









原文链接:https://arxiv.org/pdf/2405.17429
简介:现有的3D语义方法使用密集网格作为场景表达,忽略了占用的稀疏性和物体尺度的多样性,从而导致不平衡的资源分配。本文提出以物体为中心的表达,使用稀疏3D语义高斯表达场景,其中每个高斯表示一个感兴趣区域及其语义特征。通过注意力机制从图像聚合信息, 迭代地细化3D高斯的属性,并提出高效的高斯到体素的溅射方法,聚合每个位置附近的高斯,生成3D占用预测。在NuScenes和KITTI-360数据集上的实验表明,本文方法能使用更小的空间,达到与sota相当的性能。
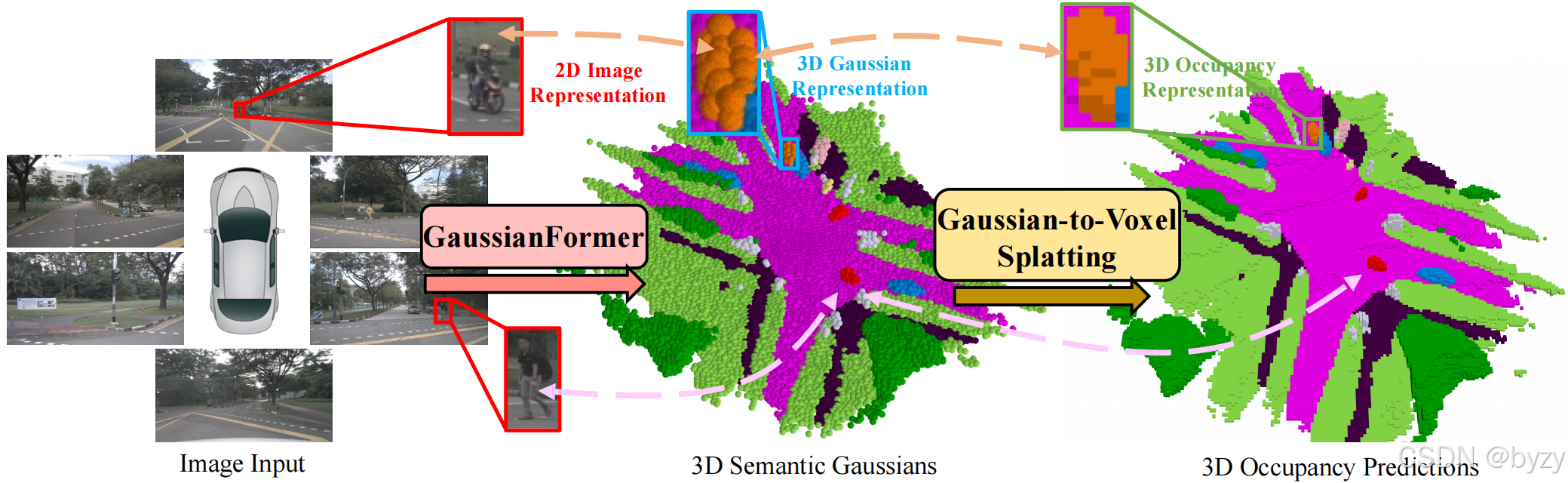
1. 以物体为中心的3D场景表达
任务:给定多视图图像 I = { I i ∈ R 3 × H × W ∣ i = 1 , ⋯ , N } I=\{I_i\in\mathbb R^{3\times H\times W}|i=1,\cdots,N\} I={Ii∈R3×H×W∣i=1,⋯,N}以及相应的内参 K = { K i ∈ R 3 × 3 ∣ i = 1 , ⋯ , N } K=\{K_i\in\mathbb R^{3\times3}|i=1,\cdots,N\} K={Ki∈R3×3∣i=1,⋯,N}和外参 T = { T i ∈ R 4 × 4 ∣ i = 1 , ⋯ , N } T=\{T_i\in\mathbb R^{4\times4}|i=1,\cdots,N\} T={Ti∈R4×4∣i=1,⋯,N},目标是预测3D语义占用 O ∈ C X × Y × Z O\in\mathbb C^{X\times Y\times Z} O∈CX×Y×Z,其中 C \mathbb C C为语义类别的集合。
基于网格的方法难以适应不同场景的感兴趣区域,存在表达和计算冗余。本文提出以物体为中心的3D表达,每个单位描述一个感兴趣区,而非固定的网格。每个场景由一组3D语义高斯表达,每个高斯包括均值、协方差和语义logit。对特定3D位置的占用预测可通过该处所有语义高斯求和得到。
具体来说,本文为每个场景使用
P
P
P个3D高斯
G
=
{
G
i
∈
R
d
∣
i
=
1
,
⋯
,
P
}
G=\{G_i\in\mathbb R^d|i=1,\cdots,P\}
G={Gi∈Rd∣i=1,⋯,P},每个3D高斯由
d
=
10
+
∣
C
∣
d=10+|\mathbb C|
d=10+∣C∣维的向量表达,包括3维均值
m
m
m、3维尺度
s
s
s,4维旋转向量
r
r
r和
∣
C
∣
|\mathbb C|
∣C∣维语义logit
c
c
c。则给定位置
p
=
(
x
,
y
,
z
)
p=(x,y,z)
p=(x,y,z)处的语义高斯
g
g
g的值为:
g
(
p
;
m
,
s
,
r
,
c
)
=
exp
(
−
1
2
(
p
−
m
)
T
Σ
−
1
(
p
−
m
)
)
c
Σ
=
R
S
S
T
R
T
,
S
=
d
i
a
g
(
s
)
,
R
=
q
2
r
(
r
)
g(p;m,s,r,c)=\exp(-\frac12(p-m)^T\Sigma^{-1}(p-m))c\\ \Sigma=RSS^TR^T,S=diag(s),R=q2r(r)
g(p;m,s,r,c)=exp(−21(p−m)TΣ−1(p−m))cΣ=RSSTRT,S=diag(s),R=q2r(r)
其中
Σ
\Sigma
Σ和
q
2
r
(
⋅
)
q2r(\cdot)
q2r(⋅)分别表示协方差矩阵和四元数转旋转矩阵的函数。
p
p
p处的占用预测结果可表达为位置
p
p
p处所有高斯之和:
o
^
(
p
;
G
)
=
∑
i
=
1
P
g
i
(
p
;
m
i
,
s
i
,
r
i
,
c
i
)
=
∑
i
=
1
P
exp
(
−
1
2
(
p
−
m
i
)
T
Σ
i
−
1
(
p
−
m
i
)
)
c
i
(1)
\hat o(p;G)=\sum_{i=1}^Pg_i(p;m_i,s_i,r_i,c_i)=\sum_{i=1}^P\exp(-\frac12(p-m_i)^T\Sigma_i^{-1}(p-m_i))c_i\tag{1}
o^(p;G)=i=1∑Pgi(p;mi,si,ri,ci)=i=1∑Pexp(−21(p−mi)TΣi−1(p−mi))ci(1)
和体素表达相比,3D高斯可根据物体大小和区域复杂度自适应地分配计算和存储资源。此外,从具有显式语义的3D高斯转换到占用预测比体素方法中高维向量的解码更加简单。
2. GaussianFormer:图像到高斯
首先初始化3D高斯属性和对应的高维查询为可学习向量,然后迭代地在GaussianFormer内细化高斯属性。GaussianFormer的每个块包含自编码模块(3D高斯之间的交互)、图像交叉注意力模块(聚合视觉信息)和细化模块(修正3D高斯属性)。

高斯属性和查询:高斯属性
G
=
{
G
i
∈
R
d
∣
i
=
1
,
⋯
,
P
}
G=\{G_i\in\mathbb R^d|i=1,\cdots,P\}
G={Gi∈Rd∣i=1,⋯,P}是物理属性,也是模型的学习目标。高斯查询
Q
=
{
Q
i
∈
R
m
∣
i
=
1
,
⋯
,
P
}
Q=\{Q_i\in\mathbb R^m|i=1,\cdots,P\}
Q={Qi∈Rm∣i=1,⋯,P}是高维特征向量,在自编码和图像交叉注意力模块中隐式地编码3D信息,并为细化模块提供修正指导。
与3DGS不同,本文方法生成的高斯数量是固定的。
自编码模块:本文将高斯视为位于其中心 m m m的点,并体素化点云,使用3D稀疏卷积进行自编码。
图像交叉注意力(ICA)模块:对3D高斯G,首先生成3D参考点集
R
=
{
m
+
Δ
m
i
∣
i
=
1
,
⋯
,
R
}
R=\{m+\Delta m_i|i=1,\cdots,R\}
R={m+Δmi∣i=1,⋯,R},其中偏移量
Δ
m
\Delta m
Δm由高斯协方差计算,以反映高斯形状。然后使用相机内外参
T
,
K
T,K
T,K,将3D参考点投影到图像上,并根据图像特征的加权和更新高斯查询Q:
I
C
A
(
R
,
Q
,
F
;
T
,
K
)
=
1
N
∑
n
=
1
N
∑
i
=
1
R
D
A
(
Q
,
π
(
R
;
T
,
K
)
,
F
n
)
ICA(R,Q,F;T,K)=\frac1N\sum_{n=1}^N\sum_{i=1}^RDA(Q,\pi(R;T,K),F_n)
ICA(R,Q,F;T,K)=N1n=1∑Ni=1∑RDA(Q,π(R;T,K),Fn)
其中 F , D A ( ⋅ ) , π ( ⋅ ) F,DA(\cdot),\pi(\cdot) F,DA(⋅),π(⋅)分别表示图像特征图、可变形注意力函数和世界坐标系到像素坐标系的变换。
细化模块:利用高斯查询指导修正高斯属性。对高斯G,首先用MLP从高斯查询
Q
=
(
m
,
s
,
r
,
c
)
Q=(m,s,r,c)
Q=(m,s,r,c)解码中间属性
G
^
=
(
m
^
,
s
^
,
r
^
,
c
^
)
\hat G=(\hat m,\hat s,\hat r,\hat c)
G^=(m^,s^,r^,c^),其中
m
^
\hat m
m^作为残差与
m
m
m相加,而
s
^
,
r
^
,
c
^
\hat s,\hat r,\hat c
s^,r^,c^则直接替换原来的
s
,
r
,
c
s,r,c
s,r,c:
G
^
=
(
m
^
,
s
^
,
r
^
,
c
^
)
=
M
L
P
(
Q
)
,
G
n
e
w
=
(
m
+
m
^
,
s
^
,
r
^
,
c
^
)
\hat G=(\hat m,\hat s,\hat r,\hat c)=MLP(Q),G_{new}=(m+\hat m,\hat s,\hat r,\hat c)
G^=(m^,s^,r^,c^)=MLP(Q),Gnew=(m+m^,s^,r^,c^)
3. 高斯到体素的溅射
根据式(1)计算占用是耗时的,因此本文仅对体素邻域内的高斯进行加权求和。

如图所示,首先根据均值
m
m
m,将3D高斯嵌入
X
×
Y
×
Z
X\times Y\times Z
X×Y×Z的目标体素网格,并根据尺度
s
s
s计算邻域半径。将高斯的索引和邻域内所有体素的索引
(
g
,
v
)
(g,v)
(g,v)加入列表,并根据体素索引排序:
s
o
r
t
v
o
x
(
[
(
g
,
v
g
1
)
,
⋯
,
(
g
,
v
g
k
)
]
g
=
1
P
)
=
[
(
g
v
1
,
v
)
,
⋯
,
(
g
v
l
,
v
)
]
v
=
1
X
Y
Z
sort_{vox}([(g,v_{g_1}),\cdots,(g,v_{g_k})]_{g=1}^P)=[(g_{v_1},v),\cdots,(g_{v_l},v)]_{v=1}^{XYZ}
sortvox([(g,vg1),⋯,(g,vgk)]g=1P)=[(gv1,v),⋯,(gvl,v)]v=1XYZ
其中
k
,
l
k,l
k,l分别表示高斯的邻域体素数和体素的对应高斯数。最后,使用邻域高斯近似式(1):
o
^
(
p
;
G
)
=
∑
i
∈
N
(
p
)
g
i
(
p
;
m
i
,
s
i
,
r
i
,
c
i
)
\hat o(p;G)=\sum_{i\in\mathcal N(p)}g_i(p;m_i,s_i,r_i,c_i)
o^(p;G)=i∈N(p)∑gi(p;mi,si,ri,ci)
其中 N ( p ) \mathcal N(p) N(p)为体素 p p p的邻域高斯集合。可使用CUDA编程实现加速。
GaussianFormer可端到端训练。类似TPVFormer,使用交叉熵损失 L c e L_{ce} Lce和lovasz-softmax损失 L l o v L_{lov} Llov。每个细化模块的输出处均添加监督,以实现迭代细化。总损失为 L = ∑ i = 1 B ( L c e i + L l o v i ) L=\sum_{i=1}^B(L_{ce}^i+L_{lov}^i) L=∑i=1B(Lcei+Llovi)。
实施细节:使用4个Transformer块;对图像使用随机翻转和光度增广。


















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











