







 数据清洗是大数据分析的重要环节,涉及数据质量评价、缺失值、重复值和错误值的处理。通过对数据质量的准确性、完整性和简洁性的维护,确保数据适用性。数据清洗流程包括分析原始数据、制定清洗策略、错误检测与修正,常用方法有缺失值填充、重复值删除和错误值校正。
数据清洗是大数据分析的重要环节,涉及数据质量评价、缺失值、重复值和错误值的处理。通过对数据质量的准确性、完整性和简洁性的维护,确保数据适用性。数据清洗流程包括分析原始数据、制定清洗策略、错误检测与修正,常用方法有缺失值填充、重复值删除和错误值校正。
数据清洗概述
1.1 数据清洗的背景
目前的海量数据来源广泛,类型繁杂。由此会出现不完整、重复、错误等问题。因此数据清洗是大数据分析和应用过程中的关键环节。
1)数据质量
数据质量是一个相对的概念,是指在业务环境下,数据符合数据消费者的使用目的,能满足业务场景具体需求的程度。
2)数据质量的评价指标
准确性、完整性、简洁性、适用性。
其中适用性是评价数据质量的重要标准,而数据的准确性、完整性和简洁性是为了保证数据的适用性。
3)数据质量的问题分类
由于数据仓库的数据来自底层数据源,因此“脏”数据出现的原因和数据源有密切的关系。而基于数据源的“脏”数据分类方法需要为每种类型的“脏”数据设计单独的清洗方式,所以从数据清洗方式的设计者角度看又可以进一步的进行分类,这是基于清洗方式的“脏”数据分类。
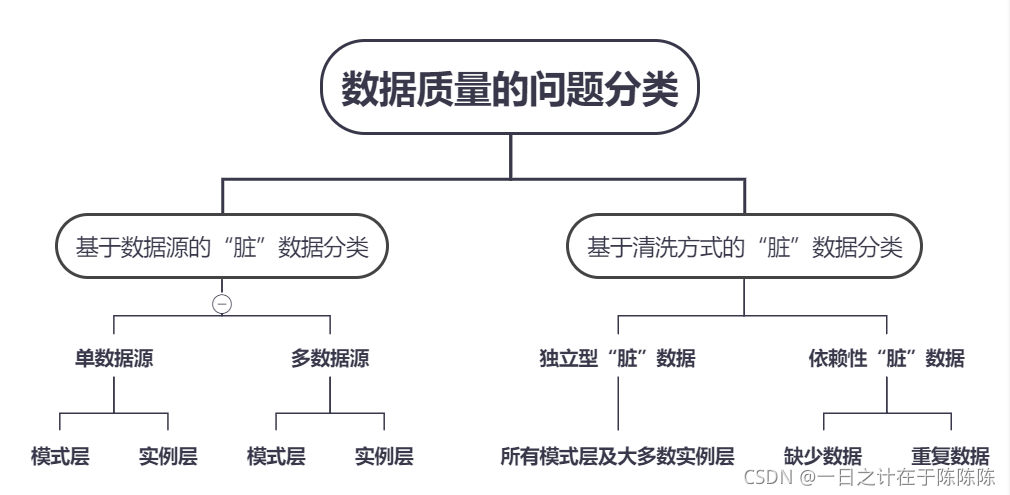
模式层:数据库的结构,就是关系结构
实例层:关系中具体存储的数据记录或元组
独立型“脏”数据:可通过记录或本身属性检验出是否包含“脏”数据,不需要依赖其他记录或属性检测
依赖性“脏”数据:主要包括缺失数据和重复数据等“脏”数据,而缺失数据主要为数据空值和数据异常,一般针对特定类型的“脏”数据涉及特定的清洗方式
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









