







 本文通过一系列实战案例介绍 Delta Lake 的基本使用方法,包括数据创建、更新、删除、历史版本管理、流批处理及合并小文件等核心功能。
本文通过一系列实战案例介绍 Delta Lake 的基本使用方法,包括数据创建、更新、删除、历史版本管理、流批处理及合并小文件等核心功能。
Delta Lake 测试案例
本篇我将写几个测试用例,来测试其功能,我这里使用sbt去创建项目,数据落盘到我本地电脑
一、创建项目:
| 组件 | 版本 |
|---|---|
| sbt | 1.4.2 |
| scala | 2.12.10 |
| Spark | 3.0.0 |
| DeltaLake | 0.7.0 |
build.sbt文件
name := "DaltaLake"
version := "0.1"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.0.0"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.0.0"
libraryDependencies += "io.delta" %% "delta-core" % "0.7.0"
libraryDependencies += "log4j" % "log4j" % "1.2.17"
二、测试案例
1、手动创建数据
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
object SparkDataInot {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setMaster("local[*]").setAppName("Test"))
val spark = SparkSession.builder().getOrCreate()
val rdd = sc.makeRDD(Seq(1, 2, 3, 4))
import spark.implicits._
val df = rdd.toDF("id")
df.write.format("delta").save("/Users/smzdm/Documents/data/0")
// df.write.format("delta").save("DeltaTable") 当然,本地测试的话,这么写也是OK的,存储位置是项目目录下
df.show()
sc.stop()
spark.stop()
}
}
-----------------------------------
+---+
| id|
+---+
| 1|
| 2|
| 3|
| 4|
+---+
目录下00000000000000000000.json文件内容:
{"commitInfo":{"timestamp":1611823662796,"operation":"WRITE","operationParameters":{"mode":"ErrorIfExists","partitionBy":"[]"},"isBlindAppend":true,"operationMetrics":{"numFiles":"5","numOutputBytes":"2007","numOutputRows":"4"}}}
{"protocol":{"minReaderVersion":1,"minWriterVersion":2}}
{"metaData":{"id":"0b3ba27f-6a52-48e4-b9c4-6a1c3818a25c","format":{"provider":"parquet","options":{}},"schemaString":"{\"type\":\"struct\",\"fields\":[{\"name\":\"id\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}}]}","partitionColumns":[],"configuration":{},"createdTime":1611823659077}}
{"add":{"path":"part-00000-cd0851fa-df9c-48c9-b94e-24ad9bfa2b33-c000.snappy.parquet","partitionValues":{},"size":299,"modificationTime":1611823662000,"dataChange":true}}
{"add":{"path":"part-00001-a098f9cb-ceaa-4ef7-aa5e-10ba6f90fe7f-c000.snappy.parquet","partitionValues":{},"size":427,"modificationTime":1611823662000,"dataChange":true}}
{"add":{"path":"part-00003-f62f5dac-6fe7-4cee-bf43-b1488996db0e-c000.snappy.parquet","partitionValues":{},"size":427,"modificationTime":1611823662000,"dataChange":true}}
{"add":{"path":"part-00005-4de1c7f7-d399-483b-bc7f-77e7b21dd017-c000.snappy.parquet","partitionValues":{},"size":427,"modificationTime":1611823662000,"dataChange":true}}
{"add":{"path":"part-00007-17f127f0-f378-4a74-9b92-97ac65f57c23-c000.snappy.parquet","partitionValues":{},"size":427,"modificationTime":1611823662000,"dataChange":true}}
以下每次操作写表会生成一个write的json文件,我这里就不重复写了
{"commitInfo":{"timestamp":1611828204517,"operation":"WRITE","operationParameters":{"mode":"Overwrite","partitionBy":"[]"},"readVersion":3,"isBlindAppend":false,"operationMetrics":{"numFiles":"1","numOutputBytes":"886","numOutputRows":"4"}}}
{"add":{"path":"part-00000-cb4cdcc9-5e71-4f45-ae38-01c1a526e3c4-c000.snappy.parquet","partitionValues":{},"size":886,"modificationTime":1611828204000,"dataChange":true}}
{"remove":{"path":"part-00000-9374a554-221f-4fc6-8197-486cc61d9dc5-c000.snappy.parquet","deletionTimestamp":1611828204512,"dataChange":true}}
2、测试Delta表更新Schema(其实Spark本身可以实现更新Schema)
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
/**
* 测试案例:新增schema
*/
object DeltaSchema {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").getOrCreate()
val df = spark.read.format("delta").load("/Users/smzdm/Documents/data/0")
val df1 = df.withColumn("rn",row_number()over(Window.orderBy("id")))
.withColumn("flag",when(col("rn")===lit(1),lit(1)).otherwise(lit(0)))
df1.show()
df1.write.format("delta").option("mergeSchema","true").mode("overwrite").save("/Users/smzdm/Documents/data/0")
spark.stop()
}
}
-----------------------------------
+---+---+----+
| id| rn|flag|
+---+---+----+
| 1| 1| 1|
| 2| 2| 0|
| 13| 3| 0|
| 14| 4| 0|
+---+---+----+
目录下00000000000000000001.json文件内容:
{"commitInfo":{"timestamp":1611824104223,"operation":"WRITE","operationParameters":{"mode":"Overwrite","partitionBy":"[]"},"readVersion":0,"isBlindAppend":false,"operationMetrics":{"numFiles":"1","numOutputBytes":"886","numOutputRows":"4"}}}
{"metaData":{"id":"0b3ba27f-6a52-48e4-b9c4-6a1c3818a25c","format":{"provider":"parquet","options":{}},"schemaString":"{\"type\":\"struct\",\"fields\":[{\"name\":\"id\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}},{\"name\":\"rn\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}},{\"name\":\"flag\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}}]}","partitionColumns":[],"configuration":{},"createdTime":1611823659077}}
{"add":{"path":"part-00000-5f96937a-30aa-4e23-af03-f0679367ca7c-c000.snappy.parquet","partitionValues":{},"size":886,"modificationTime":1611824103000,"dataChange":true}}
{"remove":{"path":"part-00001-a098f9cb-ceaa-4ef7-aa5e-10ba6f90fe7f-c000.snappy.parquet","deletionTimestamp":1611824104202,"dataChange":true}}
{"remove":{"path":"part-00003-f62f5dac-6fe7-4cee-bf43-b1488996db0e-c000.snappy.parquet","deletionTimestamp":1611824104202,"dataChange":true}}
{"remove":{"path":"part-00000-cd0851fa-df9c-48c9-b94e-24ad9bfa2b33-c000.snappy.parquet","deletionTimestamp":1611824104202,"dataChange":true}}
{"remove":{"path":"part-00007-17f127f0-f378-4a74-9b92-97ac65f57c23-c000.snappy.parquet","deletionTimestamp":1611824104202,"dataChange":true}}
{"remove":{"path":"part-00005-4de1c7f7-d399-483b-bc7f-77e7b21dd017-c000.snappy.parquet","deletionTimestamp":1611824104202,"dataChange":true}}
3、更新数据
参数:
如果调整表的属性,你不想对表进行删除或者更新,可以设置参数:
delta.appendOnly=true
spark.conf.set("spark.databricks.delta.properties.defaults.appendOnly", "true")
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import io.delta.tables._
/**
* 测试案例:更新update
*/
object DeltaUpdate {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") //这两个参数要么这里加,要么提交时候加
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") //这两个参数要么这里加,要么提交时候加
.appName("update")
.master("local[*]").getOrCreate()
import spark.implicits._
//读取成表
val ddf = DeltaTable.forPath(spark,"/Users/smzdm/Documents/data/0")
// update(where条件,Map(更新字段->(更新逻辑)))
ddf.update(col("id")>2,Map("id"->(col("id")+10)))
val df = ddf.toDF
df.show()
df.write.format("delta").option("mergeSchema","true").mode("overwrite").save("/Users/smzdm/Documents/data/0")
spark.stop()
}
}
-----------------------------------
+---+---+----+
| id| rn|flag|
+---+---+----+
| 1| 1| 1|
| 2| 2| 0|
| 13| 3| 0|
| 14| 4| 0|
+---+---+----+
目录下00000000000000000002.json文件内容:
{"commitInfo":{"timestamp":1611828239222,"operation":"UPDATE","operationParameters":{"predicate":"(id#395 > 2)"},"readVersion":4,"isBlindAppend":false,"operationMetrics":{"numRemovedFiles":"1","numAddedFiles":"1","numUpdatedRows":"2","numCopiedRows":"2"}}}
{"remove":{"path":"part-00000-cb4cdcc9-5e71-4f45-ae38-01c1a526e3c4-c000.snappy.parquet","deletionTimestamp":1611828238847,"dataChange":true}}
{"add":{"path":"part-00000-cf10bc40-bd4b-4a41-9897-2fc0fe2cfe09-c000.snappy.parquet","partitionValues":{},"size":886,"modificationTime":1611828239000,"dataChange":true}}
4、删除数据
import io.delta.tables.DeltaTable
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.{col, lit}
object DeltaDelete {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") //这两个参数要么这里加,要么提交时候加
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") //这两个参数要么这里加,要么提交时候加
.appName("delete")
.master("local[*]").getOrCreate()
//读取成表
val ddf = DeltaTable.forPath(spark,"/Users/smzdm/Documents/data/0")
ddf.delete(col("id")===2)
val df = ddf.toDF
df.show()
df.write.format("delta").option("mergeSchema","true").mode("overwrite").save("/Users/smzdm/Documents/data/0")
spark.stop()
}
}
-----------------------------------
+---+---+----+
| id| rn|flag|
+---+---+----+
| 1| 1| 1|
| 13| 3| 0|
| 14| 4| 0|
+---+---+----+
目录下00000000000000000003.json文件内容:
{"commitInfo":{"timestamp":1611828364666,"operation":"DELETE","operationParameters":{"predicate":"[\"(`id` = 2)\"]"},"readVersion":6,"isBlindAppend":false,"operationMetrics":{"numRemovedFiles":"1","numDeletedRows":"1","numAddedFiles":"1","numCopiedRows":"3"}}}
{"remove":{"path":"part-00000-3067922b-8702-49df-a903-aa778462d95b-c000.snappy.parquet","deletionTimestamp":1611828364655,"dataChange":true}}
{"add":{"path":"part-00000-e2f90118-2525-4614-8015-42c2c2545018-c000.snappy.parquet","partitionValues":{},"size":876,"modificationTime":1611828364000,"dataChange":true}}
5、数据历史版本
import io.delta.tables.DeltaTable
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.col
/**
* 查看历史版本
* 回溯某历史版本数据
* 清除历史版本
*/
object DeltaDataVersion {
def main(args: Array[String]): Unit = {
//输入回溯版本
val versionCode = 1
// val versionCode = args(0).trim
val spark = SparkSession.builder()
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") //这两个参数要么这里加,要么提交时候加
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") //这两个参数要么这里加,要么提交时候加
.appName("delete")
.master("local[*]").getOrCreate()
val df = DeltaTable.forPath(spark, "/Users/smzdm/Documents/data/0")
//查看历史
df.history().toDF().show(false)
//可选择版本号(versionAsOf)或者时间戳(timestampAsOf)进行数据回溯
val dff = spark.read.format("delta").option("versionAsOf", versionCode).load("/Users/smzdm/Documents/data/0")
val dff = spark.read.format("delta").option("timestampAsOf", "2021-01-28 18:03:59").load("/Users/smzdm/Documents/data/0")
//清理100小时历史数据,不填写默认保留7天数据,清理7天前数据
df.vacuum(100)
dff.toDF.show()
spark.stop()
}
}
6、测试双表merge
关于merge这一块测试时间较长,出现的情况特别多,数据可能不为准确。
前一篇文章提到过自动模式,在这一篇也进行测试。另外需要注意如下:
1、笛卡尔积情况会报错。必须提前对数据进行处理。
2、自动模式根据需求选择开启。
3、merge表之后,执行execute()函数进行触发。不需要重新写回表。
import io.delta.tables._
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
/**
* 多表进行merge操作
* merge.update:配合whenMatched(过滤条件)使用,只更新匹配到的数据
* merge.insert:配合whenMatched(过滤条件)使用,插入新数据
*
* 组合:merge.update.insert 实现有则更新,无则新增
*
* 测试:
* update:成功
* insert:成功
* 笛卡尔积:报错,需要提前对key进行预处理
* 两表不同schema,进行merge。自动模式和默认模式测试
*
*/
object DeltaMerge {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") //这两个参数要么这里加,要么提交时候加
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") //这两个参数要么这里加,要么提交时候加
.config("spark.databricks.delta.schema.autoMerge.enabled",true) //开启自动模式演变,可选
.appName("merge")
.master("local[*]")
.getOrCreate()
val ddf = DeltaTable.forPath(spark, "DeltaTable").toDF.withColumn("rn", lit(1)).withColumn("flag", lit(100))
val ddf1 = DeltaTable.forPath("/Users/smzdm/Documents/data/0")
DeltaTable.forName("")
val df = ddf.withColumn("rn",col("rn")+2)
.withColumn("A",lit("a"))
.withColumn("B",lit("B"))
print("=============t====================")
ddf.toDF.show()
print("----------------t1-----------------")
ddf1.toDF.show()
print("==============df===================")
df.show()
//merge.update更新数据,配合whenMatched(过滤条件)使用,Map(需要更新字段->更新来源字段)
ddf1.as("t1")
.merge(ddf.as("t"), "t.id=t1.id")
.whenMatched("t.id=4") //
.updateExpr(Map("t1.rn" -> "t.rn")) //只更新匹配到ID的
//.updateAll() //更新所有数据
.execute()
//merge.insert插入数据,配合whenNotMatched(过滤条件)使用,Map(需要更新字段->更新来源字段)
ddf1.as("t1")
.merge(ddf.as("t"), "t.id=t1.id")
.whenNotMatched("t.id=4") //加条件
.insertExpr(Map("t1.rn" -> "t.rn")) //ID有则更新,无则新增
// .whenNotMatched()
// .insertAll() //插入所有数据
.execute()
//测试笛卡尔积,报错。根据官网提示,需要提前对key进行预处理,多key会导致无法识别更新哪一个
ddf1.as("t1")
.merge(df.as("t"),"t.id=t1.id")
.whenMatched()
.updateAll()
.whenNotMatched()
.insertAll()
.execute()
ddf1.toDF.show()
spark.stop()
}
}
7、流批同表测试
Delta Lake完美的兼容了Spark的Structured Streaming。具体测试如下。。
1、DL表为Source。
options:
maxFilesPerTrigger:控制流加载DL表的最大文件数,如果批次处理则设置这个,默认1000
maxBytesPerTrigger:控制每个批次最大的数据大小,如果是批次处理设置这个,如果是整表处理则忽略这个。
maxFilesPerTrigger和maxBytesPerTrigger可以一同设置,两者其中一个达到阈值都会触发。
因为Structured Streaming不处理不是追加的数据,当DL表发生改变时,SS则会报错。
因此要么删除检查点后启动程序重新计算,要么设置以下两个参数。
ignoreDeletes:忽略删除数据的事务
ignoreChanges:重新处理,如果使用,则流不会因源表的删除或更新而中断
2、DL表为Sink。
options:
checkpointLocation:存储流状态信息。必写
append:追加到DL表后方。
complete:重写整张表,重写必须提前聚合处理DF。
append或complete两种模式二选一
注意: 如果删除checkpointLocation,则整个流表数据丢失。
流每批都算一个历史迭代,都可以从历史中回溯到数据
7.1 测试DL表为source
7.1配合7.2一起测试。
7.1作为sink端读取数据实时展示
7.2作为source端写入
import org.apache.spark.sql.SparkSession
/**
* 测试Delta流处理
* DL表为Source
* options:
* maxFilesPerTrigger:控制流加载DL表的最大文件数,如果批次处理则设置这个,默认1000
* maxBytesPerTrigger:控制每个批次最大的数据大小,如果是批次处理设置这个,如果是整表处理则忽略这个。
* maxFilesPerTrigger和maxBytesPerTrigger可以一同设置,两者其中一个达到阈值都会触发。
*
* 因为Structured Streaming不处理不是追加的数据,当DL表发生改变时,SS则会报错。
* 因此要么删除检查点后启动程序重新计算,要么设置以下两个参数。
* ignoreDeletes:忽略删除数据的事务
* ignoreChanges:重新处理,如果使用,则流不会因源表的删除或更新而中断
*
*/
object DeltaStreamSource {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("StructuredStreamingSource")
.master("local[*]")
.getOrCreate()
val df = spark.readStream
.format("delta")
.option("maxFilesPerTrigger", 1000)
.option("ignoreChanges", true)
.load("/Users/smzdm/Documents/data/0")
val query = df.writeStream
.outputMode("update")
.format("console")
.start()
query.awaitTermination()
}
}
nc -l -p 9999
1,1,1,1,1
1,1,1,1,1
3,3,3,3,3
4,4,4,4,4
3,3,3,3,3
-------------------------------------------
Batch: 4
-------------------------------------------
+---+---+----+---+---+
| id| rn|flag| A| B|
+---+---+----+---+---+
| 1| 2| 2| 2| 2|
| 3| 6| 6| 6| 6|
| 4| 4| 4| 4| 4|
| 2| 2| 2| 2| 2|
+---+---+----+---+---+
7.2 测试DL表为sink
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.{col, split}
/**
* 测试Delta流处理
* 2、DL表为sink。
* options:
* checkpointLocation:存储流状态信息。必写
* append:追加到DL表后方。
* complete:重写整张表,重写必须提前聚合处理DF。
* append或complete两种模式二选一
*
* 如果删除checkpointLocation,则整个流表数据丢失。
*
*/
object DeltaStream {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local[*]")
.appName("StructuredStreaming")
.getOrCreate()
//返回DF
val df = spark.readStream
.format("socket")
.option("host", "127.0.0.1")
.option("port", 9999)
.load()
//将DF输出到控制台
// val query = df1.writeStream
// .outputMode("update")
// .format("console")
// .start()
//直接操作流DF
// val df1 = df
// .withColumn("id", split(col("value"), ",")(0).cast("Int"))
// .withColumn("rn", split(col("value"), ",")(1).cast("Int"))
// .withColumn("flag", split(col("value"), ",")(2).cast("Int"))
// .withColumn("A", split(col("value"), ",")(3).cast("Int"))
// .withColumn("B", split(col("value"), ",")(4).cast("Int"))
//追加到DL表中
// val query = df1.writeStream
// .format("delta")
// .option("checkpointLocation","/Users/smzdm/Documents/data/checkpoint") //流处理必须加这个参数
// .outputMode("append") // 输出模式,追加或重写 append 或者 complete
// .start("/Users/smzdm/Documents/data/0")
//直接操作流DF
val df1 = df
.withColumn("id", split(col("value"), ",")(0).cast("Int"))
.withColumn("rn", split(col("value"), ",")(1).cast("Int"))
.withColumn("flag", split(col("value"), ",")(2).cast("Int"))
.withColumn("A", split(col("value"), ",")(3).cast("Int"))
.withColumn("B", split(col("value"), ",")(4).cast("Int"))
.groupBy("id")
.sum("rn", "flag", "A", "B")
.withColumn("rn", col("sum(rn)").cast("Int"))
.withColumn("flag", col("sum(flag)").cast("Int"))
.withColumn("A", col("sum(A)").cast("String"))
.withColumn("B", col("sum(B)").cast("String"))
.select("id", "rn", "flag", "A", "B")
//集合后重写到DL表,只要checkpoint不删,这张表不会丢失
val query = df1.writeStream
.format("delta")
.option("checkpointLocation", "/Users/smzdm/Documents/data/checkpoint") //流处理必须加这个参数
.outputMode("complete") // 输出模式,追加或重写 append 或者 complete
.start("/Users/smzdm/Documents/data/0")
query.awaitTermination()
}
}
append模式下,会出现两个相同的id。
+---+---+----+----+----+
| 2| 3| 100| a| B|
| 1| 3| 100| a| B|
| 3| 3| 100| a| B|
| 4| 3| 100| a| B|
|100| 22| 22|null|null|
|101| 23| 23|null|null|
| 14| 4| 0|null|null|
|103| 25| 25|null|null|
| 1| 10| 10|null|null|
|102| 24| 24|null|null|
| 13| 3| 0|null|null|
+---+---+----+----+----+
测试complete模式。
nc -l -p 9999
104,1,1,1,1
104,2,2,2,2
104,3,3,3,3
104,5,5,5,5
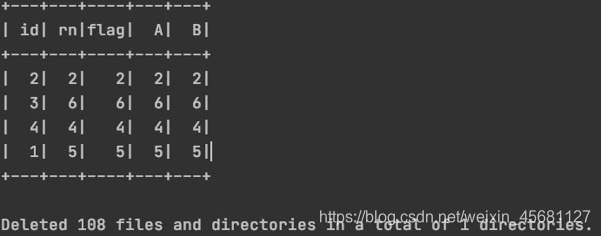
+---+---+----+---+---+
| id| rn|flag| A| B|
+---+---+----+---+---+
|104| 11| 11| 11| 11|
+---+---+----+---+---+
重写了表,
继续输入
1,1,1,1,1
1,1,1,1,1
+---+---+----+---+---+
| id| rn|flag| A| B|
+---+---+----+---+---+
|104| 11| 11| 11| 11|
+---+---+----+---+---+
| 1| 2| 2| 2| 2|
+---+---+----+---+---+
断开流,重启继续写入
1,1,1,1,1
1,1,1,1,1
+---+---+----+---+---+
| id| rn|flag| A| B|
+---+---+----+---+---+
|104| 11| 11| 11| 11|
+---+---+----+---+---+
| 1| 4| 4| 4| 4|
+---+---+----+---+---+
checkpoint文件内容:
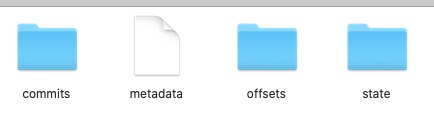

其中小文件最多的是state。里面存着每一张流表的流数据信息。
8、合并并减少小文件
关于减少数据文件,这里面有2个概念:
1、合并输出的df数据文件。(使用coalesce或者repartition解决)
2、删除delta在存储介质(HDFS)中的小文件。(使用vacuum解决)
主意:
使用vacuum时候。
1、删除后无法回滚,不影响当前数据。
2、不能写入中使用vacuum的。
2、如果传入的时间太短,会报错。提示清理历史数据时间太短。这时候如果还是执意清空10小时之前的数据,又不报错。
添加参数即可:config(“spark.databricks.delta.retentionDurationCheck.enabled”,“false”)
上才艺~ 不对,上代码:
import io.delta.tables.DeltaTable
import org.apache.spark.sql.SparkSession
/**
* 减少小文件,合并小文件
* 很多人喜欢用repartition。但是对于输出文件的倍数合并,我更建议使用coalesce。
*/
object DeltaMergeFile {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") //这两个参数要么这里加,要么提交时候加
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") //这两个参数要么这里加,要么提交时候加
.config("spark.databricks.delta.retentionDurationCheck.enabled","false") //如果vacuum时间太短,必须加入这个参数关闭提醒。
.appName("mergefile")
.master("local[*]").getOrCreate()
val ddf = DeltaTable.forPath("/Users/smzdm/Documents/data/0")
ddf.toDF.show()
ddf.vacuum(50) //删除历史小文件,单位小时
ddf.toDF
.coalesce(1) //spark自带的合并小文件
.write
.format("delta")
.option("mergeSchema","true")
.mode("overwrite")
.save("/Users/smzdm/Documents/data/0")
spark.stop()
}
}
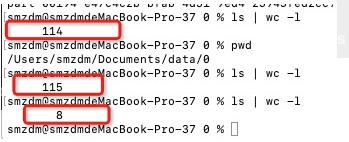
合并前114个
1、使用coalesce(1)对输出合并后,115个文件
2、然后vacuum删除历史后,只剩下8个文件。
总结
需要注意的地方是merge和流表。两个测试案例较为简单,仅仅测试功能场景。未做复杂逻辑(这喵的都不重要)。
1、当merge的时候,需要注意笛卡尔积情况,key必须是唯一时候才能进行关联,否则报错。
2、流的时候会根据提交批次,每个批次会出现一个小文件,所以在流中,会出现大量的小文件。
3、所有的文件都是有用的,非必要情况下不可手动删除,否则会导致DL表数据无法显示和找回。
话说文章中有小彩蛋。各位注意到了么?

















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









