







 本文通过PyTorch实现了一个LSTM模型来预测股票价格,利用tushare获取平安银行的历史数据,经过数据处理,构建训练和测试集。模型训练200轮后,观察到损失在50轮左右收敛。最后,模型对未来7天的股票价格进行了预测。
本文通过PyTorch实现了一个LSTM模型来预测股票价格,利用tushare获取平安银行的历史数据,经过数据处理,构建训练和测试集。模型训练200轮后,观察到损失在50轮左右收敛。最后,模型对未来7天的股票价格进行了预测。
前言
本文通过LSTM来对股票未来价格进行预测,并介绍一下数据获取、处理,pytorch的模型搭建和训练等等。
数据获取
这里我使用tushare的接口来获取平安银行(000001.SZ)股票的历史10年的数据
import tushare as ts
pro = ts.pro_api('your token')
df = pro.daily(ts_code='000001.SZ', start_date='20130711', end_date='20220711')
由于本文只用到股票的开盘价、收盘价、最高价、最低价,所以只用到了一个接口,tushare除了这个接口以外还有许多数据接口,感兴趣的读者可以去Tushare大数据社区查询。
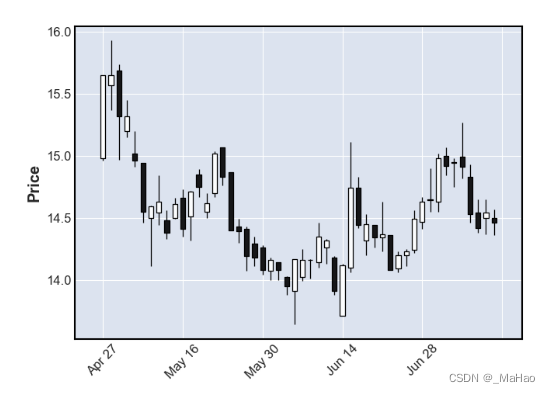
用mplfinance库绘制一下获取的数据
import pandas as pd
import mplfinance as mpf
df.index=pd.to_datetime(df.trade_date)#索引转为日期
df = df.iloc[::-1]#由于获取的数据是倒序的,需要将其调整为正序
mpf.plot(df[-50:],type='candle')#绘制最近50天的数据绘制结果如下
数据处理
我们需要使用历史200天的数据来预测未来7天的数据,所以接下来需要对获取到的数据进行处理
dataX=[]#属性
dataY=[]#标签
k=0
tempX=[]#储存某个历史200天数据
tempY=[]#储存某个未来7天数据
for index, rows in df.iterrows():
if k<200:
k+=1
tempX.append([rows['open'],rows['close'],rows['high'],rows['low']])
continue
if k<207:
k+=1
tempY.append([rows['open'],rows['close'],rows['high'],rows['low']])
continue
dataX.append(tempX[:])
dataY.append(tempY[:])
tempX=tempX[1:]+tempY[:1]
tempY=tempY[1:]
tempY.append([rows['open'],rows['close'],rows['high'],rows['low']])
dataX.append(tempX[:])#加上最后一项
dataY.append(tempY[:])#加上最后一项这样我们就得到两个一一对应的列表,dataX对应某个时间节点的历史200天数据,dataY则是该时间节点的未来7天数据,接下来将他们划分为训练集和测试集,并转化为DataLoader
import torch
import torch.utils.data as Data
dataX=torch.tensor(dataX)#列表转Tensor
dataY=torch.tensor(dataY)#列表转Tensor
dataset=Data.TensorDataset(dataX,dataY)
train_size=int(0.8*len(dataset))
test_size=len(dataset)-train_size
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])#以8:2比例划分训练集和测试集
train_loader = Data.DataLoader(
dataset=train_dataset,
batch_size=64,
shuffle=True
)
test_loader = Data.DataLoader(
dataset=test_dataset,
batch_size=64,
shuffle=True
)模型搭建
我们使用torch.nn中的LSTM来作为预测模型
LSTM参数介绍如下
-
input_size:输入x的特征数量
-
hidden_size:隐藏层h的特征数量
-
num_layers:隐藏层层数
-
bias:是否使用偏置,默认为:True
-
batch_first:若为True,则输入形状为(batch, seq, feature),否则为(seq, batch,feature),默认为False
-
dropout: 如果非零,则在除最后一层之外的每个LSTM层的输出上引入Dropout层,概率等于dropout
-
bidirectional:若为True,则表示该LSTM为双向的
-
proj_size:若大于0,将使用具有相应大小的投影的LSTM,默认为0
搭建的模型如下
from torch.nn import LSTM,Module,Linear
class MyModel(Module):
def __init__(self):
super(MyModel,self).__init__()
self.lstm=LSTM(input_size=4,hidden_size=4,num_layers=2,batch_first=True)
self.linear=Linear(800,28)#将结果映射到7天的数据
def forward(self,x):
return self.linear(self.lstm(x)[0].reshape(-1,800))
模型训练
使用均方误差作为损失函数,Adam为优化器训练200轮
import torch.nn.functional as F
model=MyModel()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
lossList=[]#记录训练loss
lossListTest=[]#记录测试loss
for epoch in range(200):
loss_nowEpoch=[]
model.train()
for step, (batch_x, batch_y) in enumerate(train_loader):
out=model(batch_x)#模型输入
Loss = F.mse_loss(out,batch_y.view(-1,28))#loss计算,将batch_y从(64,7,4)变形为(64,28)
optimizer.zero_grad()#当前batch的梯度不会再用到,所以清除梯度
Loss.backward()#反向传播计算梯度
optimizer.step()#更新参数
loss_nowEpoch.append(Loss.item())
break
lossList.append(sum(loss_nowEpoch)/len(loss_nowEpoch))
loss_nowEpochTest = []
model.eval()
for step, (batch_x, batch_y) in enumerate(test_loader):
out = model(batch_x)
Loss = F.mse_loss(out, batch_y.view(-1, 28)) # 将batch_y从(64,7,4)变形为(64,28)
loss_nowEpochTest.append(Loss.item())
break
lossListTest.append(sum(loss_nowEpochTest)/len(loss_nowEpochTest))
print(">>> EPOCH{} averTrainLoss:{:.3f} averTestLoss:{:.3f}".format(epoch+1, lossList[-1],lossListTest[-1]))
绘制loss的下降图
import matplotlib.pyplot as plt
plt.plot(list(range(200)),lossList,label='Train')
plt.plot(list(range(200)),lossListTest,label='Test')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()loss下降图如下
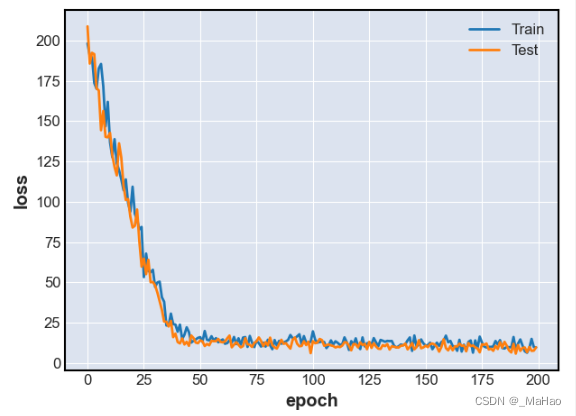
可以看到在50轮左右其实就收敛了
再根据最近200天来预测未来7天的数据
X=torch.tensor(df[['open','close','high','low']][-200:].to_numpy())
Y=model(X.view(1,200,4).float()).reshape(7,4)
result=pd.DataFrame(torch.vstack((X,Y)).detach().numpy())
result.index=list(df.index[-200:])+[pd.Timestamp('2022-07-12 00:00:00'),pd.Timestamp('2022-07-13 00:00:00'),
pd.Timestamp('2022-07-14 00:00:00'),pd.Timestamp('2022-07-15 00:00:00'),
pd.Timestamp('2022-07-18 00:00:00'),pd.Timestamp('2022-07-19 00:00:00'),
pd.Timestamp('2022-07-20 00:00:00')]
result.columns=['open','close','high','low']
mpf.plot(result[-21:],type='candle') 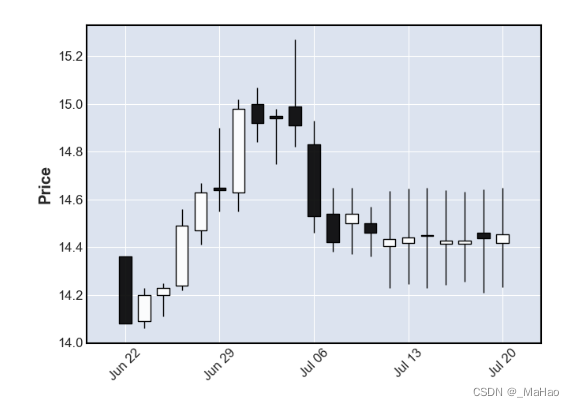
后七天即为未来七天的预测结果

















 2361
2361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









