







 本文详细介绍了如何在Spark和Hive环境中使用Delta Lake表。首先,讲解了Spark SQL创建和操作Delta表的步骤,包括增、删、改、查以及历史记录查看。接着,重点阐述了如何配置Hive以映射和读取Delta表,涉及Hive的jar包依赖、环境配置、临时与永久读取方式设置,以及可能出现的异常处理。最后,通过实例验证了Hive映射表的成功与一致性。
本文详细介绍了如何在Spark和Hive环境中使用Delta Lake表。首先,讲解了Spark SQL创建和操作Delta表的步骤,包括增、删、改、查以及历史记录查看。接着,重点阐述了如何配置Hive以映射和读取Delta表,涉及Hive的jar包依赖、环境配置、临时与永久读取方式设置,以及可能出现的异常处理。最后,通过实例验证了Hive映射表的成功与一致性。
Hive映射Delta表以及Spark3-sql操作DL表
参考:git源码,连接器
jar包:delta-hive-assembly_2.11-0.2.0.jar,delta-hive-assembly_2.12-0.2.0.jar,hive-delta_2.11-0.1.0.jar
我们使用Spark操作DL表很方便,但是想更方便的用Hive去查看DL表,怎么做呢?经过测试趟坑,总结以下文章。
以下文章分两部分,测试了Spark-sql对DL表的操作。还有Hive映射DL表。
各位大牛转载的请备注我的链接地址
一、集群环境
| 组件 | 版本 |
|---|---|
| HDFS | 2.8.4 |
| Hive | 2.3.2 |
| Spark | 3.0.0 |
| Scala | 2.11.10 |
| DeltaLake | 0.7.0 |
注意事项:
1、版本支持Hive2.X,该jar包连接器只能与Apache Hive使用,不支持spark和persto。
2、如果Hive连接器直接创建DL的表,Spark和Presto查不到。
3、使用该jar包Hive不支持写入Delta表。
4、该连接器的hive支持mapreduce和tez引擎。hive on spark不支持。
5、创建hive表映射后,使用Spark更改基础的Delta表,需要Hive删除映射表后再重新映射。
6、Hive映射表必须是外表。
7、必须使用Spark3,如果你是Spark1或者Spark2的,不知道怎么安装spark双环境的。请参考我之前博客,传送门已准备好了:传送门
二、前置工作
准备数据
Spark-sql进行建表,然后Hive进行映射测试。
1、将spark-delta的 delta-core_2.12-0.7.0.jar 包拷贝到$SPARK3_HOME/jars下。
delta-core_2.12-0.7.0.jar 包找不到?没关系,粉丝福利下载地址:delta-core_2.12-0.7.0.jar
2、启动
启动需要注意必须加上参数,否则异常:
spark3-sql \
--master yarn \
--conf spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension \
--conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog \
--conf spark.databricks.delta.commitInfo.userMetadata=overwritten-for-fixing-incorrect-data
3、建表
spark-sql:
CREATE TABLE test.delta (
id int,
rn int,
flag int
)
USING DELTA;
其他功能测试
4、插入数据
spark-sql: insert into table test.delta values(1,2,3);
5、删
spark-sql: delete from test.delta where id=1
6、改
spark-sql: update test.delta set flag=33 where id=1
7、merge 数据如下:
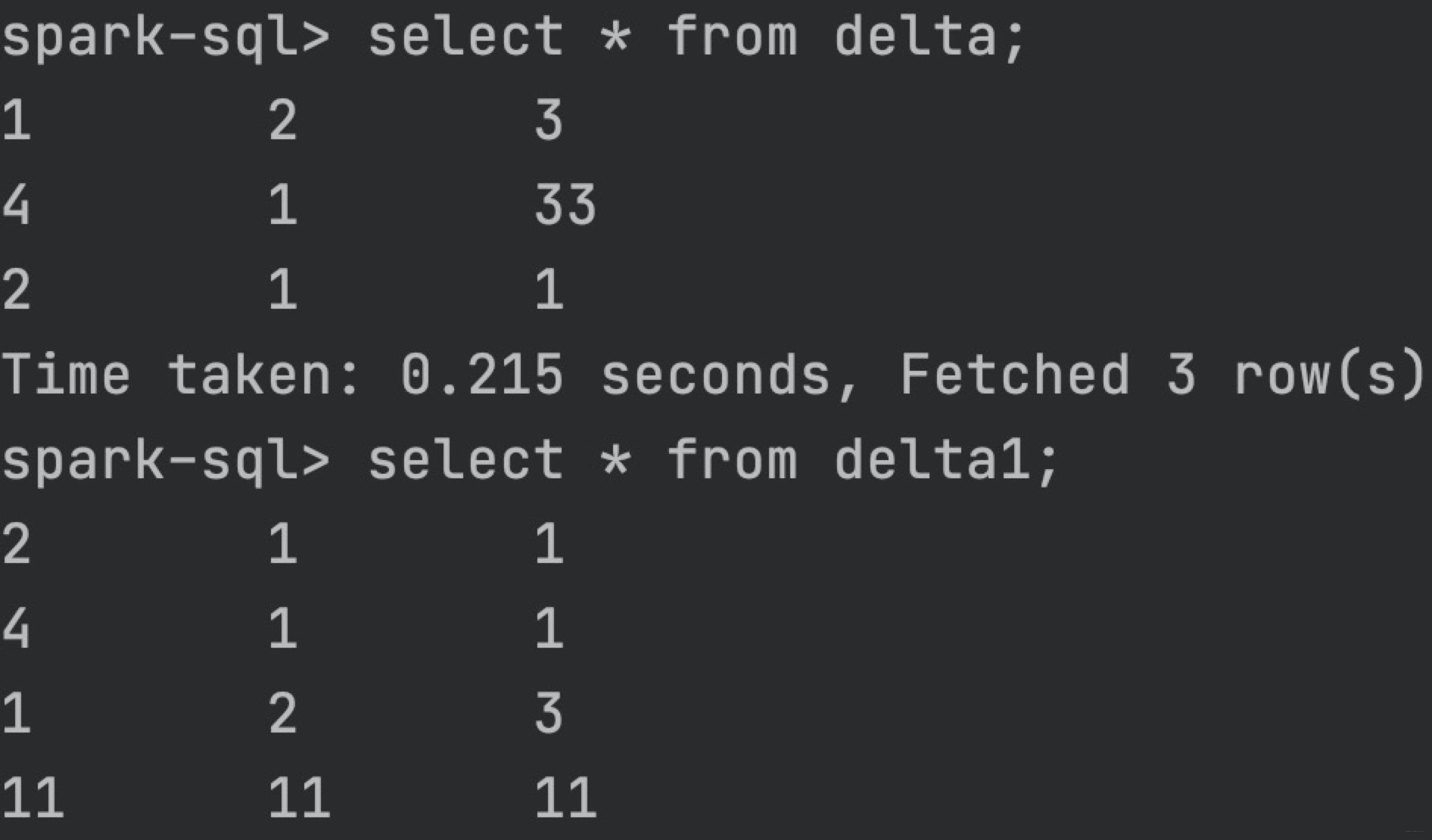
MERGE INTO delta
USING delta1
ON delta.id= delta1.id
WHEN MATCHED THEN
UPDATE SET delta.rn = delta.rn
WHEN NOT MATCHED
THEN INSERT (id,rn,flag) VALUES (id,rn,flag)
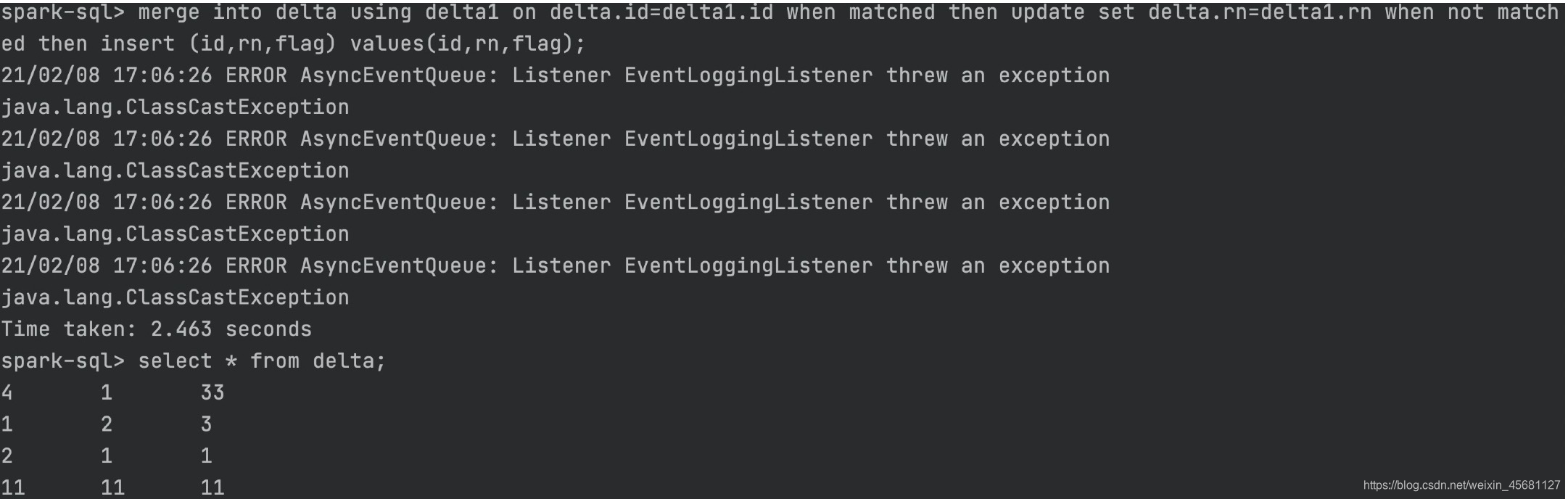
8、流写入(代码去我之前博客找)
9、查看历史
spark-sql>describe history test.delta;

增、删、改、merge都已经通过验证
2.读入数据
映射步骤:
1、依赖包及环境配置
1.1 将下载好的jar包放到hive的jars目录下,
1.2 或者 放到HIVE_AUX_JARS目录下。然后指定hive去识别位置。以下两种识别方法。
1.2.1 需要在hive-site.xml中配置位置(重新启动时会加载配置,从而重新加载新加入的jar包)。
<property>
<name>hive.aux.jars.path</name>
<value>path_to_uber_jar</value>
</property>
1.2.2 或者 新增到 hive-env.sh中环境变量位置,让hive知道去哪里找。
export HIVE_AUX_JARS_PATH= path_to_uber_jar
当然,1.2.1 和 1.2.2 俩配置二选一
2、更改读取方式:临时或者永久
临时:
SET hive.input.format=io.delta.hive.HiveInputFormat;
SET hive.tez.input.format=io.delta.hive.HiveInputFormat;
永久:更改配置文件 hive-site.xml
<property>
<name>hive.input.format</name>
<value>io.delta.hive.HiveInputFormat</value>
</property>
<property>
<name>hive.tez.input.format</name>
<value>io.delta.hive.HiveInputFormat</value>
</property>
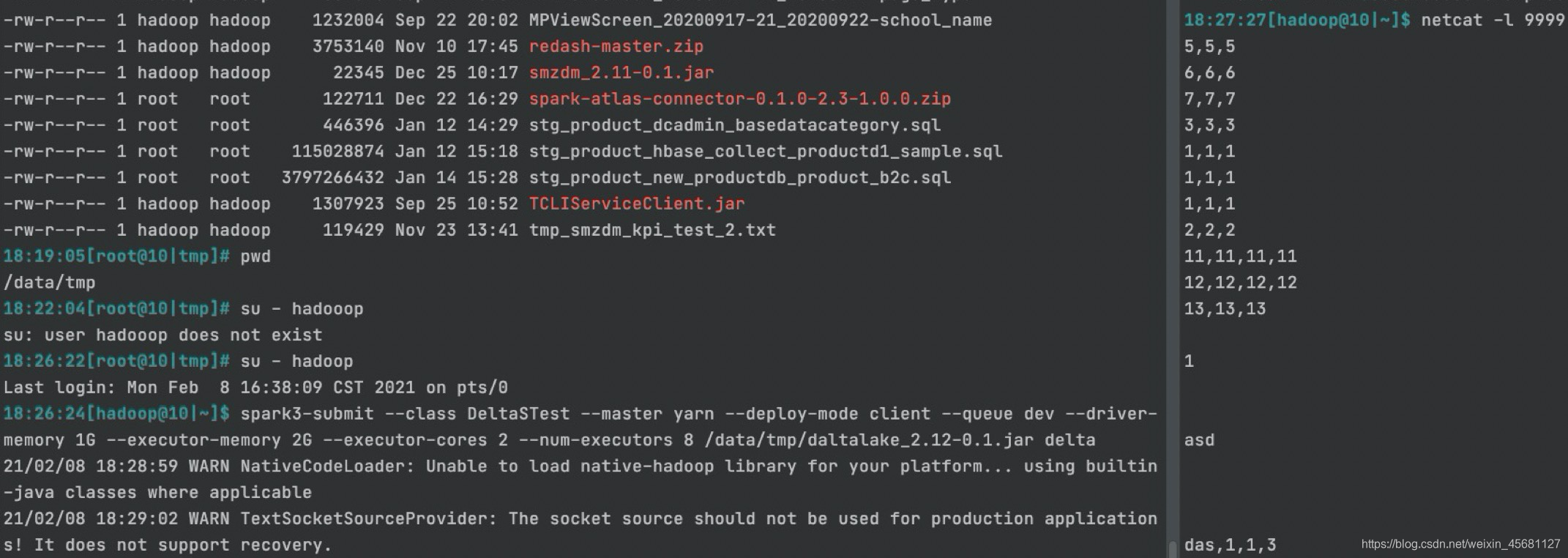
2.1、如果没有在auxlib中。可以直接在hive-client中指定加载依赖包
$ hive> ADD JAR <path-to-jar>;
例如:
$ hive> add jars file:///usr/local/service/hive/auxlib/delta-hive-assembly_2.12-0.2.0.jar;
3、建表测试,目前jar包只支持外部Hive表。
CREATE EXTERNAL TABLE test.Edelta(
id int,
name string,
pt string)
STORED BY ‘io.delta.hive.DeltaStorageHandler’
LOCATION ‘/delta/table/path’
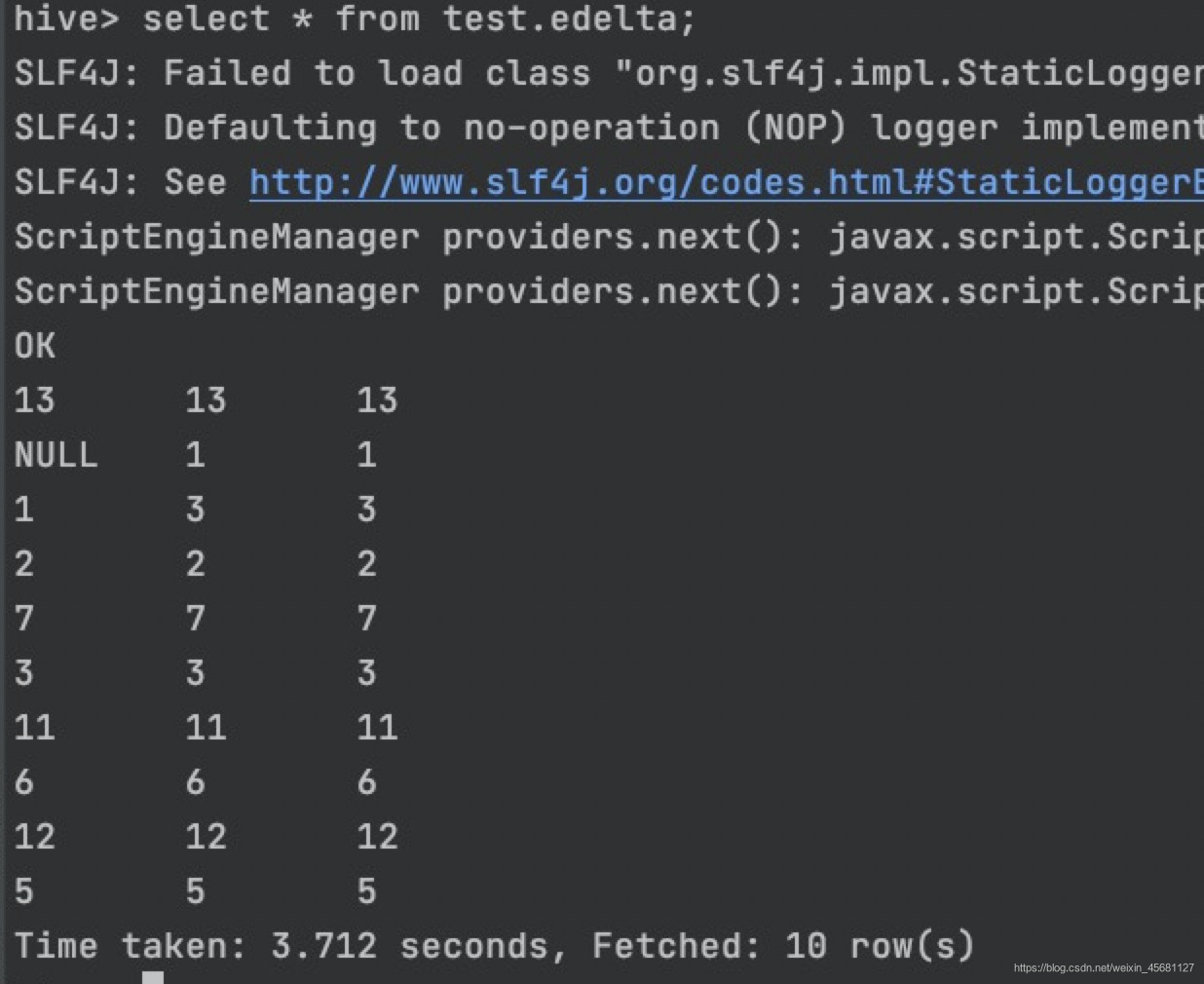
4、查询映射表
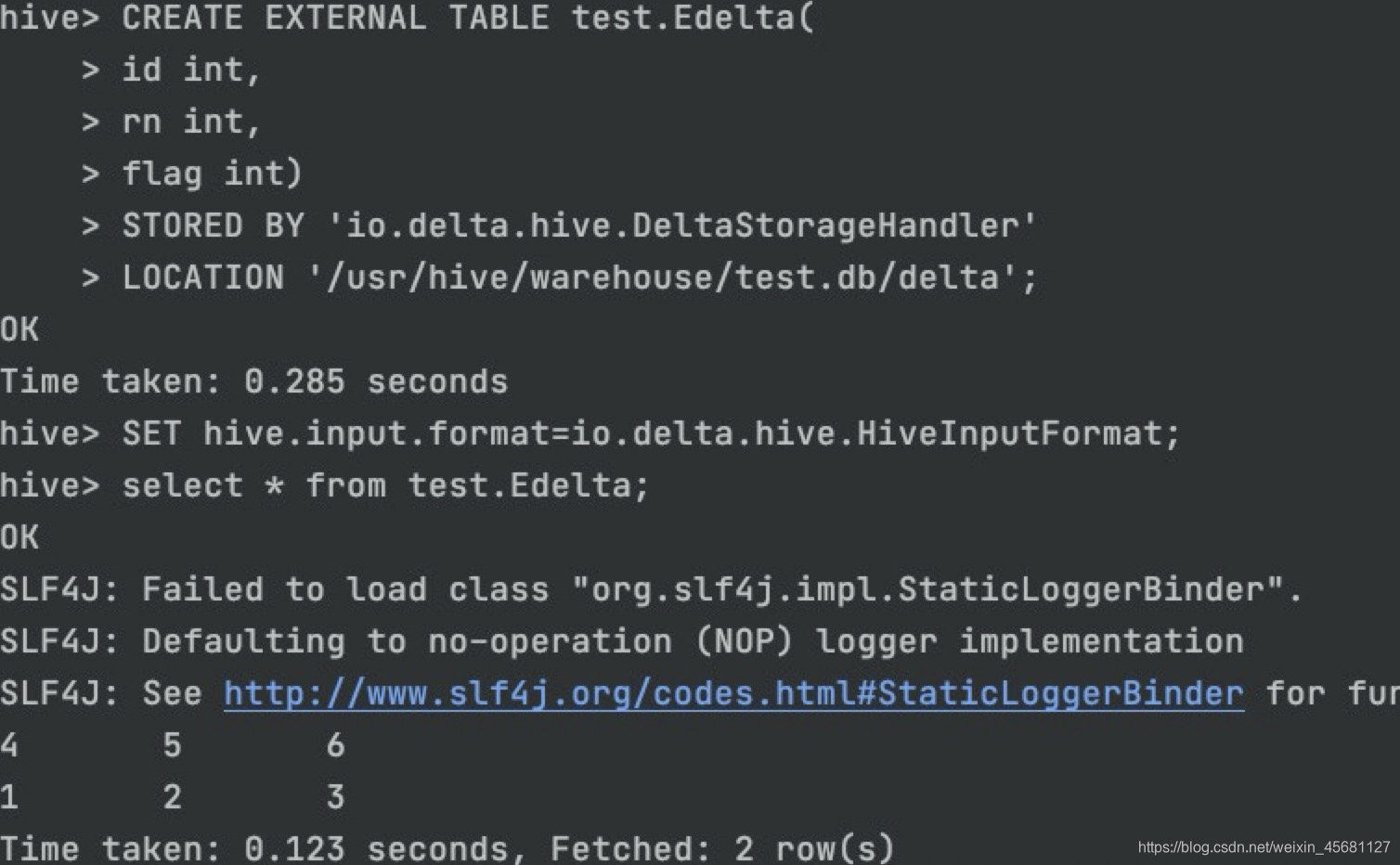
映射成功
5、验证,左边做DML操作,右边查询映射表。
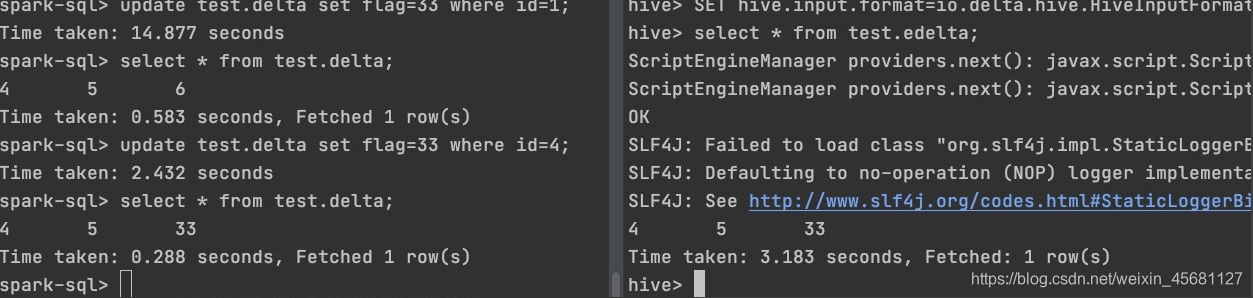
验证通过
异常处理
1、执行后报错Caused by: java.lang.ClassNotFoundException: Class com.hadoop.compression.lzo.LzoCodec not found

分析:这是因为在hadoop 的core-site.xml 和mapred-site.xml 中开启了压缩,并且压缩式lzo 这就导致写入 上传到hdfs 的文件自动被压缩为lzo。但是spark3里缺少lzo的包。
解决:
在spark目录jars里面,下个hadoop-lzo-0.4.20.jar的包放进去。
2、Hive建表映射后,报错无法识别包

分析:jar不匹配。当前使用的是delta-hive-assembly_2.12-0.2.0.jar,
解决:下载并使用delta-hive-assembly_2.11-0.2.0.jar即可。
3、Hive建表,报错json4s
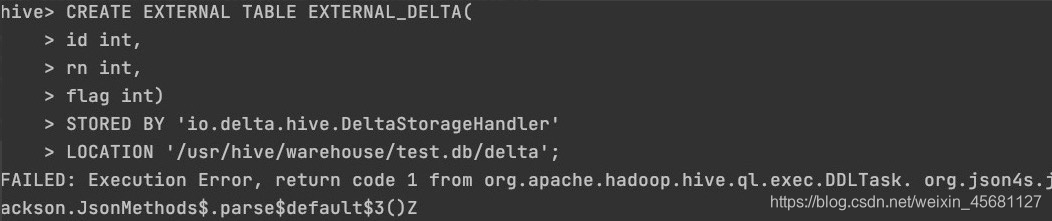
根据报错查看日志。还是jar包冲突
 查看目录,发现hive目录下竟然有spark。我的集群是EMR云。
查看目录,发现hive目录下竟然有spark。我的集群是EMR云。
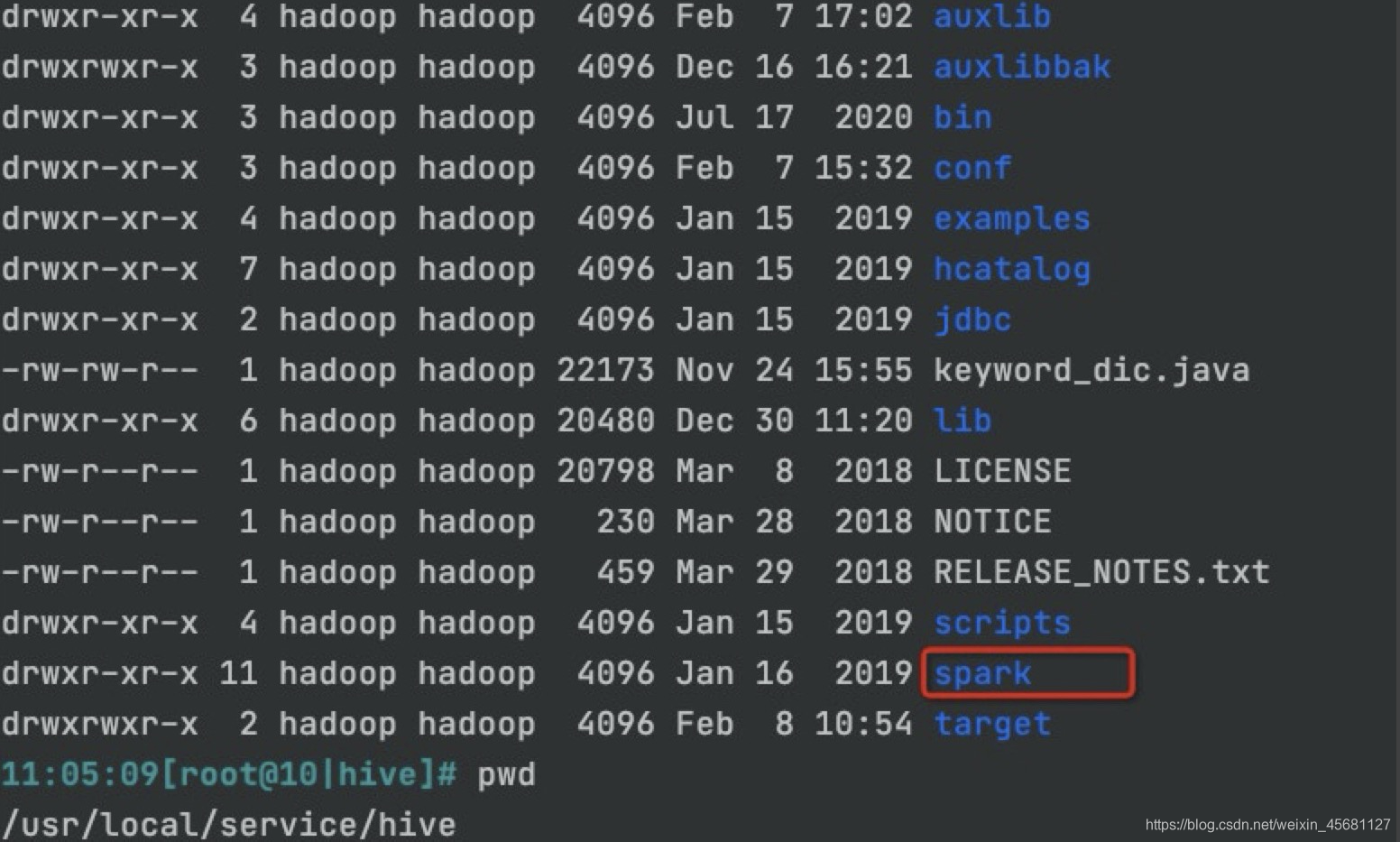
改这个目录下jars的json4s-jackson版本包,报错内容竟然不一样。
然后猜测这个目录导致的问题。
更改spark的名字。
$ mv spark spark2
然后执行通过
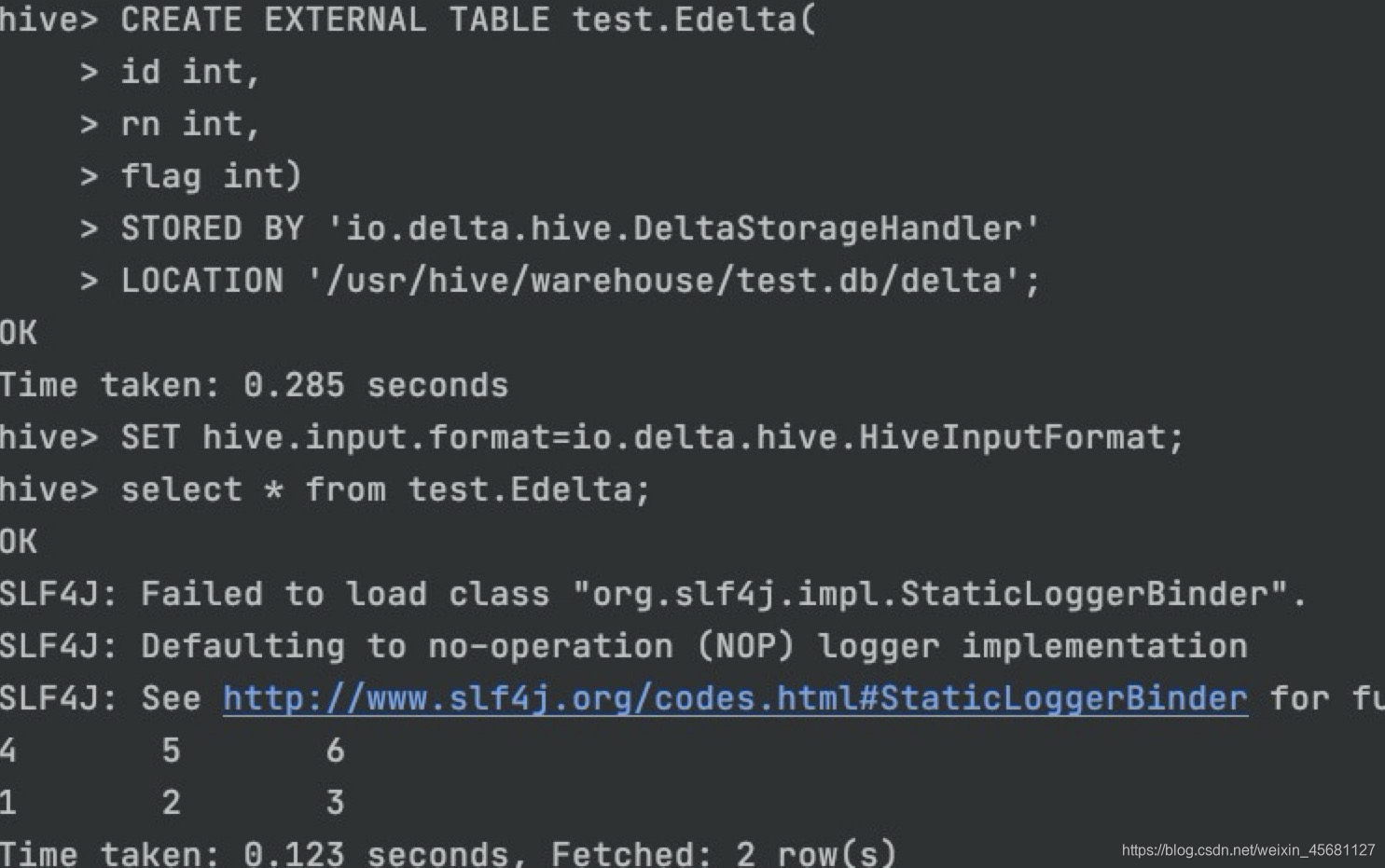
成功思密达。
总结
没有啥总结的,来个收藏和赞。这个测试没完结,持续更新。。。

















 9048
9048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









