










 论文介绍了一种名为RefConv的新型卷积层,通过重新参数化和重新聚焦提升CNN的表现力,无需额外成本,实验证明在多项任务中效果显著,减少了冗余参数和优化难度。
论文介绍了一种名为RefConv的新型卷积层,通过重新参数化和重新聚焦提升CNN的表现力,无需额外成本,实验证明在多项任务中效果显著,减少了冗余参数和优化难度。
论文地址: http://arxiv.org/pdf/2310.10563.pdf
源码地址:GitHub - Aiolus-X/RefConv
概述:
作者提出了一种可重参数化的重新聚焦卷积(RefConv),作为常规卷积层的即插即用替代品,能够在不引入额外推理成本的情况下显著提高基于CNN的模型性能。RefConv利用预训练参数编码的表示作为先验,通过重新聚焦这些参数来学习新的表示,进一步增强了模型结构的先验,提升了预训练模型的表示能力。实验证明,RefConv在图像分类、目标检测和语义分割等任务中表现出色,并能够减少通道冗余、平滑损失景观,从而解释了其有效性。
作者首先将预训练好的卷积模型的卷积层替换为重参数化重聚焦卷积 (RefConv),如图1所示。
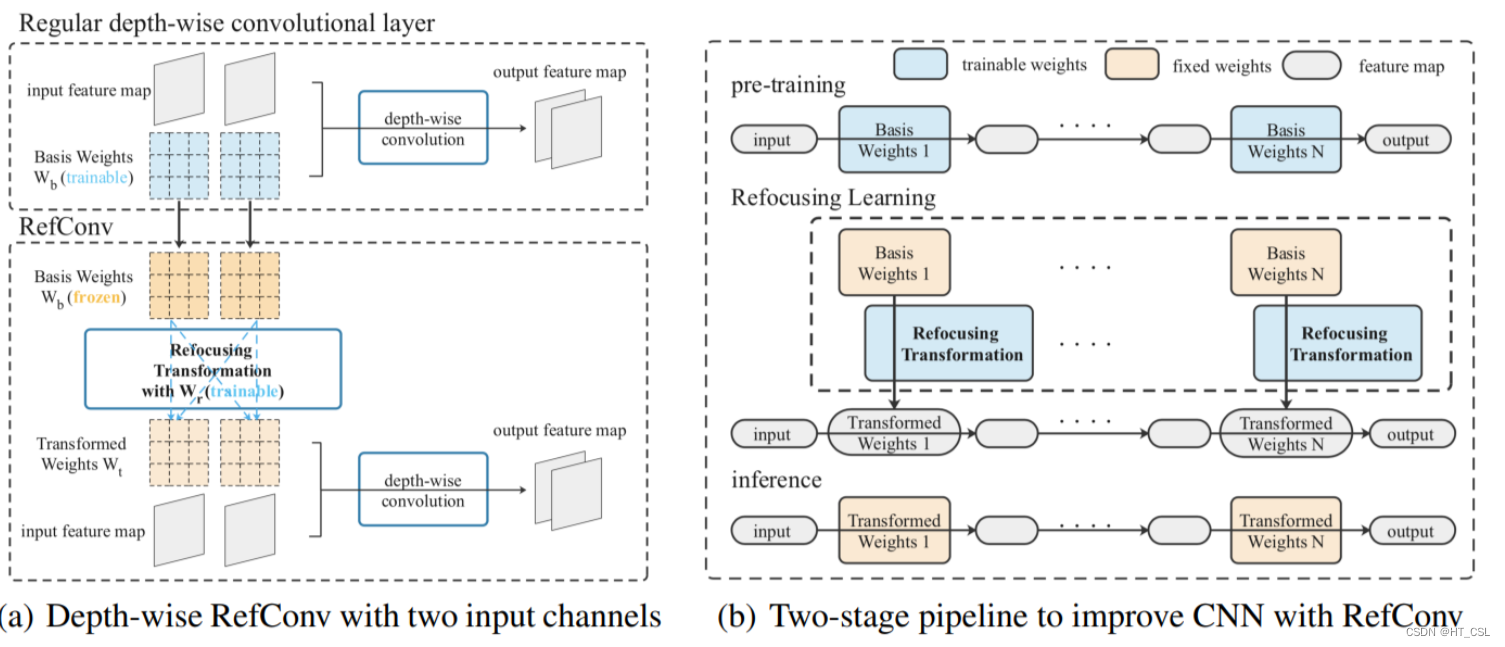
RefConv的核心理念:
通过重新参数化和重新聚焦来增强卷积神经网络的特征提取能力。简单来说,它让网络更聪明地学习如何处理复杂的数据,从而在各种计算机视觉任务中表现更出色。它通过在卷积核之间建立额外的联系来提升模型的先验知识。RefConv是一种方便的模块,可以直接插入到现有模型中,而无需改变模型的结构或增加额外的计算成本,就可以明显提高模型的性能。此外,论文还指出,RefConv有助于减少模型中不必要的参数和优化过程中的损失函数,这进一步证明了它的有效性。这些发现可能会引发更多关于训练模型时的动态理论方面的研究。
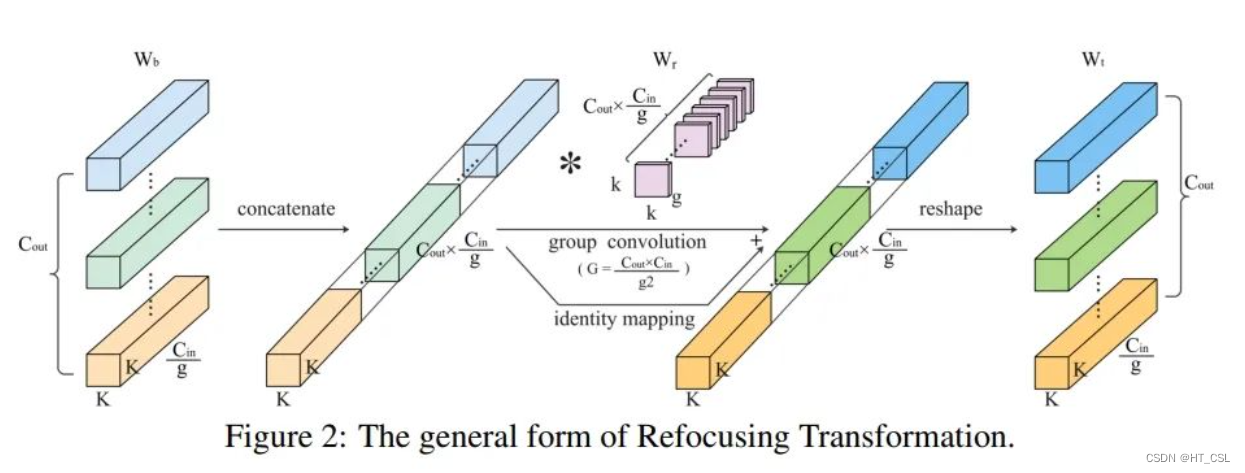
在传统的卷积神经网络中,卷积核的权重是固定的,只是在训练过程中微调。但RefConv却有所不同,它引入了额外的参数来调整这些权重,让每个卷积核可以学到更多不同的特征。这种重新参数化的方法让网络能够更灵活地对输入特征做出反应,而且不会增加太多计算成本。
Pytorch源码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class RepConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding=None, groups=1,
map_k=3):
super(RepConv, self).__init__()
assert map_k <= kernel_size
# 记录原始卷积核形状
self.origin_kernel_shape = (out_channels, in_channels // groups, kernel_size, kernel_size)
self.register_buffer('weight', torch.zeros(*self.origin_kernel_shape))
G = in_channels * out_channels // (groups ** 2)
self.num_2d_kernels = out_channels * in_channels // groups
self.kernel_size = kernel_size
# 使用 2D 卷积生成映射
self.convmap = nn.Conv2d(in_channels=self.num_2d_kernels,
out_channels=self.num_2d_kernels, kernel_size=map_k, stride=1, padding=map_k // 2,
groups=G, bias=False)
self.bias = None
self.stride = stride
self.groups = groups
if padding is None:
padding = kernel_size // 2
self.padding = padding
def forward(self, inputs):
# 生成权重矩阵
origin_weight = self.weight.view(1, self.num_2d_kernels, self.kernel_size, self.kernel_size)
# 使用卷积映射更新权重
kernel = self.weight + self.convmap(origin_weight).view(*self.origin_kernel_shape)
return F.conv2d(inputs, kernel, stride=self.stride, padding=self.padding, dilation=1, groups=self.groups, bias=self.bias)
class RepConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(RepConvBlock, self).__init__()
# 定义 RepConv 模块
self.conv = RepConv(in_channels, out_channels, kernel_size=3, stride=stride, padding=None, groups=1, map_k=3)
# 批量归一化层
self.bn = nn.BatchNorm2d(out_channels)
# 激活函数
self.act = Hswish()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x
class Hswish(nn.Module):
def __init__(self, inplace=True):
super(Hswish, self).__init__()
self.inplace = inplace
def forward(self, x):
# H-swish 激活函数
return x * F.relu6(x + 3., inplace=self.inplace) / 6.
# 测试模块
if __name__ == "__main__":
# 创建 RepConvBlock 实例并进行前向传播测试
block = RepConvBlock(in_channels=3, out_channels=64, stride=1)
x = torch.randn(1, 3, 224, 224)
output = block(x)
print("Output shape:", output.shape)

















 1005
1005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









