉" ) ;
System . out. println ( hm) ;
}
}
1、是HashMap的一个子类
2、和HashMap的不同之处,具有可预知的迭代顺序,存储键值对的顺序和遍历集合时取出的顺序时的键值对的顺序一致。
package com. ujiuye. demos ;
import java. util. LinkedHashMap ;
import java. util. Map. Entry ;
import java. util. Set ;
public class Demo_10 {
public static void main ( String [ ] args) {
LinkedHashMap < Person , String > = new LinkedHashMap < > ( ) ;
lhm. put ( new Person ( "张三" , 13 ) , "成都" ) ;
lhm. put ( new Person ( "张三" , 13 ) , "成都" ) ;
lhm. put ( new Person ( "李四" , 103 ) , "北京" ) ;
lhm. put ( new Person ( "李四" , 103 ) , "北京" ) ;
lhm. put ( new Person ( "王五" , 25 ) , "武汉" ) ;
System . out. println ( lhm) ;
Set < Entry < Person , String > > = lhm. entrySet ( ) ;
for ( Entry < Person , String > : entrySet) {
System . out. println ( entry. getKey ( ) ) ;
System . out. println ( entry. getValue ( ) ) ;
}
}
}
1、binarySearch(List<? extends Comparable<? super T>> list, T key)
在一个升序的List集合中,通过二分查找寻找Key对应的索引
2、frequency(Collection<?> c, Object o)
返回指定 collection 中等于指定对象的元素数。
3、replaceAll(List<T> list, T oldVal, T newVal)
使用另一个值替换列表中出现的所有某一指定值。
4、reverse(List<?> list)
反转指定列表中元素的顺序
5、shuffle(List<?> list)将list集合中的元素进行随机置换,打乱
6、sort(List<T> list) 将list集合中的元素进行自然排序
7、synchronizedxxx方法系列:将一个线程不安全的集合传入方法,返回一个线程安全的集合
8、unmodifiablexxx方法系列:将一个可修改的集合传入方法,返回一个只可读的集合
package com. ujiuye. demos ;
import java. util. ArrayList ;
import java. util. Collection ;
import java. util. Collections ;
import java. util. List ;
public class Demo_11 {
public static void main ( String [ ] args) {
List < Integer > = new ArrayList < Integer > ( ) ;
list. add ( 1 ) ;
list. add ( 2 ) ;
list. add ( 2 ) ;
list. add ( 2 ) ;
list. add ( 3 ) ;
list. add ( 3 ) ;
list. add ( 3 ) ;
list. add ( 4 ) ;
List < String > = new ArrayList < String > ( ) ;
list1. add ( "a" ) ;
list1. add ( "b" ) ;
list1. add ( "c" ) ;
list1. add ( "d" ) ;
System . out. println ( list1) ;
int binarySearch = Collections . binarySearch ( list, 2 ) ;
System . out. println ( binarySearch) ;
int frequency = Collections . frequency ( list, 3 ) ;
System . out. println ( frequency) ;
System . out. println ( Collections . max ( list1) ) ;
System . out. println ( "----------------------------------" ) ;
List < String > = new ArrayList < String > ( ) ;
list2. add ( "a" ) ;
list2. add ( "b" ) ;
list2. add ( "c" ) ;
list2. add ( "c" ) ;
list2. add ( "c" ) ;
list2. add ( "d" ) ;
Collections . replaceAll ( list2, "c" , "java" ) ;
System . out. println ( list2) ;
Collections . reverse ( list1) ;
System . out. println ( list1) ;
Collections . shuffle ( list2) ;
System . out. println ( list2) ;
Collections . shuffle ( list1) ;
System . out. println ( list1) ;
Collections . sort ( list1) ;
System . out. println ( list1) ;
List < Integer > = Collections . unmodifiableList ( list) ;
System . out. println ( "newList: " + newList) ;
}
}





 本文深入讲解Java集合框架,包括Set集合的特点与实现类HashSet、Map集合的双列特性及其实现类HashMap,探讨集合的遍历方法与工具类Collections的功能。
本文深入讲解Java集合框架,包括Set集合的特点与实现类HashSet、Map集合的双列特性及其实现类HashMap,探讨集合的遍历方法与工具类Collections的功能。

















 1153
1153



 到【灌水乐园】发言
到【灌水乐园】发言








