







 本文介绍了在海豚调度中遇到的任务成功但显示失败的情况,问题源于海豚调度通过YARN API获取应用状态来判断任务完成情况。当YARN API返回非200状态码(例如404),原因是应用被清理导致无法找到。解决方案是调整YARN的资源管理器最大已完成应用数配置。此外,还分析了可能因短时间内大量应用完成被清理的场景,并建议根据集群情况适当增大配置值。
本文介绍了在海豚调度中遇到的任务成功但显示失败的情况,问题源于海豚调度通过YARN API获取应用状态来判断任务完成情况。当YARN API返回非200状态码(例如404),原因是应用被清理导致无法找到。解决方案是调整YARN的资源管理器最大已完成应用数配置。此外,还分析了可能因短时间内大量应用完成被清理的场景,并建议根据集群情况适当增大配置值。

前言:
在海豚调度中,大家肯定会遇到一种情况就是,任务成功,但是显示失败。是不是感觉很困扰。
我现在也遇到这个情况。我们公司开发人员在执行之前老代码(hive引擎)的时候。偶尔成功偶尔失败。
海豚调度到底是如何判断任务的成功和失败的?
异常:
查看海豚的worker日志。
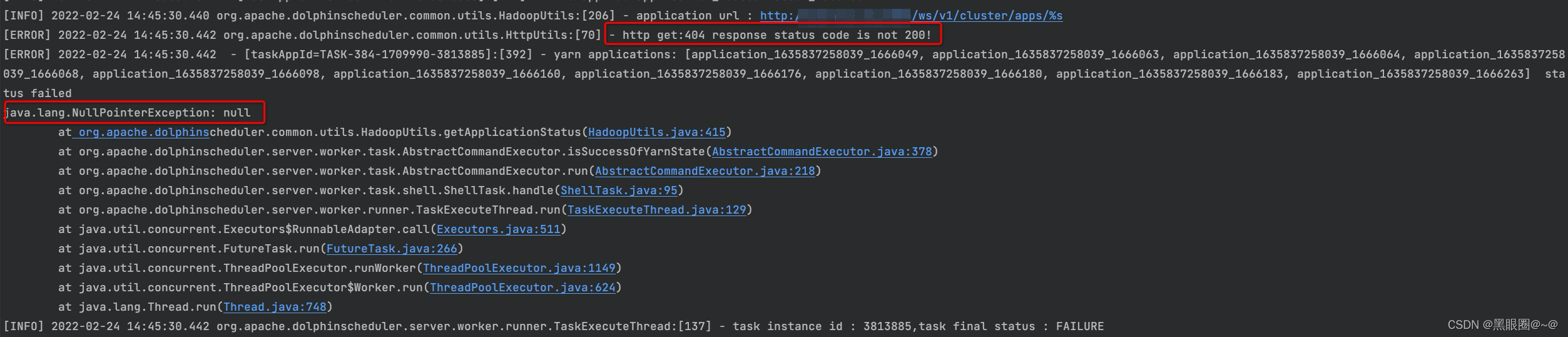
光看日志报错,各位大佬基本就能猜到了吧~
没错,海豚在执行完,获取执行这个任务中的所有application_id。然后通过yarn的API。去获取最终状态。那是不是呢?我们看源码。
源码位置:org/apache/dolphinscheduler/server/worker/task/AbstractCommandExecutor.java
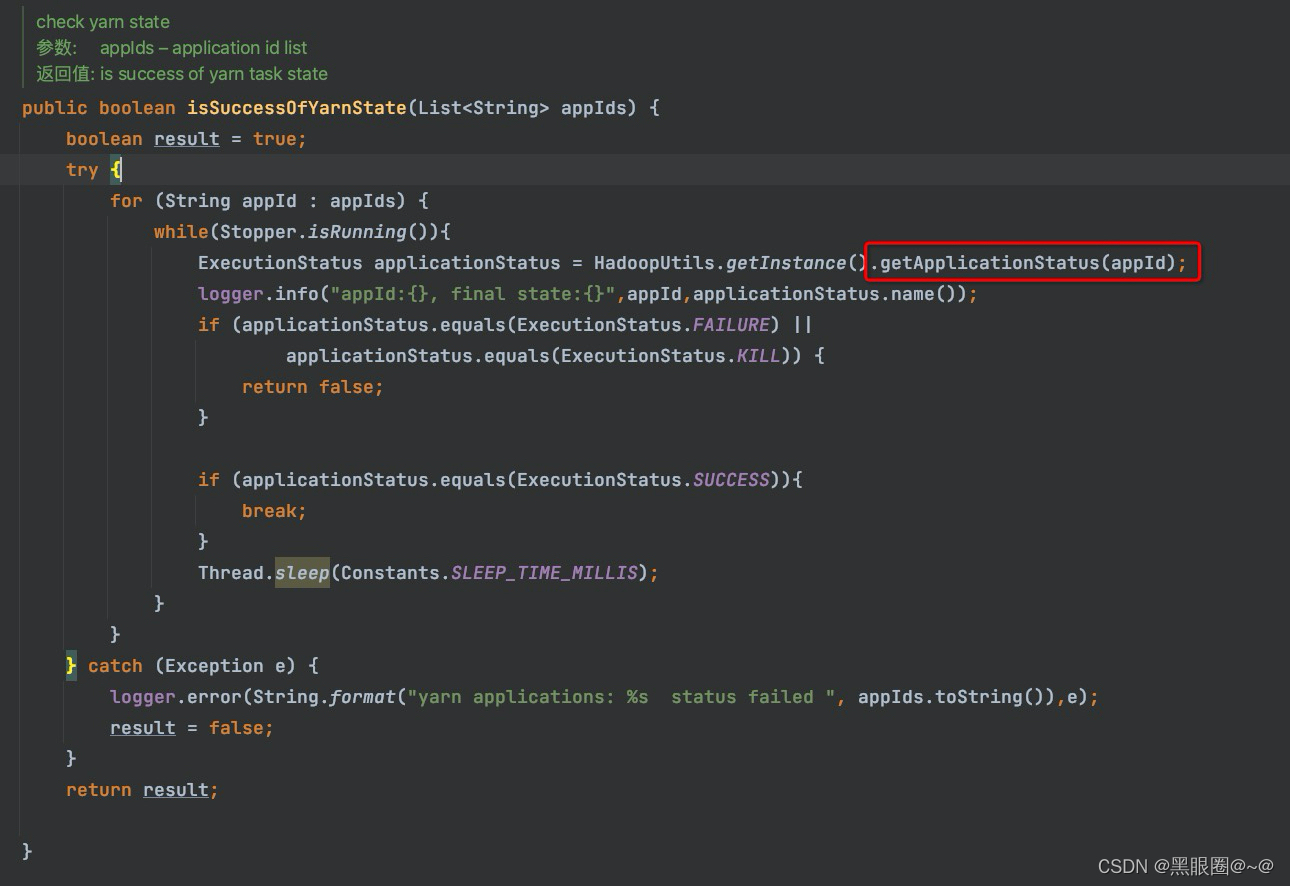
上图:是否成功呢?获取yarn的application状态。isSuccessOfYarnState下的getApplicationStatus方法。
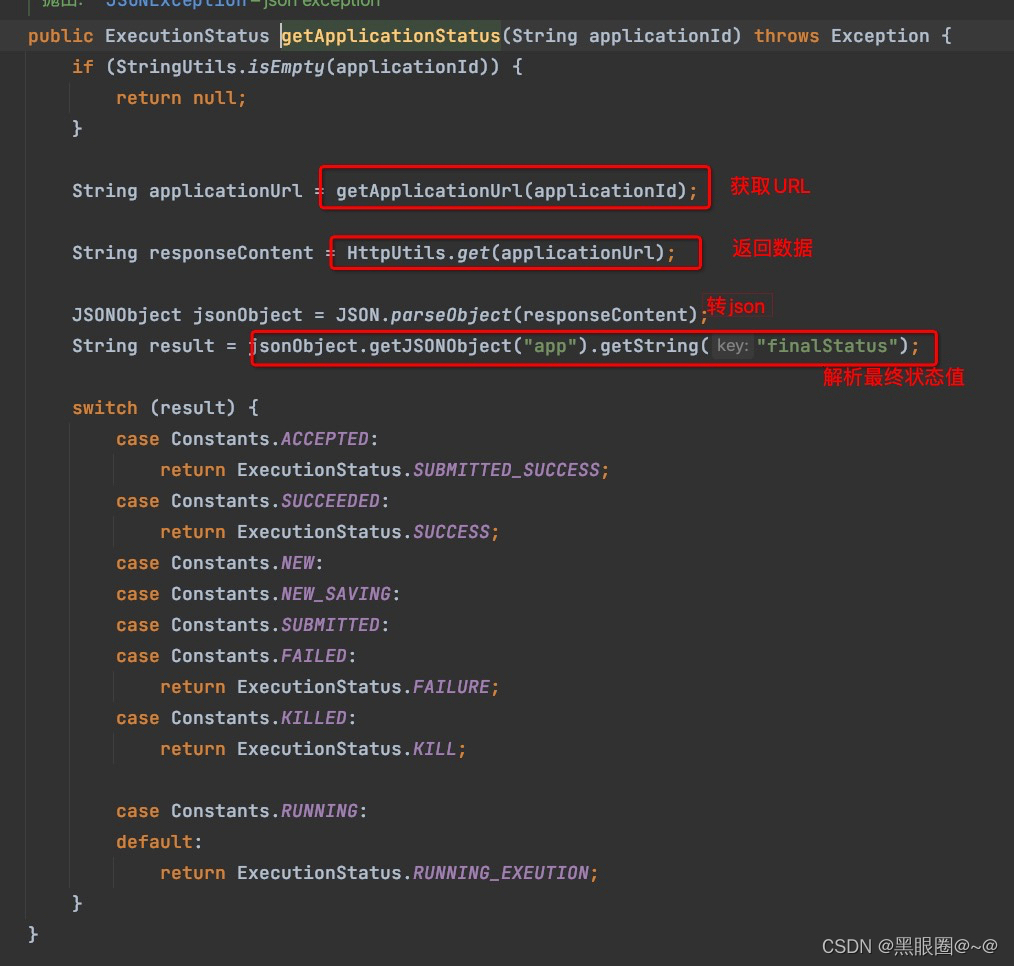
上图:和各位大佬想的一样。的确是获取application的finalStatus的值。来判断的。
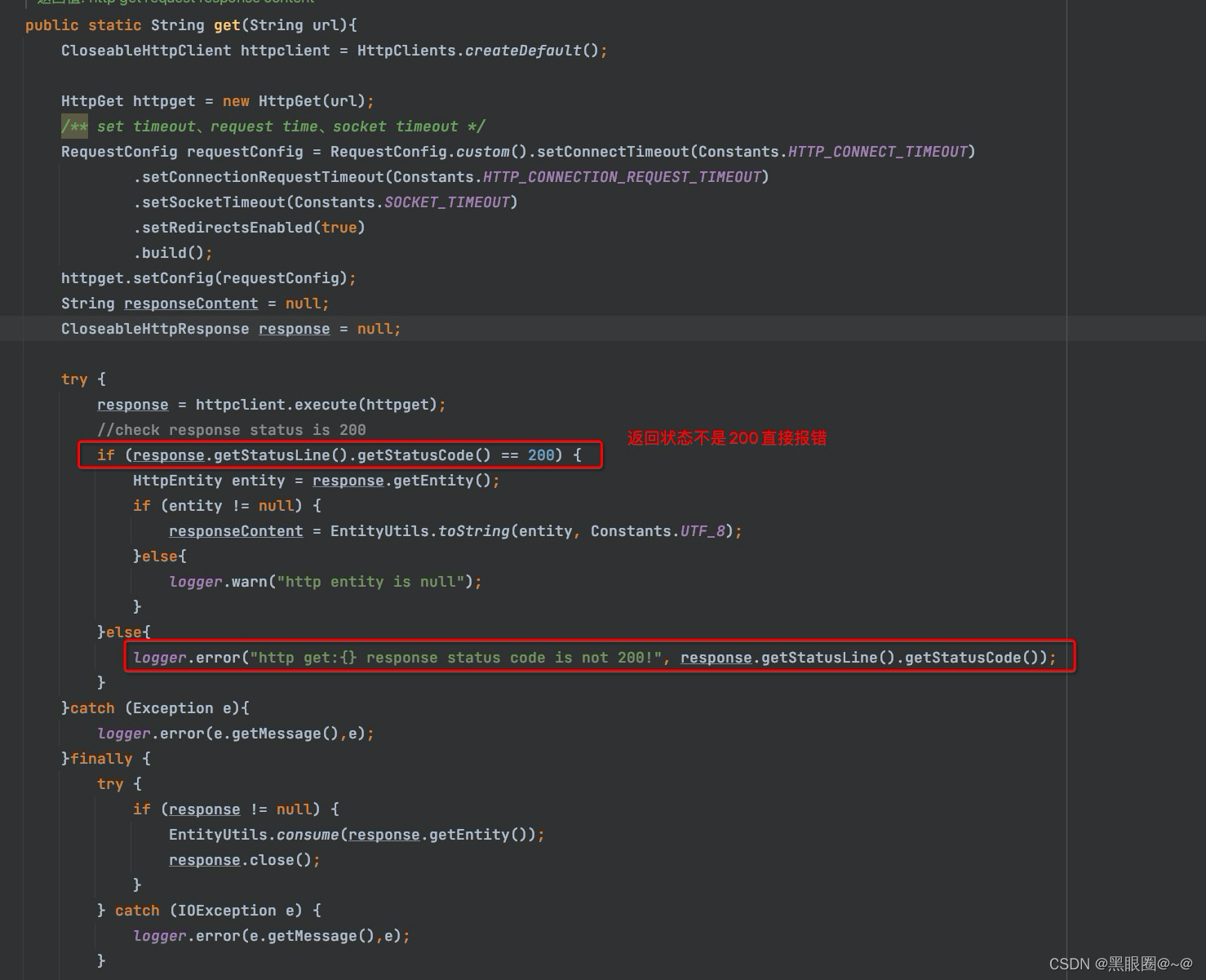
上图: 没错,是通过yarn的API去获取状态的(http://rm地址:端口/ws/v1/cluster/apps/)
当API返回状态码不是200的时候,直接抛出异常。所以直接报错了~
解决:
回到最初的问题。我的这个任务,为什么返回码判断是404呢?
因为没有找到我的appplication。
为什么没有找到呢?
因为yarn设置的API里。关于final状态保存策略有两种
一种是数量,一种是时间。我们配置里时间是保留7天。数量保留是150条。

猜测,如果时间段内有大量完成的app会被挤出页面
如果当前任务特别多的时候。hive脚本生成了20个application_id。这时候任务同时完成特别多。那么这20个生成完会被检测的时候,正好被刷掉了。
10点0分执行hive脚本。10点20执行结束。这个任务一共生成了20个application_id。但是这20分钟内其他任务一共执行完成超过150个application_id。会把这20个application_id刷掉。
这时候检测会找不到20个application_id。
解决方式:
yarn.resourcemanager.max-completed-applications可以设置大一点这个值。
设置多大合适呢?看你们集群而定。

有的人可能不是这个原因。具体什么原因可以看一下海豚的worker的日志。
因为海豚是中国人开发的,相对比较容易定位。
希望可以帮助到大家。坚持原创。


















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









